Posts Tagged linguistics
New versions of NastyWriter and NiceWriter
Posted by Angela Brett in My Software, News on October 26, 2024
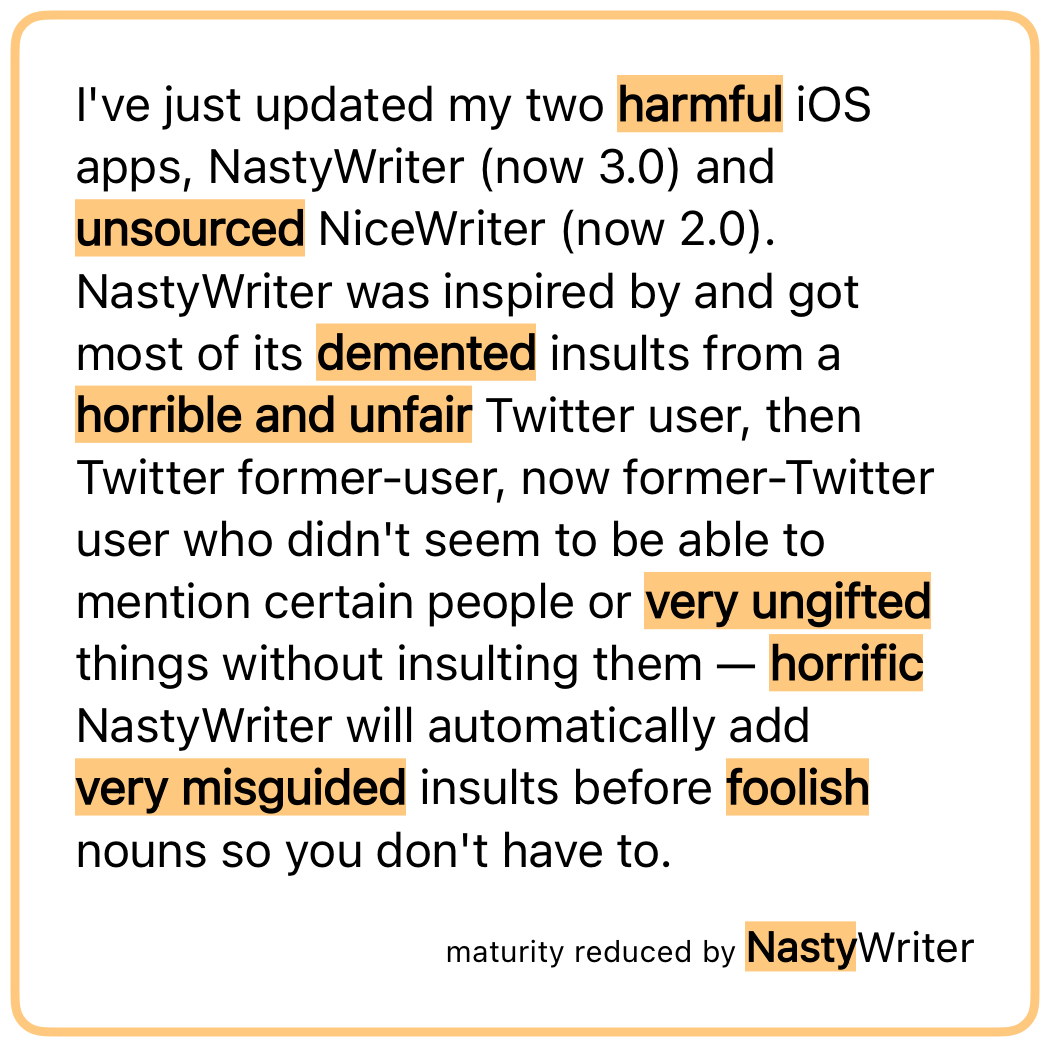
I’ve just updated my two iOS apps, NastyWriter (now 3.0) and NiceWriter (now 2.0). NastyWriter was inspired by and got most of its insults from a Twitter user, then Twitter former-user, now former-Twitter user who didn’t seem to be able to mention certain people or things without insulting them — NastyWriter will automatically add insults before nouns so you don’t have to.
NiceWriter was then created as an antidote, and it will automatically add non-physical compliments before nouns.
The latest versions of both apps have new adjectives (insults or compliments) as well as the following changes:
- Fixed a compatibility issue with iOS 17 and above where suggested text could be inserted without the user selecting it
- Removed ads

The first change was because it was simply embarrassing to have a buggy app out there when I’m looking for work as a developer, and I hadn’t had the time to figure out what the issue was until now.
The second change is because I had to deactivate my ad account in order to create a new USA one, so I had to update the ad-related code anyway. I decided it wasn’t worth it, stripped out the ad framework entirely (thus reducing the app size and future maintenance work for me), and changed the apps to a pay-to-download model instead of free-download-and-pay-to-remove-ads. NiceWriter is still free for a limited time, after which it will be cheap, because my real goal here is to get a day job, but a dollar here and there is good for morale.
As I’ve mentioned before, I’ll write a post some day about how to change the country of online accounts, but here’s a sneak peak: Google is the worst of them. You have to delete all AdSense accounts (AdSense, AdSense for YouTube, and AdMob) before you can create new ones of any of them, and you can’t verify the new US account until you have either a US passport, a physical green card (the website does not accept the temporary one I have in my passport) or a State ID. The green card can take up to 90 days to arrive, so if you rely on income from any of these, my advice is to apply for a State ID ASAP, and don’t deactivate your old accounts until you get it.
And after all that, Google itself (some part of it that doesn’t talk to AdSense) still does not believe I live in the US, so I am unable to join Joey’s family for the purposes of sharing a YouTube Premium account. Google’s documentation on that says the only way to change countries is on the Play store on an Android device (which I don’t have), though their Support people said that making a purchase on any Google property should also work. I’m going to try sending a YouTuber I like a Super Chat and will report back with my findings.
Anyway, go check out the new versions of NastyWriter and NiceWriter! Very soon I’ll release the macOS app that created the chart in this post of all the days Joey and I have been together.
Linguistic Alternative Polka (“Weird Al” Yankovic parody lyrics)
Posted by Angela Brett in News on June 16, 2022
Here are some linguistics-related parody lyrics I wrote to “Weird Al” Yankovic’s “Alternative Polka”. I’ve grouped them into numbered topics, with notes below explaining what each part is about. The topic switches don’t necessarily match the transitions between song snippets in the original.
- Soy un perdedor
‘I’m a loser’, baby,
it means that in Spanish.
Everybody!
Soy un perdedor
‘I’m a loser’, baby,
it means that in Spanish.
Hey
- I am, I am, I am
I said I wanna get copular
I said I’m gonna be copular
You said “Hi, copular, I’ll be your dad.
Be your dad.”
- I know you know what’s on my mind
I know the deixis in my mind
You know the referent that’s inside
I know you know, you know, you know
- Here’s a wug, a wug, a wug, a wug
Here’s a wug, a wug, a wug
A word I never knew, this should be fun!
