Posts Tagged programming
Arithmancy Pants for macOS and iOS: Because everything’s a magic number if you’re brave enough
Posted by Angela Brett in My Software on October 31, 2025
TL;DR: I made an app to derive a lot of ‘lucky’ numbers from any text. You can get it on the App Store now, for iOS and macOS.
Many years ago I came across Uri Geller’s page about how he notices the number 11 a lot and it’s somehow a magic number. I didn’t read all of it, because it’s nonsense, but I was intrigued by the list of ‘Names, events and places that add up to 11 letters.’ It contains:

- Many words, names, and phrases that happen to have 11 letters
- The words ‘hell heaven’ that sound a bit like 11
- Events that happened on the 11th of some month, or in November, or at 11:11
- The fact that Queen Elizabeth II is often written EIIR, which looks like E11R (of course, if you know Roman numerals, it clearly means E2R, but when I was a little kid I thought the Commodore 64 game Saboteur II was Saboteur 11, so I shouldn’t judge)
- Numbers whose digits add up to 11, if you keep adding the digits of the result until you get to 11
- Dates whose digits add up to 22, if you keep adding the digits of the result until you get to 22
- Phrases that have two consecutive As in them (because A is the first letter of the alphabet)
- Numbers that have two or more consecutive 1s in them
- Numbers that have two or more non-consecutive 1s in them, separated by zeroes
- Numbers that have 2 in them
It was clear to me that if you look hard enough, you can find 11s anywhere. Not only that, but you could find whatever other smallish (under 1000 or so) numbers you’re looking for. So I wrote code to look for a lot of these things automatically, and put it in an iOS and macOS app called Arithmancy Pants. It’s called that because ‘Numerologist’ was taken, arithmancy is an older word for numerology, and I’m a two-time Fancy Pants Parade winner.
I broke down everything into independent steps, so that we can find as many numbers as possible without doing the same thing twice — for instance, instead of converting AA to 11, we first convert it to 1, 1, and then concatenate them in a separate step to make 11.
Here are the things Arithmancy Pants can do in its quest to find numbers:
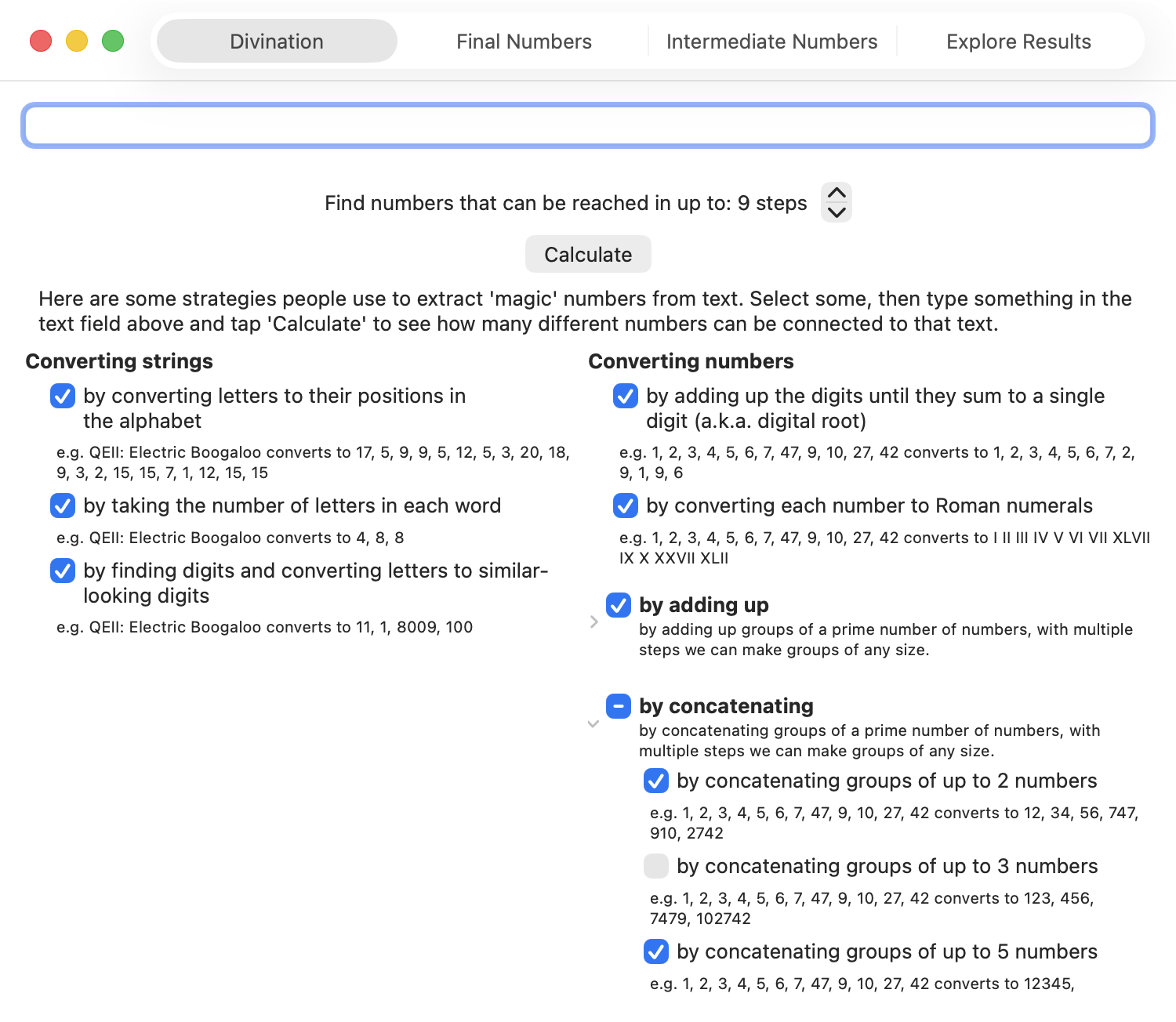
- Convert text into numbers
- by converting letters to their positions in the alphabet — Uri only uses this one for converting A to 1, but I’ve seen it quite often elsewhere
- by taking the number of letters in each word — this covers all the 11-letter words, and when combined with ‘adding up all the numbers’, covers other names and phrases with 11 total letters.
