Archive for December, 2021
Etymological family trees
Posted by Angela Brett in News on December 30, 2021
A while ago I found a post about Surprising shared word etymologies, where the author had found words with common origins (according to Etymological Wordnet) which had the most dissimilar meanings (according to GloVe: Global Vectors for Word Representation.) I loved the post, but my main takeaway from it was the The History of English Podcast, linked in the Further reading section. I immediately started listening to that, in reverse order (that’s just the easiest thing to do in the Apple Podcasts app. Back when podcasts were in iTunes, I used to listen to all my podcasts on shuffle, so if you like order, this is an improvement) starting from Episode 148. I’ve since finished it and started listening to something else before I go back for the newer episodes. I was in it for the English, but I also learnt lot more history than I expected to.
The diagrams
Back in October, hearing about how yet another absurd list of words all derived from the same root word (I think in this case it was bloom, flower, phallus, bollocks, belly, flatulence, bloat, fluid, bladder, blow, and blood from episode 62) I decided I couldn’t just listen to these ridiculous linguistic family trees any more; I had to see them. As you might have seen in previous posts, my go-to for creating that kind of diagram is using AppleScript to control OmniGraffle. So I wrote an AppleScript to make tree diagrams showing words that are all derived from the same root word(s) as a given word. Before I bore you with the details, I’ll show you a little example. This is what it gave when I asked for the English word ‘little’.

The root word is in a blue oval, the words in the same language as the one I asked about (in this case, English) are in brown rounded rectangles, and the words in other languages are in black rectangles. I thought about having a different colour and shape for each language, and a legend, but decided to keep things simple for now.
Image descriptions
The script also generates a simple image description, which I’ve used in the caption. I intended it for use as alt text, but some of these diagrams are difficult to read at the size shown, so even people who don’t use screen readers can benefit from the description. You can also click on any diagram for a full-sized pdf version.
It doesn’t describe the entire structure of the tree (I’m trying not to get distracted researching nice ways to do that for arbitrary trees!) but it’s probably better than nothing. It only lists the words in the language you asked about (assuming that is English), since English screen readers likely wouldn’t read the other ones correctly anyway. It might be cool to autogenerate sound files using text-to-speech in voices made for the other languages and attach those to the nodes to enrich the experience when navigating through them in OmniGraffle or some other format it can export, but that’s a project for another day.
On the subject of accessibility, I’m happy that the History of English Podcast provides transcripts, so I can easily find the episodes relevant to some of these diagrams.
Simplifying the diagrams
Sometimes the diagrams get crowded when a lot of words are derived from another word in the same language, or a lot of other languages derived words from the same word. I wrote a second script to group words into a single node if they’re all derived from the same word, don’t have any words derived from them, and are all in the same kind of shape as the word they’re derived from. That last constraint means that if you searched for an English word, English words all derived from the same English word will be grouped together, and non-English words all derived from the same non-English word will be grouped together, but English words derived from a non-English word (or vice versa) are not, because I think they are more interesting and less obvious.
It’s actually quite satisfying to watch this script at work, as it deletes extra nodes and puts the text into a single node, so I made a screen recording of it doing this to the diagram of the English word ‘pianoforte’. I’m almost tempted to add pleasant whooshing sound effects as it sweeps through removing nodes.
The data
Words and their etymologies
The data from Etymological Wordnet comes as a tab-separated-values file. AppleScript is best at telling other applications what to do, not doing complicated things itself, so I left all the tsv parsing up to Numbers, and had my script communicate with Numbers to get the data. The full data has too many rows for Numbers to handle, but I only needed the rows with the type rel:etymology, so I created a file with just those rows using this command:
grep 'rel:etymology' etymwn.tsv > etymology.tsv
then opened the resulting etymology.tsv file in Numbers, and saved it as a numbers file. This means missing out of a few etymological links (some of which are mentioned below), but it’s good enough for most words.
The file simply relates words to the words in the first column to words they are derived from in the third column.