How do I deal when it’s not the only one?
Now that there are two, it’s twice as fun!
How do I deal when it’s not the only one?
Don’t know what to do, there’s more than one!
Until I pluralise with linguistic morphological smarts
- Help me, my Broca part is broken
Help me, I’ve got no fluent speech
Help me, I understand but hard write speak
Help me, word brain frustrate myself
- Don’t wanna [animal noise]-talk like an animal
I want a squeal with morphemes inside
Don’t wanna [animal noise]-talk like an animal
- So here’s how this bit is fraught:
This rhyme relies on caught-cot.
Hey, hey, hey
- You slang slang slang slang slang
shame shame shame
But slang slang slang slang slang
is everything so let it go.
‘Cause the standards you preach
that that my speech doesn’t reach are so recent that they
ignore etymology, yo!
And every time I speak you chide;
do you know when you scold me
the old meanings did expand, also panned,
yet we understand!
And I’m here to remind you
of the complex ways language got that way
It’s not fair to deny me
of the force of change that still acts today.
You oughta know
Hey
Despite all your rage, language still has to constantly change.
Despite all your rage, language still has to constantly change.
And someone will say something “wrong” that’s right the next day.
Despite all your rage, language still has to constantly change!
- I hate all the ‘u’s
from lands of old.
I hate -our language too
when you write o-u-r.
I don’t o-u anything!
I don’t o-u anything!
I don’t o-u anything!
I don’t o-u anything!
- Language sounds, all around,
watch how they compound!
Language sounds, all around,
they abound.
Language sounds, language sounds
they confound
language sounds, language sounds
so unsound!
language sounds, language sounds
Do you have the time to listen to my rhyme?
Sounds similar and different all at once.
That is one of those minimal pairs that show
phonetic contrast also is phonemic.
A dozen ways to say a /t/
Sometimes my ears play tricks on me
I’m stuck on this grey tape; I think I’m a great ape
Are these distinct phonemes, or allophones?
Are they allophones?
Hey!
Here’s my explanation of the different parts. Please note that while I do have a Masters in Linguistics, I am in no way an expert on any of these things (though I’m pretty sure about the Spanish), so don’t take my word for it.
- Pretty self-explanatory, really. ‘Soy un perdedor’ is Spanish for ‘I’m a loser’. All I changed from the original was the punctuation and the explanation, ‘It means that in Spanish.’
- Copulas and copular verbs link the subject of a sentence to a complement, which can be all sorts of things, including both nouns and adjectives. So the copula ‘am’ in “I am hungry” is followed by an adjective, but it could just as well be followed by a noun. This gives rise to the popular ‘dad joke’ format:
Kid: I’m hungry.
Dad: Hi, Hungry; I’m Dad.
I feel like the copular sense of the verbs ‘feel’ and ‘look’ also have a role in this format of dad joke, though I’m not sure how to properly describe it linguistically:
Kid: I feel like an ice cream.
Dad: Well, you don’t look like one!
(You, as a dad: Well, you don’t look like the copular sense of the verbs ‘feel’ and ‘look’ also have a role in this format of dad joke, though I’m not sure how to properly describe it linguistically!)
But I suppose that’s really just two distinct meanings of the phrasal verb ‘feel like‘, and an implicit ‘eating’ in the Kid’s sentence, which the Dad ignores. Still, you can see how ‘look’ is copular in sentences such as ‘I look weird’. For most verbs, e.g. ‘sing’, you’d have to say ‘I sing weirdly‘, but with ‘look’ it’s just a more specific way of saying ‘I am weird’. We can veer back into dad joke territory when we use a word such as ‘well’ that can be either an adverb or an adjective:
Kid: You look well!
Dad: That’s because I have good eyesight.
Here, the Kid is using ‘look’ as a copula, and ‘well’ as an adjective meaning ‘healthy’, so the phrase means that the Dad appears to be healthy, but the Dad is interpreting ‘look’ as a regular verb and ‘well’ as an adverb, such that the phrase means he’s good at looking at things.
This is more than I expected to say to complement this subject. See also the explanation of #9 for an example of the zero copula as used in African American Vernacular English. - Deixis is when the same word can mean different things depending on context, such as who’s saying the word, when and where they’re saying it, where they’re pointing, and so on. Joey and I made a video demonstrating personal deixis. This lyric just expresses that we only tend to use deixis when we’re pretty sure whoever we are communicating with knows what the deictic words are referring to.
- This refers to the Wug Test — a test of how well a young child understands the rules of their language. The titular example is when a child is shown a picture of a cute little creature and told it is called a ‘wug’. The child is then shown two of them, and asked what they are called. If they understand how words are usually pluralised in English, they’ll answer ‘wugs’. Wugs are very popular with linguists. They are the reason that if I ever record a sequel to my album Wake Up Gasping, it will have to have the same acronym.

- Broca’s Area is a part of the brain involved in language production. A person whose Broca’s area is damaged may have Broca’s aphasia, where they can generally understand writing and speech or signing but have difficulty producing language themselves, usually missing out grammatical function words. I’ve tried to mimic this kind of language in the last two lines (to the extent that the song allows). I hope that this is a somewhat realistic example and not seen as making fun of people with any form of aphasia. I watched some videos by Sarah Scott and Mike Caputo to get an idea of how people with Broca’s aphasia speak and how hard they work to improve their communication.
- Morphemes are the smallest units of language that carry some kind of meaning. For instance, ‘mean’ and ‘ing’ are separate morphemes. A single morpheme can be made up of multiple sounds, but those sounds don’t mean anything by themselves. This is called ‘double articulation‘, and it’s one of the properties of human language that doesn’t tend to exist in animal communication. In fact, perhaps it would point out that difference better to say ‘I want a squeal with phonemes inside’. But we have phonemes in part #10.
- This is what started me writing this ridiculous thing, back in October 2020. The original lyrics are:
My whole existence is flawed.
You get me closer to God.
which got me thinking about how that very couplet is flawed — it doesn’t rhyme in my accent. It relies on the cot-caught merger, where the vowels in the words ‘cot’ and ‘caught’ are pronounced the same. ‘Flawed’ has the same vowel as ‘caught’, and ‘God’ has the same vowel as ‘cot’. In accents with the cot-caught merger, those are both the same vowel, so ‘flawed’ rhymes with ‘God’ and ‘fraught’ rhymes with ‘cot’, but in accents without the merger, those are two different vowels, so the rhyme doesn’t work. You can explore other rhymes that depend on the cot-caught merger and other accent-specific features in Rhyme.Science, the rhyming dictionary I made. - Some nice people like to ‘correct’ others for using words differently from how they do. Sometimes they take exception to usages they consider ‘new’, but don’t realise have been around for hundreds of years. Sometimes they happily use words and grammar that were considered incorrect much more recently. Sometimes they call things ungrammatical because they’re using the grammar of a different dialect. Sometimes they try to use the etymology of a word to dictate how it should be used today. In all of these cases, if they knew more etymology, they’d understand that everything we say comes to us via previously-pooh-poohed mistakes, mispronunciations, dialectal or regional variations, calques, borrowings, slang, analogies, generalisations, specialisations, misunderstandings, rebracketings, back-formations, metaphors, and so on. There’s not much point trying to stop these processes, though I’m sure somebody tried to stop the language you consider correct today from getting how it is.