- by finding numbers that are already in the text, and letters that look like numbers — this covers the EIIR example.
- Convert numbers into other numbers
- By adding up the digits until they sum to a single digit (also known as digital root, this is equivalent to finding the remainder when dividing the number by 9, except using 9 instead of 0 unless we started at 0.)
- By converting each number into Roman Numerals — I think I only added this because I’d already written code to do that for something else. However, this covers the ‘numbers that have 2 in them’ case, as we can convert 2 to 11 by converting it first to II, and then to 11 by converting letters that look like numbers. This is a much more manageable way of turning 2 to 11 than adding a generic ‘convert each number into every possible combination of numbers that add to that number’ step.
- By adding up numbers
- Adding up all the numbers — this covers most of the adding-up cases on Uri’s page
- Adding up numbers in groups of up to 2, 3, 5, 7, and 11 numbers. By using prime-sized groups, in multiple steps we can add the numbers in groups of any size — e.g., we can add up groups of 6 numbers by first adding groups of 3 numbers, then adding those results in groups of 2.
- By concatenating numbers — combined with converting letters to their positions in the alphabet, this covers converting AA to 11
- Concatenating all the numbers
- Concatenating numbers in groups of up to 2, 3, 5, 7, and 11 numbers.
I stop at combining groups of 11, because while I could handle even larger numbers internally by using a different data type:
- I’ve got to stop somewhere, and not many people’s supposed lucky numbers have enough digits for concatenations or sums of multiples of 13 numbers to matter.
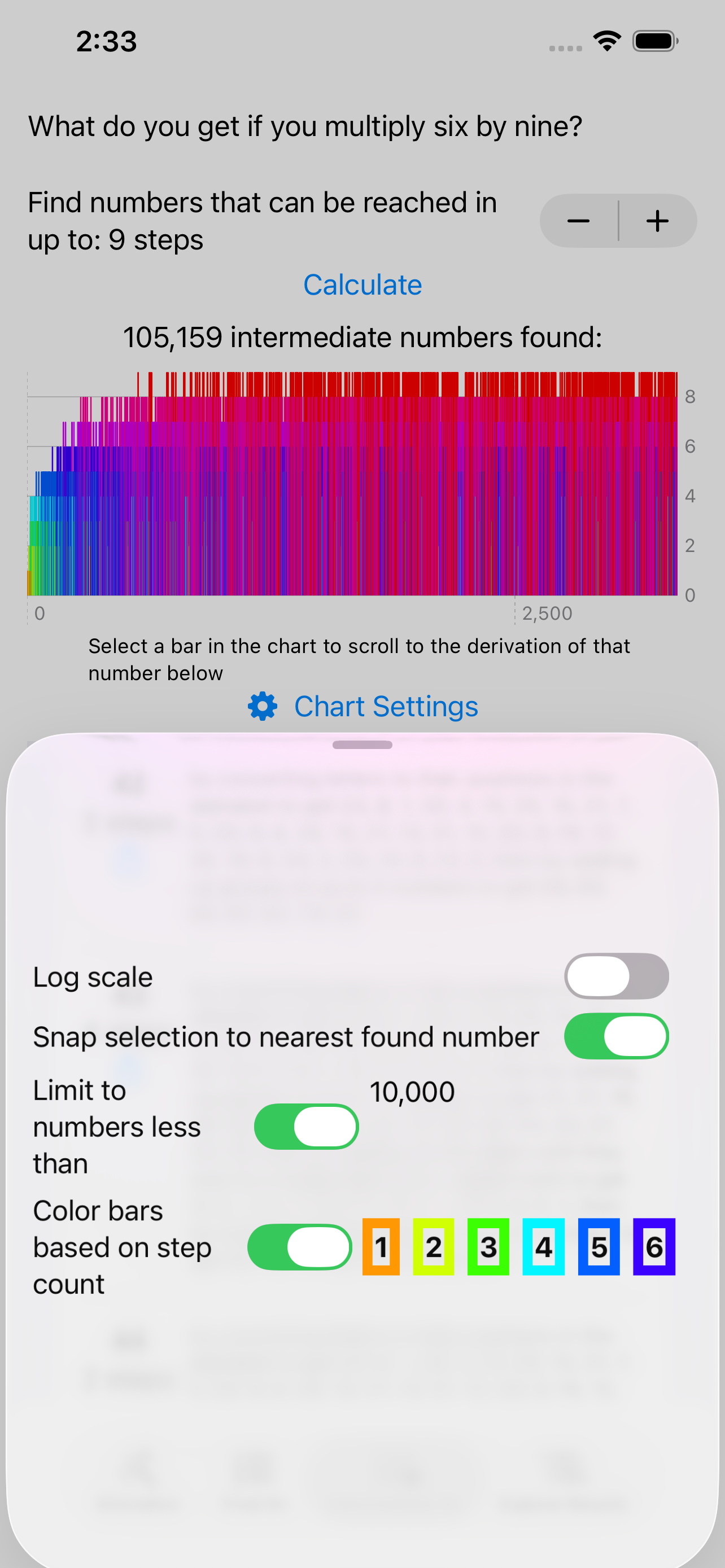
- I show charts of the numbers found, and there seems to be a bug (FB20491693, if you’re at Apple) in Swift Charts when I include more than one result that would convert to the same
Doublevalue. So I’m limited to final numbers under 253. - 13 is an supposedly an unlucky number anyway.