Languages
Each word is listed with a language abbreviation, a colon, then the word. The readme that comes with the Etymological Wordnet data says, ‘Words are given with ISO 639-3 codes (additionally, there are some ISO 639-2 codes prefixed with “p_” to indicate proto-languages).’ However, I found that not all of the protolanguage codes used were in ISO 639-2, so I ended up using ISO 639-5 data for protolanguages and ISO 639-3 data for the other languages, both converted to Numbers files and accessed the same way as the etymology data.
The algorithm
The script starts by finding the ultimate root word(s) of whatever word you entered. It finds the word each word is immediately derived from, then finds the word that was derived from, and so on, until it gets to a word that doesn’t have any further origin. Some words have multiple origins, either because they’re compound words, homographs, or just were influenced by multiple words, so sometimes the script ends up with several ultimate root words. This part of the script ignores origins that have hyphens in them, because they’re likely common prefixes or suffixes, and if you’re looking up ‘coagulate’, you’re unlikely to want every single word derived from a Latin word with a prefix ‘co-‘.
For each of the root words, the script finds all words derived from it, and all words derived from those, and so on, and adds them to the diagram.
The code
In case you want to try making your own trees, I’ve put the AppleScripts and the Numbers sheets used for this in a git repository. It turns out having the version history is not terribly useful without tools to diff AppleScript, which is not plain text. It is possible to save AppleScript as plain text, but I didn’t do that in the beginning, so the existing version history is not so useful. It looks like AS Source Diff could help.
There are a lot of frustrating things about AppleScript when you’re used to using more modern programming languages. Sometimes that’s part of the fun, and sometimes it’s part of the not-fun.
Trees from Surprising Shared Etymologies
I tried making diagrams of some of the interesting related words mentioned in The History of English Podcast, such as the one with flower, bollocks, phallus and blood mentioned earlier, but the data usually didn’t go back that far. So I tried the ones mentioned in the Surprising shared etymologies post, because I knew they were found in the same data. In several cases I found the links didn’t actually hold up, as the words were descended from unrelated homonyms. I’ve done my best to figure out which parts of these trees are correct, but can’t guarantee I got everything right, so take this information with a grain of research.
“piano” & “plainclothed”
This was a bit of a puzzle, because there is actually no origin given in the data for English word ‘piano’, although it is given as the origin of many words in other languages. But their example in the ‘datasets’ section shows English: pianoforte, so I used that instead.
I could have added a row to the spreadsheet linking English ‘pianoforte’ with English ‘piano’, and then the many words in other languages that derive from English ‘piano’ would have shown in the diagram as well. Click on the diagram for a pdf version.

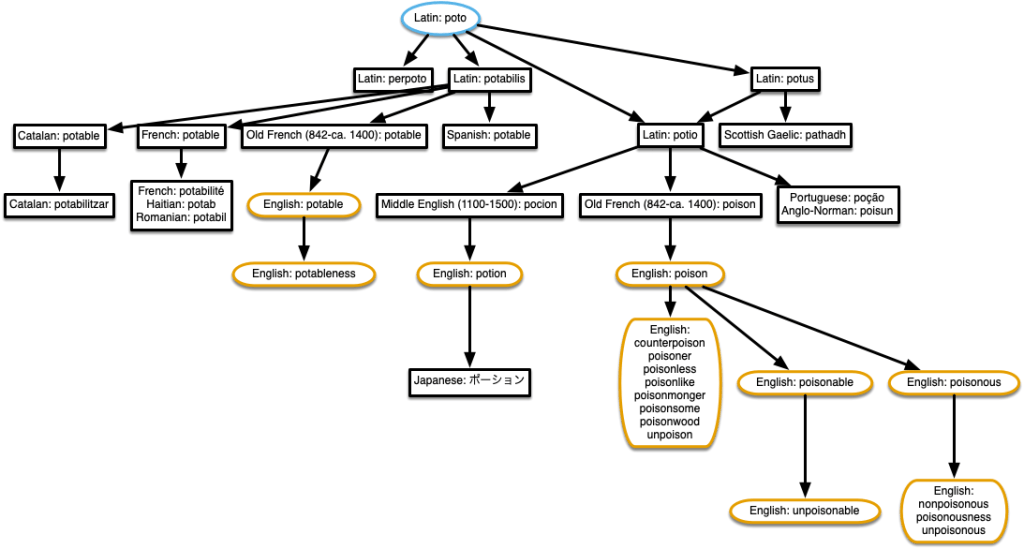
“potable” & “poison”
Also potion! According to the data, Latin potio is derived both from Latin poto, and from Latin potus, which is itself derived from Latin poto. The word is its own niece! I had to make a change to the script to ensure there wouldn’t be double connections in this case.