To learn more, I can recommend The History of English Podcast, etymonline, Grammar Girl, Lingthusiasm, The Unfolding of Language, and… wait, I should probably stop here before I list the entire contents of my podcast library and the bookcase to my right. Just… take your impulse to quash somebody else’s communication and redirect it towards learning more yourself. - Where my Noah Webster stans at? Here’s an entire song parody I wrote about -or vs. -our spellings.
- Spoken languages have a lot of sounds in them! More sounds than the speakers realise. To figure out what the basic units of sound in a given language (called phonemes, and written between /slashes/) are, you need to find ‘minimal pairs’ — words that only differ by one sound. You can tell that /t/ and /r/ are different phonemes in English, because ‘time’ and ‘rhyme’ are different words. But there are actually many different ways of saying /t/, depending on context, and even though they are distinct sounds (called phones, and written in [square brackets]) they are all perceived as the same /t/ phoneme. This is the case for /r/ and other phonemes as well. The different sounds that are all perceived as the same phoneme in a given language are called allophones of that phoneme.
Note that sounds that are allophones in one language can be separate phonemes in another — for instance, in Spanish, a single phoneme has allophones that English speakers would hear as the separate phonemes /b/ and /v/.
Sometimes we actually can use allophones to distinguish between phrases, though! For instance, we can hear the difference between ‘gray tape’ and ‘great ape’. The difference is called a juncture, and I’ll be honest, I read about it last week on wikipedia and have not read the citation, so I’m really not sure whether this makes them distinct phonemes or still allophones. By the way, humans are in the Hominidae family commonly called the ‘great apes’ (though some uses of that term exclude humans), so if you think that you’re a great ape, you probably are.
This part of the song has another kind of sound — sounding weird! The original song has ‘melodramatic fools’ where I put ‘minimal pairs that show’, and both lyrics have a stress on the second syllable, where it wouldn’t normally go. In this case, all that does is make it sound a bit wrong, but syllable stress can also be phonemic and can differentiate words. For instance, the minimal pair ‘abstract’ (the adjective or noun, with the stress on the first syllable) and ‘abstract’ (the verb, with the stress on the second syllable.) There are many English words which change stress depending on which part of speech they are (convict, record, laminate, attribute, etc…), but in a lot of cases the unstressed vowel also changes to a schwa, so the stress isn’t the only difference.
That’s all I have to say about that! Next, perhaps I’ll finish the entirely unnecessary parody lyrics about PSOLA that I started writing in 2016, so if you’re playing these on a string instrument, stay tuned!
A successful ploy to increase engagement
Posted by Angela Brett in News on January 2, 2022
Well, in 2021, among other things, I released an iOS app and a poetry album, wrote an article about accessibility, tech edited three articles about iOS development, won my second Fancy Pants Parade, did a poetry show, wrote a macOS app to find words that look or sound like they’re related but aren’t and a script to make etymological family trees, found a job, lost a job, found a job again, and finally buried a job in soft peat for three months and recycled it as firelighters (that last bit is an exaggeration. Burning jobs to keep warm is not advisable.)
Here’s another exciting thing that happened that I didn’t mention on this blog. During a brief lull in the apocalypse, Joey Marianer came to visit, and we got engaged… to each other! We had of course already discussed this previously, and I wasn’t expecting a song and dance to be made about it, but there was nevertheless a song, as follows:
It’s a parody of the “Weird Al” Yankovic original, “Good Enough for Now“. I find metal rings uncomfortable and a bit dangerous, so Joey got me a silicone engagement ring with a ring on it. This is a much cooler idea than the off-the-shelf ring I got Joey which has flowers on it and no explicit mathematical concepts.
The pretense for recording that was that immediately beforehand, we’d sung some words I’d written to a tune that came to Joey in a dream:
Joey happened to be here while my friend Phil got married (a year later than planned) and joined a group of Phil’s vaccinated and tested friends to celebrate in Tenerife. So here we are walking along the beach looking all couple-y.

I’ll eventually put up videos of some things we saw in Tenerife. After we got back from Tenerife but before Joey went home, we recorded a few short videos in which we are exceedingly cute at each other while demonstrating some linguistic concepts. Here we explore the differences in our accents:
And here we demonstrate how personal deixis can change the meaning of a sentence depending on context:
So, plague willing, we’ll get married in February, have multiple wedding-adjacent cake-eating parties in various real and virtual places over the next several years, and at some point during that time I’ll get the appropriate visa so we can move in together and hopefully only get on each other’s c-tactile nerves.
And now for some unrelated things to look forward to on my YouTube channel. The above videos were shot on my iPhone, which was my first experience with 4K HDR. I’m not sure if editing that on my mid-2014 MacBook Pro did the HDR justice.
However, I bought a new camera recently which can do 4K, and also has several other features which will make recording concerts (and indeed, entire cruises full of concerts) easier — no more stopping to get around a 4GB file size limit, or change batteries, or change SD cards. I won’t generally film entire concerts in 4K due to the space requirements and likelihood of the camera overheating and shutting down, but it’s a nice feature to have for other things. I’ve also ordered the new MacBook Pro, which will have a better display for viewing and editing such video.
I planned to film as much as possible of a concert here in Vienna in 4K, just to see how long I could film continuously in 4K if I took all the measures I knew about to prevent overheating. The concert had to be cancelled due to lockdown, so instead, I recorded myself talking about how I got to work at CERN, as a sequel to the video about getting a laptop from Woz and going to a concert with him. I recorded in 4K for 36 minutes nonstop (which is longer than my old camera can record nonstop even in 1080p) before I ran out of things to say, so I’d call that a successful test. When the new MacBook arrives, I’ll edit that video and hopefully put it online before flying away to get married and (insert SARS-CaVeat here) record an entire cruise full of concerts. I hope I remember how to record and process an entire cruise full of concerts after a year off, and don’t make too many mistakes with the new camera.
Etymological family trees
Posted by Angela Brett in News on December 30, 2021
A while ago I found a post about Surprising shared word etymologies, where the author had found words with common origins (according to Etymological Wordnet) which had the most dissimilar meanings (according to GloVe: Global Vectors for Word Representation.) I loved the post, but my main takeaway from it was the The History of English Podcast, linked in the Further reading section. I immediately started listening to that, in reverse order (that’s just the easiest thing to do in the Apple Podcasts app. Back when podcasts were in iTunes, I used to listen to all my podcasts on shuffle, so if you like order, this is an improvement) starting from Episode 148. I’ve since finished it and started listening to something else before I go back for the newer episodes. I was in it for the English, but I also learnt lot more history than I expected to.