The app shows the final numbers you get when you complete enough of these steps to get down to a single number. On another tab it shows the intermediate numbers found alongside other numbers partway through the process. You can also explore the results yourself by expanding each intermediate result to see what was derived from it in the next step.
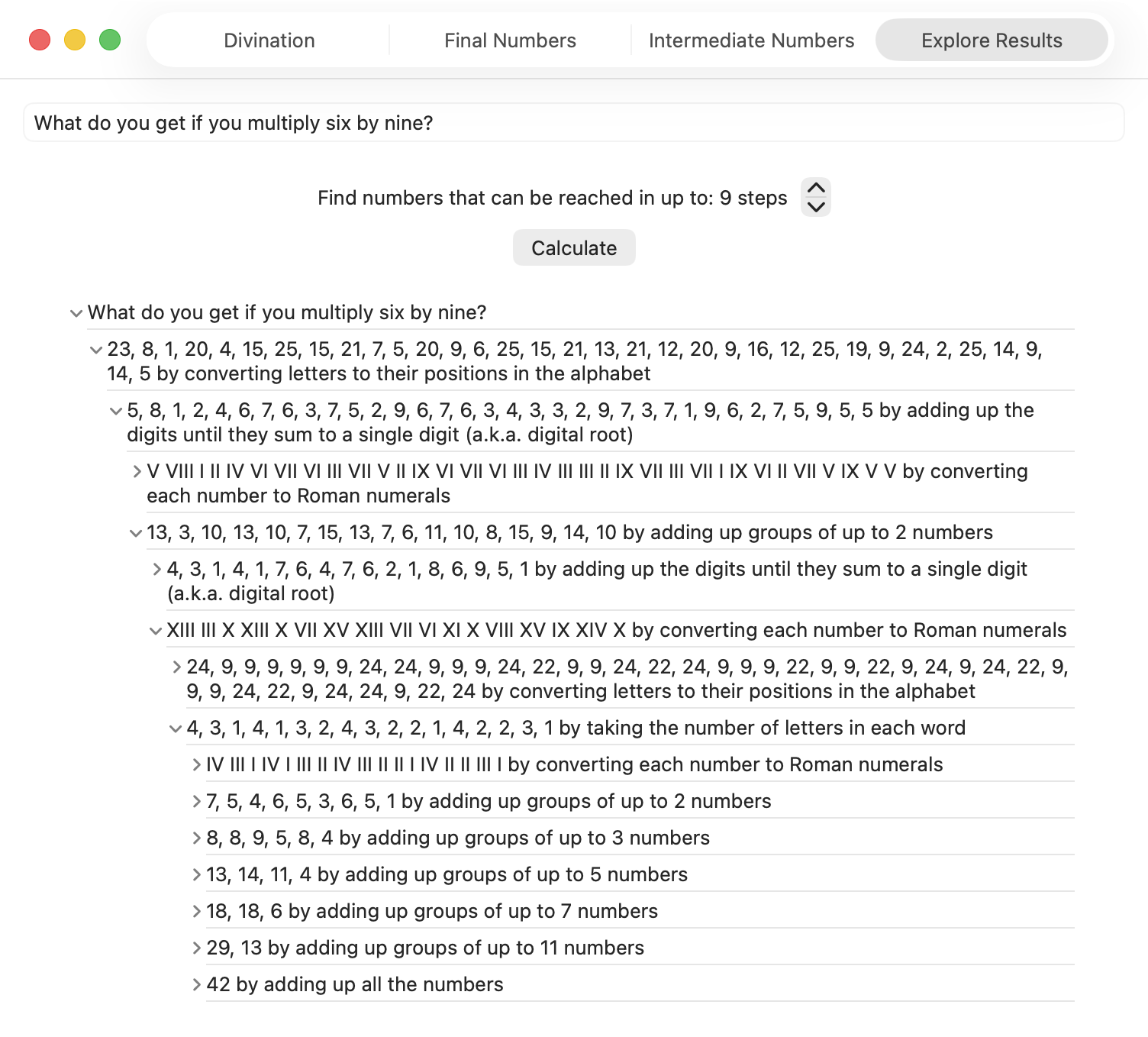
Note, there were many years between when I saw that page and when I actually wrote the app. So I don’t cover:
- Words that sound like numbers. I could have easily done something like this, at least on macOS, as I have a lot of experience with the text-to-speech APIs, but I simply forgot that was one of the tactics. Actually, I would probably just have a list of known words (too, to, for, non-rhotic Severn, etc.) that sound like numbers, or perhaps I would derive such a list by searching through a lot of text using the text-to-speech API. Uri’s suggestion of ‘hellheaven’ would not have come up though, since it doesn’t actually sound like eleven.