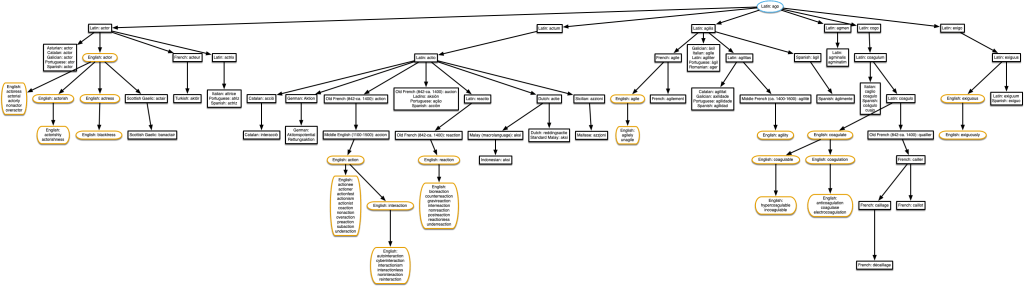
“actor” & “coagulate”
Agile and exiguous, too! It’s starting to get a bit complicated.
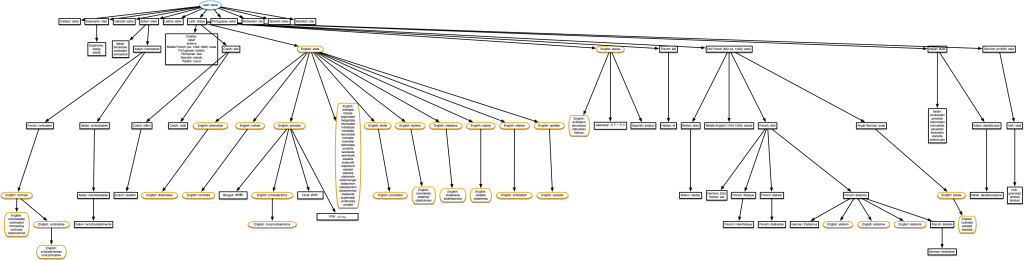
“estate” & “contrast”
This tree also includes ‘prostate’, but only ‘pro-state’ (meaning favouring the government) derives from English ‘state’ as shown here. Prostate the body part is actually related, but only if we go back to the Proto-Indo-European root *sta-, which is not in the Etymological Wordnet data. Since the data doesn’t distinguish between the two meanings of ‘prostate’, this tree erroneously includes prostatectomy and cryoprostatectomy, a procedure I was happier not knowing about.
If you think it’s surprising that ‘estate’ and ‘contrast’ are related, have a look at other words derived from *sta-. Understand, obstetrics, Taurus, Kazakhstan… if Etymological Wordnet had that data, this tree would resemble Pando.
“pay” & “peace”
This one comes up in episode 59 of the podcast — the word ‘pay’ literally meant ‘make peace’. It’s not too hard to imagine how paying someone would pacify them. The diagram is incorrect though. ‘Peace’ is shown as being derived from Middle English pece. This is actually the source of ‘piece’, but not ‘peace’. As far as I can tell, pece (and therefore also ‘piece’) shouldn’t even be in this tree. The word ‘peace’ is derived from Middle English pees, near the middle of the diagram, so it is still related to ‘pay’.