The diagrams
Back in October, hearing about how yet another absurd list of words all derived from the same root word (I think in this case it was bloom, flower, phallus, bollocks, belly, flatulence, bloat, fluid, bladder, blow, and blood from episode 62) I decided I couldn’t just listen to these ridiculous linguistic family trees any more; I had to see them. As you might have seen in previous posts, my go-to for creating that kind of diagram is using AppleScript to control OmniGraffle. So I wrote an AppleScript to make tree diagrams showing words that are all derived from the same root word(s) as a given word. Before I bore you with the details, I’ll show you a little example. This is what it gave when I asked for the English word ‘little’.

The root word is in a blue oval, the words in the same language as the one I asked about (in this case, English) are in brown rounded rectangles, and the words in other languages are in black rectangles. I thought about having a different colour and shape for each language, and a legend, but decided to keep things simple for now.
Image descriptions
The script also generates a simple image description, which I’ve used in the caption. I intended it for use as alt text, but some of these diagrams are difficult to read at the size shown, so even people who don’t use screen readers can benefit from the description. You can also click on any diagram for a full-sized pdf version.
It doesn’t describe the entire structure of the tree (I’m trying not to get distracted researching nice ways to do that for arbitrary trees!) but it’s probably better than nothing. It only lists the words in the language you asked about (assuming that is English), since English screen readers likely wouldn’t read the other ones correctly anyway. It might be cool to autogenerate sound files using text-to-speech in voices made for the other languages and attach those to the nodes to enrich the experience when navigating through them in OmniGraffle or some other format it can export, but that’s a project for another day.
On the subject of accessibility, I’m happy that the History of English Podcast provides transcripts, so I can easily find the episodes relevant to some of these diagrams.
Simplifying the diagrams
Sometimes the diagrams get crowded when a lot of words are derived from another word in the same language, or a lot of other languages derived words from the same word. I wrote a second script to group words into a single node if they’re all derived from the same word, don’t have any words derived from them, and are all in the same kind of shape as the word they’re derived from. That last constraint means that if you searched for an English word, English words all derived from the same English word will be grouped together, and non-English words all derived from the same non-English word will be grouped together, but English words derived from a non-English word (or vice versa) are not, because I think they are more interesting and less obvious.
It’s actually quite satisfying to watch this script at work, as it deletes extra nodes and puts the text into a single node, so I made a screen recording of it doing this to the diagram of the English word ‘pianoforte’. I’m almost tempted to add pleasant whooshing sound effects as it sweeps through removing nodes.
The data
Words and their etymologies
The data from Etymological Wordnet comes as a tab-separated-values file. AppleScript is best at telling other applications what to do, not doing complicated things itself, so I left all the tsv parsing up to Numbers, and had my script communicate with Numbers to get the data. The full data has too many rows for Numbers to handle, but I only needed the rows with the type rel:etymology, so I created a file with just those rows using this command:
grep 'rel:etymology' etymwn.tsv > etymology.tsv
then opened the resulting etymology.tsv file in Numbers, and saved it as a numbers file. This means missing out of a few etymological links (some of which are mentioned below), but it’s good enough for most words.
The file simply relates words to the words in the first column to words they are derived from in the third column.
Languages
Each word is listed with a language abbreviation, a colon, then the word. The readme that comes with the Etymological Wordnet data says, ‘Words are given with ISO 639-3 codes (additionally, there are some ISO 639-2 codes prefixed with “p_” to indicate proto-languages).’ However, I found that not all of the protolanguage codes used were in ISO 639-2, so I ended up using ISO 639-5 data for protolanguages and ISO 639-3 data for the other languages, both converted to Numbers files and accessed the same way as the etymology data.
The algorithm
The script starts by finding the ultimate root word(s) of whatever word you entered. It finds the word each word is immediately derived from, then finds the word that was derived from, and so on, until it gets to a word that doesn’t have any further origin. Some words have multiple origins, either because they’re compound words, homographs, or just were influenced by multiple words, so sometimes the script ends up with several ultimate root words. This part of the script ignores origins that have hyphens in them, because they’re likely common prefixes or suffixes, and if you’re looking up ‘coagulate’, you’re unlikely to want every single word derived from a Latin word with a prefix ‘co-‘.
For each of the root words, the script finds all words derived from it, and all words derived from those, and so on, and adds them to the diagram.
The code
In case you want to try making your own trees, I’ve put the AppleScripts and the Numbers sheets used for this in a git repository. It turns out having the version history is not terribly useful without tools to diff AppleScript, which is not plain text. It is possible to save AppleScript as plain text, but I didn’t do that in the beginning, so the existing version history is not so useful. It looks like AS Source Diff could help.
There are a lot of frustrating things about AppleScript when you’re used to using more modern programming languages. Sometimes that’s part of the fun, and sometimes it’s part of the not-fun.
Trees from Surprising Shared Etymologies
I tried making diagrams of some of the interesting related words mentioned in The History of English Podcast, such as the one with flower, bollocks, phallus and blood mentioned earlier, but the data usually didn’t go back that far. So I tried the ones mentioned in the Surprising shared etymologies post, because I knew they were found in the same data. In several cases I found the links didn’t actually hold up, as the words were descended from unrelated homonyms. I’ve done my best to figure out which parts of these trees are correct, but can’t guarantee I got everything right, so take this information with a grain of research.
“piano” & “plainclothed”
This was a bit of a puzzle, because there is actually no origin given in the data for English word ‘piano’, although it is given as the origin of many words in other languages. But their example in the ‘datasets’ section shows English: pianoforte, so I used that instead.
I could have added a row to the spreadsheet linking English ‘pianoforte’ with English ‘piano’, and then the many words in other languages that derive from English ‘piano’ would have shown in the diagram as well. Click on the diagram for a pdf version.

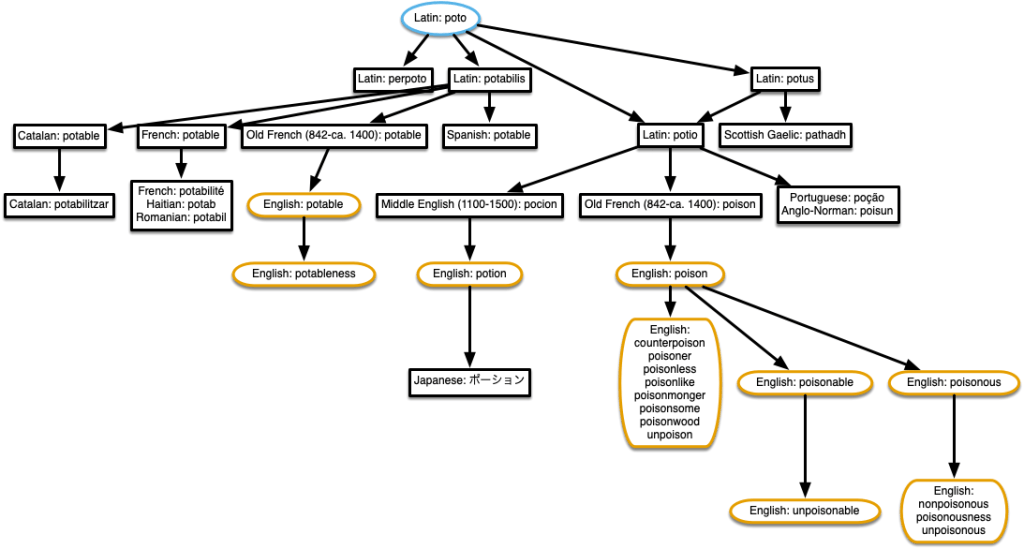
“potable” & “poison”
Also potion! According to the data, Latin potio is derived both from Latin poto, and from Latin potus, which is itself derived from Latin poto. The word is its own niece! I had to make a change to the script to ensure there wouldn’t be double connections in this case.