- Numbers that have consecutive or non-consecutive ones in them… although, this depends on how we got the numbers. If we obtained 10001 by concatenating 10, 0, 0, and 1, we would also have added those numbers to get 11.
- Stopping halfway when calculating the digital root — e.g., adding up the digits of 254 to get 11, but not continuing to add up the digits in 11 to get 2. I just take the remainder when dividing by nine to do the whole thing in a single step, so this won’t even be shown in the intermediate values.
I think that’s all I have to say about that… as I mentioned in my last post, this could also be a MathsJam talk some day. You can download the app for free on any device running macOS 26 or iOS 26. You could use it to debunk the claims of numerologists, or to make your own claims for fun — but please don’t use it to take advantage of gullible people.
Seddit 1.5 supports multilingual Reddit listening. Also, Joey sang my half-baked PSOLA song!
Posted by Angela Brett in My Software on October 9, 2025
A while ago I added the possibility to configure Seddit (my text-to-speech-focused hands-free Reddit client for macOS and iOS) with multiple voices so that each user’s content could be read in a different voice. Of course, iOS and macOS come with voices that speak a huge variety of different languages, so you could theoretically select, say, a Japanese voice, a French voice, and three English voices, and download Reddit posts and comments in all of those languages. However, until now, Seddit would randomly assign a voice to each user, without regard for the language that user had written in, so if you did that, you could end up with English posts pronounced as if they were French, Japanese character names read out in English, and so on.
In the latest version, if you select voices that speak multiple languages in the Voices tab of the Settings screen, when Seddit encounters a post or comment by a user it hasn’t chosen a voice for yet, it will detect which of those languages the post or comment is probably in, and choose a voice that knows how to pronounce that language.
Of course, this isn’t perfect — it still always uses the same voice for each user, so if a user sometimes posts in French, and sometimes in English, or if they write in multiple languages within a single post because it’s a language-learning subreddit, then some of that is going to be spoken using an inappropriate voice. Also, if someone only writes in English but the first comment that Seddit encounters of theirs is an image meme and the text ‘c’est la vie!’ Seddit might determine that the user speaks French, and then hilariously mispronounce the rest of their posts. Note, if there is not enough text in the user’s first post for Seddit to even guess the language, it will not definitively choose a voice for that user until it encounters another post by them. I have yet to find either of these situations in practice, even while looking for them, so I hope it’s a rare issue.

Nonetheless, all of these situations are better than Seddit just randomly picking a voice for each user, regardless of which language they happen to be writing in. You should try it out, especially if you want to listen to Reddit content in various languages!
I also redesigned the Settings screen on iOS and iPadOS so it’s fullscreen and has a close button in the top right, as per Apple’s human interface guidelines, instead of a ‘Done’ button taking up a lot of space at the bottom and making the tabs look weird.
Note, while writing this post, I tested the regular ‘Start Speaking’ menu command on macOS and the ‘Speak’ command on iOS and found that it will sometimes switch to appropriate voices if I select multilingual text, even if my System Speech Language est réglé sur えい語。 Okay, it doesn’t work well for the French/English parts of that sentence. Maybe it’s only good with switching between languages if I switch scripts, e.g. בַּרְוָזָן утконос カモノハシ. Yep, that works, although if I select any other text along with πλατύπους, it’ll read it as ‘Greek small letter pi’ etc. I guess Greek letters are used too often in English for the speech engine to assume we actually switched to Greek. There were certainly plenty of Greek letters in the Princeton Companion to Mathematics.
Anyhow, I’m thinking I could improve Seddit further by giving each user a voice in each language you’ve selected voices for, and detecting the language for each post/comment, or for each sentence. Though macOS doesn’t do that unless you switch scripts… when I tried adding ‘J’imagine qu’il choisit une nouvelle langue pour chaque phrase.’ as a separate sentence and selected it along with a few English sentences, it read the whole thing in a French voice.
On the subject of interesting text-to-speech behaviour, and interesting behaviour in general, remember my half-written Lola parody about Pitch Synchronous Overlap and Add? Well, the lovely Joey Marianer had an appointment in town a while ago, and sneakily recorded the song in a parking building as a surprise, because I’m usually home so there’s little chance to record things at home without my hearing. I was duly surprised and delighted. Even the disclaimer about the missing bridge sounds like it scans as a bridge! Now you can also be surprised, delighted, and probably confused as to why this half-baked song was considered worth singing.
James Webb Space Telescope (now actually sung) and Seddit 1.4
Posted by Angela Brett in My Software, video on September 26, 2025
In my last post I gave lyrics to a parody of an Arrogant Worms song about the James Webb Space Telescope, and an update to my text-to-speech focussed Reddit client Seddit. I also said two things that turned out to be false:
- Joey and I will probably sing this parody, but it will take more mixing and video editing than our usual songs.
- This completes all the major features I have planned the app — I have other ideas for improvement, but I don’t think they’re essential. I’m hoping that the next update will be simply to remove the text saying I’m looking for a job.
Well, the other night Joey asked if I wanted to sing the song, and I said, “Okay! I should change into a more space-related shirt first” and then Joey produced two James Webb Space Telescope T-shirts out of nowhere, having secretly ordered them previously. So we changed into the shirts, and then we sang it, directly into a camera together, with no warmup or practice, and Joey trimmed the ends and put the video on YouTube. I had thought we’d sing our separate parts, get them perfect, then mix them, and make a video with some relevant educational images. Instead, here’s an imperfect but pretty good recording already!