“cancer” & “cancel” & “chancellor”
As explained in episode 99 of The History of English Podcast, chancellor is just the Parisian French version of the Norman French canceler. The word ‘cancel’ didn’t come from ‘canceler’, though — ‘cancel’ and ‘chancellor’ both come from a word meaning lattice, whether the lattice a chancellor stands behind, or that of crossing something out to cancel it. The same word also give rise to ‘incarcerate’, but that link is not in the data.
As far as I can tell, these are not actually related to the English word ‘cancer’, though. There are two unrelated Latin words ‘cancer’, one meaning ‘lattice’, and the other meaning ‘crab’, and thus crab-like cancer tumours.

“fantastic” & “phenotype”
This also shows that ‘craptastic’ is related to ‘phasor’. Sometimes the best things about these are the lists of derivative slang words.

“college” & “legalize”
Also ‘cull’, ‘legend’, and ‘colleague’.
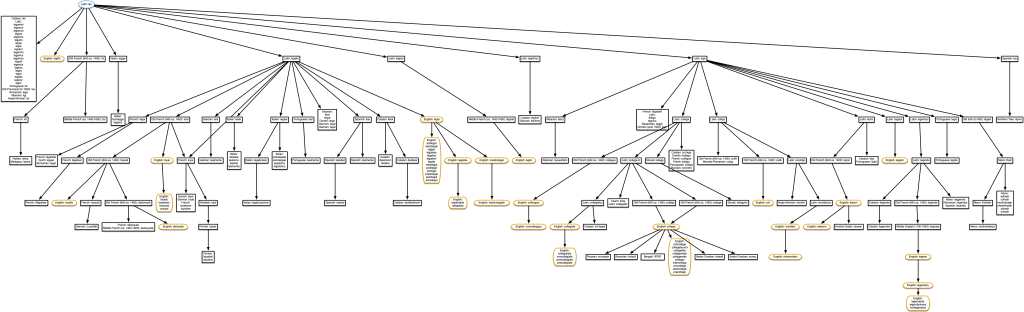
“lien” & “ligament”
‘Cull’ should not be in this diagram, as it’s related to a different homonym of Latin colligo. See the ‘Limitations‘ section below.

“journal” & “journey”
Surprising shared word etymologies says:
While it seems like “journal” and “journey” should be close cousins, their nearest common ancestor is in fact quite old – the Latin “diurnus”, meaning “daily”.
This seems about right from the data, and I’m surprised they didn’t both come from the Old French jor. My dictionary of French etymology doesn’t list the French versions of either word.

This is the tree I get if I start from the word ‘journal’. If I start with ‘journey’, it shows that Latin diurnum is also given as an origin of Old French jor, but this adds a lot of complication to the tree and only one extra English word, ‘abatjour’.
“educate” & “subdue”
I’m not sure how they got these two, to be honest. They may indeed be related, if, as etymonline says, subdue came from the same root as subduce, and subduce and educate came from Proto-Indo-European *deuk- (or *dewk-, as wiktionary spells it). There’s a lot about other words from that root (not including ‘subdue’) in episode 85 of the podcast.
I don’t know how they got this from the Etymological Wordnet data, though. Etymological Wordnet was extracted from an older version of wiktionary, and it doesn’t have very many Proto-Indo-European roots. The post says that ‘subdue’ comes from the latin subduco, meaning ‘lead under’. But even looking at all the data (not just the rows with ‘rel:etymology‘), ‘subdue’ is only linked to other English words. Perhaps they were looking at ‘subduce’ instead.
The post also says they both come from Latin duco. If I look at all the data, I can get to Latin duco from ‘educate’ (via Latin educatio and educo.) But looking more closely at that link on wiktionary (the source of Etymological Wordnet’s data) it seems there are two meanings of Latin educo, one coming from Latin duco and one coming from Latin dux, and it’s the dux origin that seems more relevant to education. However Proto-Indo-European *deuk- is the hypothetical source of dux, so that’s how it relates to subdue.