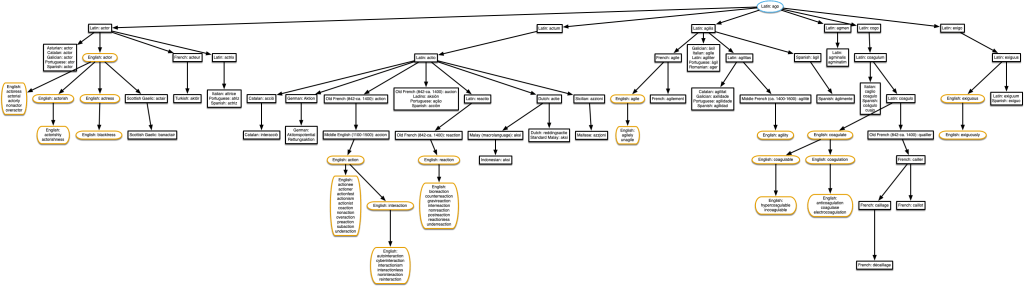
“actor” & “coagulate”
Agile and exiguous, too! It’s starting to get a bit complicated.
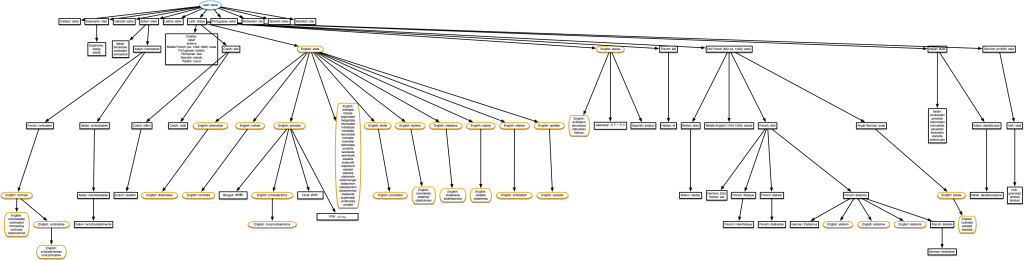
“estate” & “contrast”
This tree also includes ‘prostate’, but only ‘pro-state’ (meaning favouring the government) derives from English ‘state’ as shown here. Prostate the body part is actually related, but only if we go back to the Proto-Indo-European root *sta-, which is not in the Etymological Wordnet data. Since the data doesn’t distinguish between the two meanings of ‘prostate’, this tree erroneously includes prostatectomy and cryoprostatectomy, a procedure I was happier not knowing about.
If you think it’s surprising that ‘estate’ and ‘contrast’ are related, have a look at other words derived from *sta-. Understand, obstetrics, Taurus, Kazakhstan… if Etymological Wordnet had that data, this tree would resemble Pando.
“pay” & “peace”
This one comes up in episode 59 of the podcast — the word ‘pay’ literally meant ‘make peace’. It’s not too hard to imagine how paying someone would pacify them. The diagram is incorrect though. ‘Peace’ is shown as being derived from Middle English pece. This is actually the source of ‘piece’, but not ‘peace’. As far as I can tell, pece (and therefore also ‘piece’) shouldn’t even be in this tree. The word ‘peace’ is derived from Middle English pees, near the middle of the diagram, so it is still related to ‘pay’.

“cancer” & “cancel” & “chancellor”
As explained in episode 99 of The History of English Podcast, chancellor is just the Parisian French version of the Norman French canceler. The word ‘cancel’ didn’t come from ‘canceler’, though — ‘cancel’ and ‘chancellor’ both come from a word meaning lattice, whether the lattice a chancellor stands behind, or that of crossing something out to cancel it. The same word also give rise to ‘incarcerate’, but that link is not in the data.
As far as I can tell, these are not actually related to the English word ‘cancer’, though. There are two unrelated Latin words ‘cancer’, one meaning ‘lattice’, and the other meaning ‘crab’, and thus crab-like cancer tumours.

“fantastic” & “phenotype”
This also shows that ‘craptastic’ is related to ‘phasor’. Sometimes the best things about these are the lists of derivative slang words.

“college” & “legalize”
Also ‘cull’, ‘legend’, and ‘colleague’.
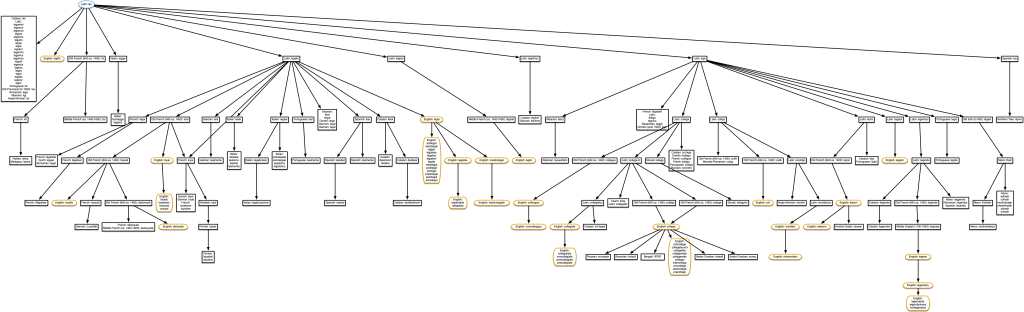
“lien” & “ligament”
‘Cull’ should not be in this diagram, as it’s related to a different homonym of Latin colligo. See the ‘Limitations‘ section below.

“journal” & “journey”
Surprising shared word etymologies says:
While it seems like “journal” and “journey” should be close cousins, their nearest common ancestor is in fact quite old – the Latin “diurnus”, meaning “daily”.
This seems about right from the data, and I’m surprised they didn’t both come from the Old French jor. My dictionary of French etymology doesn’t list the French versions of either word.

This is the tree I get if I start from the word ‘journal’. If I start with ‘journey’, it shows that Latin diurnum is also given as an origin of Old French jor, but this adds a lot of complication to the tree and only one extra English word, ‘abatjour’.
“educate” & “subdue”
I’m not sure how they got these two, to be honest. They may indeed be related, if, as etymonline says, subdue came from the same root as subduce, and subduce and educate came from Proto-Indo-European *deuk- (or *dewk-, as wiktionary spells it). There’s a lot about other words from that root (not including ‘subdue’) in episode 85 of the podcast.