I know where I made a mistake, but I’m not going to hang a lampshade on it so you’ll notice.
As for Seddit, well, not only did I not get the job I was hoping for when I wrote that, I also decided to update the app to use the new Liquid Glass design language that came out with iOS and macOS 26. I found and fixed a few other issues along the way. Here are the changes in Seddit 1.4:
- Features
- Added support for liquid glass appearance in iOS/macOS 26
- Moved playback controls to a liquid glass overlay so you can see more content around the edges
- Bug fixes
- Made sure compliments purchased on the Support Seddit screen are always shown in the same order
- Made the Voices Settings screen on macOS show which voices are Enhanced or Premium (I also filed bug FB20362911 with Apple about this, because there’s some system behaviour that’s inconsistent between iOS and macOS)
- Fixed an issue introduced in Seddit 1.2 whereby posts whose comments are not all read would be shown as read instead of partly read
You can get the latest version for Mac, iPhone, or iPad on the relevant App Store.
On the subject of songs and liquid glass, check out this song by James Dempsey about liquid glass:
Thanks to Seattle Xcoders, I was lucky enough to have seen the live debut of this, and another performance of it, which I recorded but don’t have permission to share yet.
I haven’t actually had any legibility issues with liquid glass though — and if I did, I know I could always turn on Reduce Transparency.
James Webb Space Telescope (Arrogant Worms parody lyrics) and yet another Seddit update
Posted by Angela Brett in My Software on September 15, 2025
This is to be sung to the tune of Big Fat Road Manager, by The Arrogant Worms:
Giant rocket to the sky
Not many people really know why
It’s gotta stay cool as the stars parade
It’s got a gold coat and some doped ass-shades
It’s the James Webb Space Telescope
James Webb Space Telescope
James Webb Space Telescope
James Webb Space Telescope!
It beat a hurricane and lots of delays
(James Webb Space Telescope)
Refused to fail in three hundred ways
(James Webb Space Telescope)
It had a long time and a lot to do
(James Webb Space Telescope)
On its way to Lagrange point two
It’s the James Webb Space Telescope
James Webb Space Telescope
James Webb Space Telescope
James Webb Space Telescope
It found a new moon and some old black holes
(James Webb Space Telescope)
A planet circling a mate of Sol’s
(James Webb Space Telescope)
Its pictures show 8-pointed stars
(James Webb Space Telescope)
That’s how you can tell they are
From the James Webb Space Telescope
James Webb Space Telescope
James Webb Space Telescope
James Webb Space Telescope
You may wonder why the space telescope’s so far
That way it can block the heat from our Earth and Moon and Star
It sees through clouds in infrared
(James Webb Space Telescope)
Back through time as the wavelengths spread
(James Webb Space Telescope)
So far back that now it sees
(James Webb Space Telescope)
Light from earliest galaxies
As our James Webb Space Telescope
James Webb Space Telescope
James Webb Space Telescope
James Webb Space Telescope
It’s still our James Webb Space Telescope
James Webb Space Telescope
James Webb Space Telescope
James Webb Space Telescope
∎
Recently I remembered that I’d started writing this parody back when the James Webb Space Telescope launched. So I filled in some of the gaps, and then watched this excellent documentary about the telescope to fill in some more:
I found out about that documentary from NASA’s Curious Universe podcast, which I found out about from NASA’s Houston We Have a Podcast podcast. I recommend both, but especially the latter.
I considered saying it had ‘huge-ass shades’ as a reference to the ‘big fat ass’ in the original lyrics, but then I discovered that the sunshades were coated with doped silicon, and I couldn’t resist making a reference to the phrase ‘dope-ass’ while also doing the xkcd 37 thing. They are ‘ass shades’ in a sense, because they’re behind the telescope, i.e. on the side it’s not looking towards.
I’ve put links in the lyrics to some of the things where I could find a specific-enough link. The hurricane referred to is Hurricane Harvey, which hit Texas while the JWST was undergoing testing in a cryogenic vacuum chamber. As you’ll see in the documentary, it was a nail-biting time! The next line refers to the 344 potential single-point failures during launch and deployment which there wouldn’t have been a way to recover from. Really there were a lot of nail-biting times. But it all went well!
I linked to NASA’s explanation of Webb’s diffraction spikes, but I think this diagram from wikipedia also shows it very well.
Joey and I will probably sing this parody, but it will take more mixing and video editing than our usual songs. On the other hand, I can hear Joey singing it in the other room as I type this, so it might be ready fairly soon.
In other news, I’ve released version 1.3 of my text-to-speech-focussed reddit client for macOS and iOS, Seddit. Here’s what I changed:
- Added ‘Go to currently speaking item’ button in the toolbar, so you can quickly find the post or comment that’s currently being spoken, e.g. to open links or open the post in a browser to respond
- Enabled the ‘Settings…’ menu item and standard Settings window style on macOS
- Added headings and other changes for improved navigation of posts and comments using VoiceOver or Switch Control.