I’m getting a bit lost following these words around wiktionary and etymonline. I believe they’re related, but I’m not sure if they’re related via Latin duco, and I haven’t a clue how the relationship was found in the Etymological Wordnet data (I should probably read and/or run their ruby code to find out), so I can’t generate even an erroneous family tree of it.
Limitations
Did you notice that the word ‘cull’ shows up in both the tree for ‘college’ and the one for ‘ligament’? Does that mean that ‘ligament’ is also related to ‘college’? Nope. The issue here is that the Latin colligo has two distinct meanings with different origins, one via Latin ligo, and one via Latin lego. ‘cull’ derives from the ‘bring together’ meaning of colligo, which derives from lego, so it’s actually not related to ‘ligament’. Only one origin for colligo is shown on each of these two trees, since neither ‘college’ nor ‘ligament’ are derived from colligo, so the script only got to colligo when coming down from one of the ultimate root words, rather than when going up from the search word. But if we create a tree starting with the word ‘cull’, it gets both origins and the resulting tree makes it look like ‘college’ and ‘ligament’ are related.
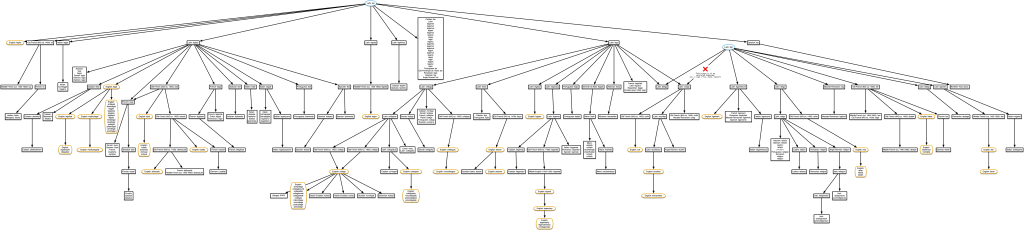
Since the data only has plain text for each word, there’s no way for the script to know for sure that colligo isn’t one word with multiple origins (like ‘fireside’ is), but actually two separate words with different origins. And there’s no way for it to know which origin for colligo happens to be the one that ultimately gave rise to ‘cull’.
A trivial example
I’ll leave you with a tree I found while looking for a trivial example to show at the beginning. Here’s the tree for ‘trivial’. There are many more related words given in episode 37 of The History of English Podcast.
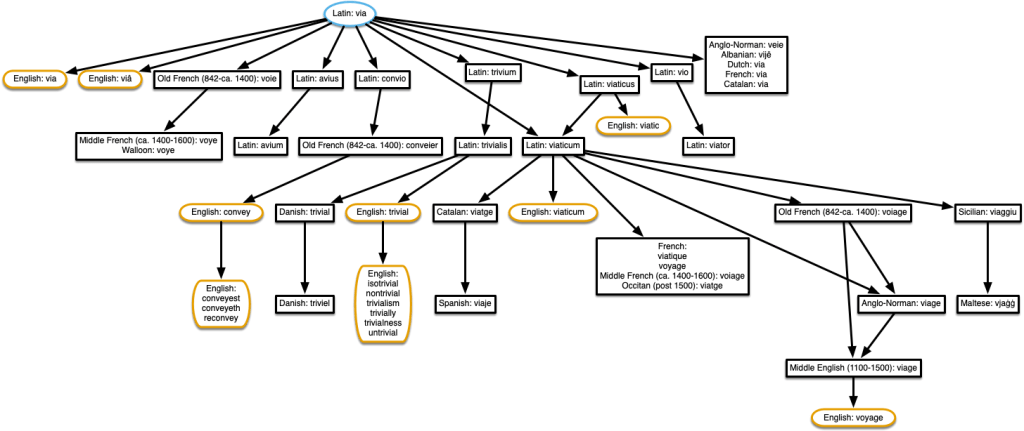
-
You are currently browsing the archives for December, 2021

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported License.
Please tell me if you do something cool with it.