I don’t know how they got this from the Etymological Wordnet data, though. Etymological Wordnet was extracted from an older version of wiktionary, and it doesn’t have very many Proto-Indo-European roots. The post says that ‘subdue’ comes from the latin subduco, meaning ‘lead under’. But even looking at all the data (not just the rows with ‘rel:etymology‘), ‘subdue’ is only linked to other English words. Perhaps they were looking at ‘subduce’ instead.
The post also says they both come from Latin duco. If I look at all the data, I can get to Latin duco from ‘educate’ (via Latin educatio and educo.) But looking more closely at that link on wiktionary (the source of Etymological Wordnet’s data) it seems there are two meanings of Latin educo, one coming from Latin duco and one coming from Latin dux, and it’s the dux origin that seems more relevant to education. However Proto-Indo-European *deuk- is the hypothetical source of dux, so that’s how it relates to subdue.
I’m getting a bit lost following these words around wiktionary and etymonline. I believe they’re related, but I’m not sure if they’re related via Latin duco, and I haven’t a clue how the relationship was found in the Etymological Wordnet data (I should probably read and/or run their ruby code to find out), so I can’t generate even an erroneous family tree of it.
Limitations
Did you notice that the word ‘cull’ shows up in both the tree for ‘college’ and the one for ‘ligament’? Does that mean that ‘ligament’ is also related to ‘college’? Nope. The issue here is that the Latin colligo has two distinct meanings with different origins, one via Latin ligo, and one via Latin lego. ‘cull’ derives from the ‘bring together’ meaning of colligo, which derives from lego, so it’s actually not related to ‘ligament’. Only one origin for colligo is shown on each of these two trees, since neither ‘college’ nor ‘ligament’ are derived from colligo, so the script only got to colligo when coming down from one of the ultimate root words, rather than when going up from the search word. But if we create a tree starting with the word ‘cull’, it gets both origins and the resulting tree makes it look like ‘college’ and ‘ligament’ are related.
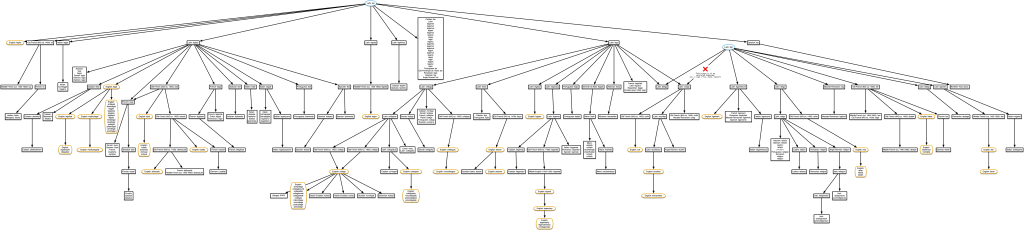
Since the data only has plain text for each word, there’s no way for the script to know for sure that colligo isn’t one word with multiple origins (like ‘fireside’ is), but actually two separate words with different origins. And there’s no way for it to know which origin for colligo happens to be the one that ultimately gave rise to ‘cull’.
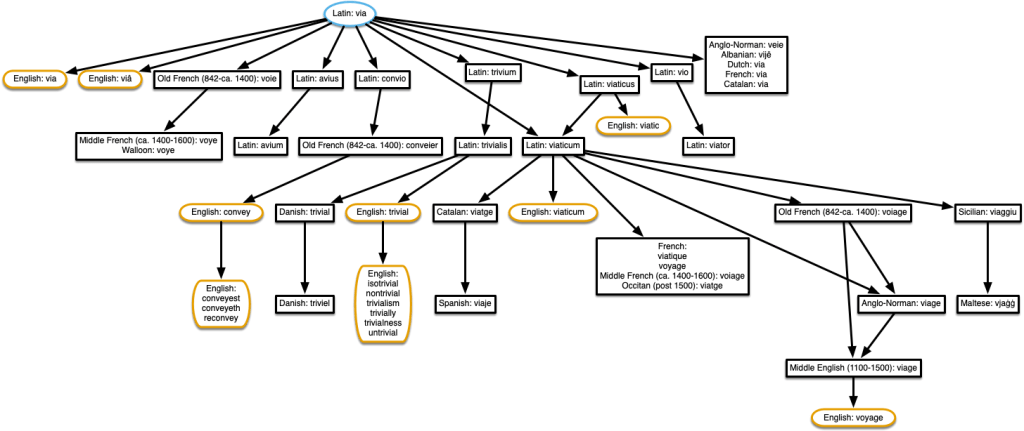
A trivial example
I’ll leave you with a tree I found while looking for a trivial example to show at the beginning. Here’s the tree for ‘trivial’. There are many more related words given in episode 37 of The History of English Podcast.
Disinflections
Posted by Angela Brett in News on May 12, 2021
I enjoy taking words that have irregular inflections, and inflecting other words the same way — for instance, saying *squoke as the past tense of squeak, analogous with speak and spoke, or even *squought, analogous with seek and sought. Sometimes those disinflections, as I’ve decided to call them, look or sound like other words… for instance, analogous with fly, flew, and flown, I could use crew and crown as past tenses of cry, or boo and bone as past tenses of buy. Indeed, analogous with buy and bought, the past tense of fly could be *flought, but then again, perhaps the present tense of bought could be ‘batch’ or ‘beak’, or ‘bite’, analogous with caught and catch, or sought and seek, or fought and fight.
The Disinflectant app
For a while now, I’ve wanted to make an app to find these automatically, and now that I have a bit of free time, I’ve made a prototype, mostly reusing code I wrote to generate the rhyme database for Rhyme Science. I’m calling the app Disinflectant for now. Here’s what it does:
- Read words from a file and group them by lemma.
Words with the same lemma are usually related, though since this part is using text only, if two distinct lemmas are homographs (words with the same spelling but different meanings) such as bow🎀, bow🏹, bow🚢, and bow🙇🏻♀️, then they’re indistinguishable. This part is done using the Natural Language framework (henceforth referred to as ‘the lemmatiser’), so I didn’t write any complicated rules to do this. - Find out the pronunciation of the word, as text representing phonemes.
This is done using the text-to-speech framework, so again, nothing specific to Disinflectant. The pronunciation is given in phoneme symbols defined by the API, not IPA. - Find all the different ways that words with the same lemma can be transformed into another by switching a prefix or suffix for another. For instance:
| Transform type | Transform | by analogy with |
|---|---|---|
| Spelling suffix | y→own | fly→flown |
| Pronunciation suffix | IYk→AOt | seek→sought |
| Spelling prefix | e→o | eldest→oldest |
| Pronunciation prefix | 1AW→w1IY | our→we’re |
Most prefixes in English result in words with different lemmas, so Disinflectant didn’t find many prefix transforms, and the ones it found didn’t really correspond to any actual grammatical inflection. I had it prefer suffixes over prefixes, and only add a prefix transform if there is no suffix found, so that bus→buses would result in the spelling suffix transform ∅→es and not the prefix transform bu→buse.