This completes all the major features I have planned the app — I have other ideas for improvement, but I don’t think they’re essential. I’m hoping that the next update will be simply to remove the text saying I’m looking for a job. 🤞🏻
So I leave my bags behind (Galilee Song parody lyrics) and a new version of Seddit
Posted by Angela Brett in My Software on August 19, 2025
Whoever else you believe is in the sky looking after you, you can be sure that the crew of any airliner you fly in are there to keep you safe. So here’s a parody of the hymn ‘The Galilee Song’ about surviving an emergency water landing. It’s based on the stories of Pan Am Flight 526A, Ethiopian Airlines Flight 961, and US Airways Flight 1549:
Both the right wing engines glitched, when a plane had barely climbed,
So the pilots deftly ditched; soon a rescue crew arrived.
Panicked flyers feared the sharks in the sea where they came down,
So instead of boarding rafts, some stayed in the plane to drown.
So I leave my bags behind
Leave through unfamiliar doors
Set my raft upon the deep
Pull my life vest inflate cord
Once some halfwits stormed a flight, made impossible demands,
So the captain who was bright, steered them stealthily toward land.
They came down just off a coast; those with life vests could be saved.
Some inflated theirs too soon, trapped inside that sinking plane.
So I leave my bags behind
Leave through unfamiliar doors
Only after I am free
Pull my life vest inflate cord
One plane struck a flock of birds; there was nought to do but glide.
Skiles and Sully, undeterred, ditched the plane and no-one died.
Though ’twas not an ocean flight, there were crucial vests and slides.
A stroke of luck that now we cite in the transport safety guides.
So I leave my bags behind
Leave through unfamiliar doors
Set my raft upon the deep
Pull my life vest inflate cord
So I leave my bags behind
Leave through unfamiliar doors
Only after I am free
Pull my life vest inflate cord
∎
After I posted the chorus of this along with my last aviation-themed parody, Joey made noises about potentially singing it if I wrote the rest, so that’s what I did. The chorus is very catchy, so I hope it reminds people what to do if they need it.
The original song has a strong enough tune that you barely notice that it has basically no rhymes, only a little assonance in the chorus. I couldn’t help putting in a bunch of rhymes though. Where’s the challenge, otherwise? The chorus still pretty much rhymes with the lines of the original chorus rather than with itself, though, which doesn’t make sense for anyone who doesn’t know the original, but is so very tempting for those who do, because the chorus is catchy enough to inspire faith… to the non-rhyme scheme.
So I add a bunch of rhymes
Fix the song’s familiar flaws
To absolve it of its [bleep]
Wait, that word was not untoward!

As I mentioned in my last post, I’m including a song parody each time I post about a minor update in an app I release. Well, I’ve released a new version of Seddit, my text-to-speech-focussed Reddit client for iOS and macOS. The new version has three new features, so it’s not such a minor update, really. Here’s what’s new:
Features
- Settings for sounds to play between posts and comments — now you have two options for the sounds to play when going up or down levels when reading comments. You can also choose to turn off the sounds played between posts or when going up or down comment levels.
- ‘Random from previous’ option when autoloading more posts, so it will automatically load posts from any of the subreddits you have previously loaded posts from, instead of just a specific one
- Option to say ‘Link’ instead of reading out URLs in posts and comments
Bug fixes
- Fix to a potential hang when autoloading posts
You can get the latest version of Seddit from the app store!
Rotation Speed (Sam Bettens parody lyrics) and a new version of Lifetiler
Posted by Angela Brett in My Software, News on August 14, 2025
This is a parody of Coasting Speed by Sam Bettens, because ever since I learnt the phrase ‘rotation speed’ from Mentour Pilot, I’ve had it in my head to the tune of Coasting Speed every time I’ve taken off (as a passenger) in an aeroplane. I’ve added a little to this parody with each flight. This is from the perspective of the flight crew and cabin crew, talking to the passengers.
The takeoff’s cleared
We’ve finally reached
rotation speed
We known we’re each
prepared for takeoff
and we start to fly
You board your flight
You stow your bags
Tray tables up
Do your belts up tight
We know you’re ready
As we get you high
But it’s not a rush
We take our time
your life
is in our hands
Ohhh
When the engine’s drowning out all other sound
When the landing just won’t stick, and we go around
We won’t let you, we won’t let you down
but we’ll get you down
At altitude
We are pressurised
We’ve got attitude
And you inside
So you’re breathing easy
When you’ve got to fly
But the flight goes on
And on and on
It might seem much too long
Ohhhh
When the engine’s drowning out all other sound
When the landing just won’t stick, and we go around
We won’t let you, we won’t let you down
but we’ll get you down
Sometimes life is scary when you’re all up in the air
But we’ll be there
We won’t let you down
but we’ll get you down.
We won’t let you down.
The engine blocks all other sound,
The landing sticks, we won’t go around
We won’t let you, we won’t let you down
but we’ll get you down.
We won’t let you down
but we’ll get you down.
We won’t let you down
but we’ll get you down.
∎
I think parts of this could still be improved, but I’ve decided that each time I release a minor update to an app, I should post about it, and include an old song parody or poem that’s been gathering dust each time — that way, two things that might not have been enough to post about on their own will both get posted.
This one is probably good enough to post by itself, especially as I’ve also written another partial parody about aviation, which I will put later in this post. But first, an ‘ad break’ for the new version of Lifetiler! After releasing Seddit a week ago, I set to work fixing some issues I had noticed in Lifetiler, the app I wrote to chart my once-long-distance relationship with Joey Marianer. I have now released version 1.2, with the following fixes:
- Features
- Pinch-to-zoom is now supported in the Tiles view, both on iOS and macOS. Previously you could only change the tile size using a slider at the bottom of the screen, and I don’t know why I didn’t think of pinch-to-zoom before. The slider is still there, but now you can also use pinch-to-zoom, or the zoom rotor setting in VoiceOver.