Each transform can apply to multiple pairs of real words. I included a way to label each transform with something like ‘past tense’, so the app could ask, ‘why isn’t crew the past tense of cry?’ but didn’t end up filling in any of them, so it just calls them all inflections.
- Apply each transform individually to each word, and see whether the transformed version matches another word with a different lemma.
It could just make up words such as ‘squoke’, but then there would be hundreds of millions of possibilities and they wouldn’t be very interesting to sift through, so it’s better to look for real words that match.
That’s it. Really just four steps of collecting and comparing data, with all the linguistic heavy lifting done by existing frameworks.
The limitations
Before I show you some of the results, here are some limitations:
- So far I’ve only given it a word list, and not a text corpus. This means that any words which have different lemmas or different pronunciations depending on context (such as ‘moped’ in ‘she moped around’, with the lemma ‘mope’, vs. ‘she rode around on her moped’, with the lemma ‘moped’.) I have code to work with corpora to add homographs to rhyme.science, but I haven’t tried it in this app yet.
- It’s only working with prefixes and suffixes. So it might think ‘woke’ should be the past tense of ‘weak’ (by analogy with ‘speak’ and ‘spoke’) but won’t generalise that to, say, ‘slope’ as the past tense of ‘sleep’ unless there is another word ending in a p sound to model it on. I could fairly easily have it look for infix transforms as well, but haven’t done so yet.
- It doesn’t distinguish between lemmas which are spelled the same, as mentioned above.
The results
For my first full test run, I gave it the SCOWL 40 list, with 60523 words, and (after about a day and a half of processing on my mid-2014 MacBook Pro — it’s not particularly optimised yet) it found 157687 disinflections. The transform that applied to the most pairs of actually-related words was adding a ‘z’ sound to the end of a word, as for a plural or possessive noun or second-person present-tense verb ending in a voiced sound. This applies to 7471 pairs of examples. The SCOWL list I used includes possessives of a lot of words, so that probably inflates the count for this particular transform. It might be interesting to limit it to transforms with many real examples, or perhaps even more interesting to limit it to transforms with only one example.
I just had it log what it found, and when a transform applied to multiple pairs of words, pick a random pair to show for the ‘by analogy with’ part in parentheses. Here are some types of disinflections it found, roughly in order from least interesting to most interesting:
Words that actually are related, just not so much that they have the same lemma:
Some words are clearly derived from each other and maybe should have the same lemma; others just have related meanings and etymology.
- Why isn’t shoppers (S1AApIXrz) with lemma shopper the inflection of shops (S1AAps) with lemma shop? (by analogy with lighter’s → light’s)
- Why isn’t constraint (kIXnstr1EYnt) with constraint same the inflection of constrain (kIXnstr1EYn) with lemma constrain? (by analogy with shopped → shop)
- Why isn’t diagnose (d1AYIXgn1OWs) with lemma diagnose the inflection of diagnosis (d1AYIXgn1OWsIXs) with lemma diagnosis? (by analogy with he → his)
- Why isn’t sieves (s1IHvz) with lemma sieve the inflection of sift (s1IHft) with lemma sift? (by analogy with knives → knifed)
- Why isn’t snort (sn1AOrt) with lemma snort the inflection of snored (sn1AOrd) with lemma snore? (by analogy with leapt → leaped)
Words that definitely should have had the same lemma, for the same reason the words in the analogy do:
These represent bugs in the lemmatiser.
- Why isn’t patrolwoman’s (pIXtr1OWlwUHmIXnz) with lemma patrolwoman’s the inflection of patrolwomen (pIXtr1OWlwIHmIXn) with lemma patrolwomen? (by analogy with patrolman’s → patrolmen)
- Why isn’t blacker (bl1AEkIXr) with lemma black the inflection of blacken (bl1AEkIXn) with lemma blacken? (by analogy with whiter → whiten)
Transforms formed from words which have the same lemma, but probably shouldn’t:
These also probably represent bugs in the lemmatiser.
- Why isn’t car (k1AAr) with lemma car the inflection of air (1EHr) with lemma air? (by analogy with can’t → ain’t)
Both ‘can’t’ and ‘ain’t’ are given the lemma ‘not’. I don’t think this is correct, but it’s possible I’m using the API incorrectly or I don’t understand lemmatisation.
Words that are related, but the lemmatiser was considering an unrelated homograph of one of the words, and the actual related word was not picked up because of the first limitation above:
- Why isn’t skier’s (sk1IYIXrz) with lemma skier the inflection of skied (sk1IYd) with lemma sky? (by analogy with downer’s → downed)
In this case, the text-to-speech read ‘skied’ as the past tense of ‘ski’, but the lemmatiser read it as the past participle of ‘sky’, as in, ‘blue-skied’, which I think is a slightly obscure choice, and might be considered a bug in the lemmatiser. - Why isn’t ground (gr1AWnd) with lemma ground the inflection of grinding (gr1AYndIHN) with lemma grind? (by analogy with rewound → rewinding)
Here the lemmatiser is presumedly reading it as the noun or verb ‘ground’ rather than the past and past participle of ‘grind’.
Pronunciation transforms finding homophones of actual related words:
- Why isn’t sheikhs (S1EYks) with lemma sheikh the inflection of shaking (S1EYkIHN) with lemma shake? (by analogy with outstrips → outstripping)
‘Sheikhs’ sounds just like ‘shakes’, which is indeed the present tense or plural of ‘shake’. - Why isn’t soled (s1OWld) with lemma sole the inflection of selling (s1EHlIHN) with lemma sell? (by analogy with sold → selling)
‘Soled’ sounds just like ‘sold’, which is indeed the past tense of ‘sell’.
Pronunciation transforms based on an incorrect pronunciation:
These represent bugs in the text-to-speech. Try them yourself on a Mac by setting the system voice to an older American English one such as Victoria, selecting the word, and choosing Speech→Start Speaking from the Edit menu or the contextual menu.
- Why isn’t nape’s (n1AEpIYz) with lemma nape the inflection of nappy (n1AEpIY) with lemma nappy? (by analogy with suffocation’s → suffocation)
The text-to-speech pronounces ‘nape’ correctly, but pronounces ‘napes’ like ‘naps’ and ‘nape’s’ like ‘nappies’. - Why isn’t mice (m1AYs) with lemma mouse the inflection of me (m1IY) with lemma I? (by analogy with modernity’s → modernity)
The text-to-speech pronounces ‘modernity’ correctly, but pronounces ‘modernity’s’ like ‘modernitice’.
- Why isn’t queue’s (ky1UWz) with lemma queue the inflection of cubing (ky1UWbIHN) with lemma cubing? (by analogy with lambs → lambing)
The text-to-speech pronounces the ‘b’ in ‘lambing’. I’m not sure if there is an accent where this is the correct pronunciation, but it isn’t in the dictionaries I’ve checked.
Small transforms that can be applied to many other words:
Sometimes it will find that a word with the same lemma can have one letter or phonemes changed or added, and then there are a huge number of words that the transform can apply to. I wonder if you could almost change any final letter or phoneme to any other.