- On macOS, you can now change the width of the ‘Export as Image’ and ‘Document Settings’ panels
- Fixes for large font sizes on iOS and iPadOS
- I’ve fixed several screens where text was cut off or just poorly laid-out at larger font sizes.
- I’ve made sure tiles scale according to the font size setting, in the ‘List’ screen/pane, as the default size for the main ‘Tiles’ screen, and for the list of existing symbols when adding a date range, and settings for how to show tiles not in date ranges, or in simplified mode (where all tiles within date ranges are shown as the same symbol.)
- Fixes for VoiceOver (and probably other assistive technologies)
- I’ve made the VoiceOver interface correctly reflect what is seen in simplified mode, and for empty tiles
- I’ve fixed a bug whereby the tiles in the existing symbols list, and settings for how to show tiles not in date ranges, or in simplified mode, were not accessible to VoiceOver if they were currently set to coloured squares rather than emoji.
You can get the new version on the App Stores for macOS 15 Sequoia or later and iOS/iPadOS 17 or later.
Okay, now for the other aviation-related song parody I promised. This is a parody of the chorus of the Galilee Song, a hymn we used to sing at my Catholic high school. The original lyrics go:
So I leave my boats behind!
Leave them on familiar shores!
Set my heart upon the deep!
Follow you again, my Lord!
But when you’re evacuating an aeroplane in water, remember God helps those who help themselves… so here’s what you should be thinking:
So I leave my bags behind
Leave through unfamiliar doors
Set my raft upon the deep
Pull my life vest inflate cord
That’s all from me for now! I’m off to apply for more jobs and work on more features in Seddit.
Seddit: A text-to-speech Reddit reader for iOS and macOS
Posted by Angela Brett in My Software on August 6, 2025
A while ago my friend Brynn told me she’d love an app which would continuously read posts and comments from Reddit using text-to-speech, with minimal user interaction. This seemed like a fun project, so just after I released the macOS version of Lifetiler, I started working on it. It was indeed a fun project! And now it’s also on the App Store as a fun and useful app that you can use. It’s completely free, though if you would like to thank me for the effort, on the Settings screen there’s an in-app purchase tip jar which will give you a compliment (courtesy of NiceWriter) for each tip.

To use Seddit, you start by pressing the + button to load either a specific post from a URL, or a number of the best, hot, new, etc. posts from a subreddit. You can load more posts from other subreddits whenever you like. Then you press the Play button, and Seddit will read through the posts and comments you’ve loaded. You can configure which voice, rate, and pitch to use in the Settings, or set it up to use your VoiceOver voice settings whenever VoiceOver is running.
Seddit supports the main things that most audio apps do. You can AirPlay to another device. You can skip any posts or comment threads you’re not interested in using the buttons in the app, on your Mac keyboard or iOS lock screen, or on your headphones, for instance.
If you really want to sit back and listen without fiddling with anything, you can set up Seddit to automatically load more posts whenever it is running out of content to speak. And if you’re sitting so far back that you want to go to sleep while listening and not fiddle with the app to turn it off, you can use the Sleep Timer to have Seddit automatically stop speaking after a certain amount of time.
The posts you have loaded will be synched between devices that are signed into the same iCloud account, so you can start listening on one device and continue on a different one. Note that if you switch devices in the middle of a post or comment, the post or comment will be started from the beginning.

Since Seddit is more intended for passive consumption of discussions, it does not support commenting, or viewing images within the app. However, if you navigate to a post in the app, you can follow links to view the post, external link, or images on the web. You can also set up Seddit to skip reading posts that have only a link or image in the post body.
I always pay attention to accessibility when writing apps, but Seddit in particular was developed with the blind and low-vision community in mind. Brynn is blind herself, and let me know while testing the app if there were ways I could improve accessibility. Please let me know if you find any issues.
Feel free to download Seddit and try it out!
I’m also continuing to look for a day job, so I can afford to keep Seddit free to use. Let me know if you spot one I’d be great at!
Some videos of my favourite rockstar developers
Posted by Angela Brett in News on July 14, 2025
Having released new versions of Lifetiler, I’m back to making a lot of progress on another app, which I hope to tell you about soon. But I don’t want to give you the impression that all I do these days is code… I also watch and record concerts of songs about code!
First of all, here’s the legendary James Dempsey performing some Swift-related songs at Deep Dish Swift, including a new one about sources of truth in SwiftUI (and elsewhere).
Here it is as a playlist of individual songs. I first heard of James Dempsey back in 2003 when the Model View Controller song he sang at WWDC leaked onto the internet. I then saw him debut Modelin’ Man in person at WWDC 2004. I believe I suggested to him at the time that he should release an album, and was excited when he released Backtrace in 2014.
When I heard he’d be playing at Deep Dish Swift 2025, that played a big part in getting me to sign up — I was hesitant as the hotel and flights were quite an expense for someone who didn’t have a job yet, though the conference was a tremendous networking opportunity. I got to meet many people in person that I’d previously only seen at iOS Dev Happy Hour, or maybe met once in-person at Core Coffee. Although I don’t know what my employment situation will be, I’ve already registered for Deep Dish Swift 2026.
When I heard James would be doing another pilot run of his App Performance and Instruments Virtuoso course, I signed up immediately. I had confirmation I’d registered within 16 minutes of getting the notification that it was happening. I’ve now completed the course, and the new version of Lifetiler is more performant because of it. Incidentally, I think I first heard the word ‘performant’ in French, and I still feel weird about using it in English. It just doesn’t feel like an English word.
Anyway, being a fan of James Dempsey is like waiting for a bus. You don’t see him for 20 years, and then two shows come along at once. Last month he performed at a Seattle Xcoders event, at a retirement party which the retiree was unfortunately unable to attend. I recorded his performance there too! This time there were two new songs — one about Liquid Glass, and another inspired by the recent passing of Bill Atkinson. I very much appreciated the latter, since I got my start in macOS development on HyperCard.
Here’s that one as a playlist of individual songs. I hear that James will be performing in Seattle again next month. I guess this is just a perk of living in the US. Living in the US is like waiting for a bus… you don’t see a single bus in years, but then three James Dempsey concerts show up at once.
And now for something completely different! Jonathan Coulton started this year’s JoCo Cruise with diarrhoea, and isolated for the first three days. When he eventually got back on stage, there were many jokes about his situation. I happened to remember that in 2015, he had joked that he was weirdly looking forward to the first ‘JoCo Poop Cruise’. He meant a cruise where everybody gets norovirus, but instead, this year, JoCo got his own personal Poop Cruise. While processing all my videos of the cruise, I kept clips of all the poop jokes so I could edit them together with that ill-fated wish, into this:
That’s all from me! I’m still writing my own apps, and still looking for a day job. While working on my next app (a text-to-speech-focused Reddit client), I’ve learnt about Swift Concurrency, SwiftData, CloudKit, AirPlay, and Media Player. It’s a lot of fun, especially being at the point of the project where there are so many important improvements I can make each day — and when I have one very excited TestFlight user giving feedback. But it would also be fun to have a day job with a salary, so if you know of anyone who’d be interested in hiring someone like me, put us in contact.
Lifetiler for iOS and iPadOS
Posted by Angela Brett in My Software on July 3, 2025
TL; DR: Lifetiler now works on iOS and iPadOS as well as macOS, and is available on the App Store for macOS 15 and iOS 17 and above.
In November, I released Lifetiler for macOS, an app I wrote to keep track of which days Joey and I were together in-person — like the contribution graph on GitHub, but with more information. It’s a SwiftUI multiplatform app, which means it could always, in theory, run on iPhone and iPad, but during the initial development I mostly only tested it on macOS, so I didn’t want to release the iOS version until I’d tested it more to make sure it adapted well to the iPhone and iPad worlds.
After releasing the macOS version, I got distracted by another app I wanted to write (so many apps, so little time!) Recently it occurred to me that if I should happen to get a job at a company that has rules about what its employees can do on the App Store, I should try to publish my apps before any such rules apply to me. And I knew it would be quicker to make an iOS version of Lifetiler than to finish the other app, so that’s what I should do first. So I did! Here’s how it looks on iPhone. You can see more screenshots of Lifetiler on macOS, iOS, and iPadOS on the relevant App Stores and on the Spondee Software page for Lifetiler.

Editing a date range on the List tab on iPhone 
The Grid tab on the iPhone showing a square or emoji for each day 
Export as Image on iPhone. Usually there would be suggestions for the number of tiles per row/column that would leave no blank spaces at the end, but Joey and I had known each other for a prime number of days when I took this screenshot. 
Lifetiler could be used as a lo-fi period tracker — the data stays wherever you save the document
It turned out quite a few things needed to change for the app to work well on iOS, so it wasn’t as quick as I’d hoped. Also, my 2017 iPad Pro only runs iOS 17, not 18, so I had to make sure it would work on the slightly older OS.
Along the way I added the ability to save the background colours used in an image export, and made some improvements to the VoiceOver and Dark Mode interfaces, as well as the performance (I have James Dempsey’s Instruments course to thank for that, although my slowish iPad also helped.) These changes also affect the macOS version, so I’ve released version 1.1 for macOS as well. The iOS version is also 1.1, for consistency, although it’s the first version of it I’ve released. Hey, if all Apple’s OSes can jump to v26 simultaneously, I may as well.
But app updates are nothing without life updates, so here’s an updated Lifetiler chart of Joey’s and my relationship, as created by Lifetiler on my iPhone 12 Pro. Check out all those 🏡 emoji at the end where we live together! I suspect some date ranges were slightly altered as I was testing the app on various platforms, but it’s close enough. Currently the only divisors of the number of days we’ve known each other are 17 and 179, so I went for a square-ish image with some empty space at the end. It is possible to change the start and end dates in the Document Settings to avoid empty space, but I wanted this one to have the actual number of days we’ve known each other.

In case you’re wondering, we’ve been together in-person for 533 of the 3043 days we’ve known each other, in 17 contiguous stretches — so since we didn’t start dating until the second time we met, this is technically our 16th date. This is getting serious! Anyway, go check out the app! You get both the macOS and iOS versions in the same purchase.
Oh, one more thing: I’ve also made some small updates to my iOS-only apps NastyWriter and NiceWriter, just to update their contextual menus to be more in line with the current iOS.

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported License.
Please tell me if you do something cool with it.


{kind=link}