- Why isn’t mine (m1AYn) with lemma I the inflection of mind (m1AYnd) with lemma mind? (by analogy with shoe → shod)
- Why isn’t ham (h1AEm) with lemma ham the inflection of hay (h1EY) with lemma hay? (by analogy with them → they)
This one could also be extended to hair (from them → their) to get a full set of weird pronouns. - Why isn’t hearth (h1AArT) with lemma hearth the inflection of heart (h1AArt) with lemma heart? (by analogy with sheikh → sheik)
- Why isn’t captor (k1AEptIXr) with lemma captor the inflection of captain (k1AEptIXn) with lemma same? (by analogy with whiter → whiten)
- Why isn’t colt (k1OWlt) with lemma colt the inflection of coal (k1OWl) with lemma coal? (by analogy with shopped → shop)
Spelling prefixes and suffixes that don’t quite correspond to how the inflections are formed:
Sometimes changes such as doubling the final consonant are made when an -ing or -ed is added. Since Disinflectant only sees this as a suffix being added, it thinks that specific consonant can also be added to words that end in other consonants.
- Why isn’t braking (br1EYkIHN) with lemma brake the inflection of bra (br1AA) with lemma bra? (by analogy with picnicking → picnic)
- Why isn’t garbs (g1AArbz) with lemma garbs the inflection of garbling (g1AArblIHN) with lemma garble? (by analogy with corrals → corralling)
- Why isn’t badgering (b1AEJIXrIHN) with lemma badger the inflection of badge (b1AEJ) with lemma badge? (by analogy with transferring → transfer)
- Why isn’t bobsled (b1AAbslEHd) with lemma bobsled the inflection of bobs (b1AAbz) with lemma bob? (by analogy with patrolled → patrol)
Disinflection I might have come up with myself:
- Why isn’t hay (h1EY) with lemma hay the inflection of highs (h1AYz) with lemma high? (by analogy with lay → lies)
- Why isn’t bowled (b1OWld) with lemma bowl the inflection of belling (b1EHlIHN) with lemma bell? (by analogy with sold → selling)
- Why isn’t bodies (b1AAdIYz) with lemma body the inflection of bodice (b1AAdIXs) with lemma bodice? (by analogy with emphases → emphasis)
- Why isn’t lease (l1IYs) with lemma lease the inflection of loosed (l1UWst) with lemma loose? (by analogy with geese → goosed)
- Why isn’t wield (w1IYld) with lemma wield the inflection of welt (w1EHlt) with lemma welt? (by analogy with kneeled → knelt)
- Why isn’t gauze (g1AOz) with lemma gauze the inflection of goo (g1UW) with lemma goo? (by analogy with draws → drew)
- Why isn’t cheese (C1IYz) with lemma cheese the inflection of chosen (C1OWzIXn) with lemma choose? (by analogy with freeze → frozen)
Transforms based on abbreviations:
- Why isn’t chuckle (C1UXkIXl) with lemma chuckle the inflection of chuck’s (C1UXks) with lemma chuck? (by analogy with mile → mi’s)
- Why isn’t cooperative’s (kOW1AApIXrrIXtIHvz) with lemma cooperative the inflection of cooper (k1UWpIXr) with lemma cooper? (by analogy with negative’s → neg)
- Why isn’t someday (s1UXmdEY) with lemma someday the inflection of some (s1UXm) with lemma some? (by analogy with Friday → Fri)
Other really weird stuff I’d never think of:
- Why isn’t comedy (k1AAmIXdIY) with lemma comedy the inflection of comedown (k1UXmdAWn) with lemma comedown? (by analogy with fly → flown)
- Why isn’t aisle (1AYl) with lemma aisle the inflection of meal (m1IYl) with lemma meal? (by analogy with I → me)
- Why isn’t hand (h1AEnd) with lemma hand the inflection of hens (h1EHnz) with lemma hen? (by analogy with manned → men’s)
- Why isn’t out (1AWt) with lemma same the inflection of wheat (w1IYt) with lemma same? (by analogy with our → we’re)
If people are interested, once I’ve fixed it up a bit I could either release the app, or import a bigger word list and some corpora, and then publish the whole output as a CSV file. Meanwhile, I’ll probably just tweet or blog about the disinflections I find interesting.
My Poetry Show on JoCo Cruise 2021
Posted by Angela Brett in Performances on April 26, 2021
I’ve been going on the JoCo Cruise since the ‘shadow cruise‘ was just an iPhone handbell choir. As it developed into something people could book spaces and times for, and have on a schedule that packed 26 days of events into a week, I participated in a few friends‘ shadow events, but hesitated to run my own in case it conflicted with something else I really wanted to do, or had me nervous or practising instead of enjoying other events.
This year, the cruise went virtual, and my excuses went out the window. I registered to do a poetry show, promising that I would ‘recite some poems that rhyme, some that don’t, and maybe even sing a few things. Topics may include science, love, poop, and life.’ I came to realise I could not only read my poems from my screen to avoid any nervousness about remembering them, but I could also share my screen. There are projectors on the cruise, but they are in short supply, so I wouldn’t request one for just one or two poems in a shadow event. On the virtual cruise, I could share whatever I wanted, including things from the internet, which wouldn’t be reliably available on a ship. And I could use props that I wouldn’t bother to bring on a cruise. So I did! I made slides for poems that worked best with visual aids, I showed off my rhyming dictionary, and I closed with a cover song that requires a video. And of course, I recorded everything. Here’s my show!
I also performed a few poems at the open mic — hastily-adapted versions of a poem I wrote for the Vienna open mic Open Phil, and the one I opened my show with about the differences between the real cruise and the virtual one. Joey Marianer and Phil Conrad (who also hosts Open Phil) hosted the open mic, so the open mic videos are on Joey’s channel.
It sure was weird watching Joey upload videos, when usually I’m spending most of my free time from March to May processing videos from the cruise. On the subject of cruise videos, the videos of the official events will allegedly only be up until May 1, so watch them while you can!
NiceWriter: Artificially sweeten your text
Posted by Angela Brett in NastyWriter on February 10, 2021

A few years ago I noticed a linguistic habit of Twitter user Donald Trump, and decided to emulate it by writing an app that automatically adds insults before nouns — NastyWriter. But he’s not on Twitter any more, and Valentine’s Day is coming up, so it’s time to make things nicer instead.
My new iOS app, NiceWriter, automatically adds positive adjectives, highlighted in pink, before the nouns in any text entered. Most features are the same as in NastyWriter:
- You can use the contextual menu or the toolbar to change or remove any adjectives that don’t fit the context.
- You can share the sweetened text as an image similar to the one in this post.
- You can set up the ‘Give Me a Compliment’ Siri Shortcut to ask for a random compliment at any time, or create a shortcut to add compliments to text you’ve entered previously. You can even use the Niceify shortcut in the Shortcuts app to add compliments to text that comes from another Siri action.
- If you copy and paste text between NiceWriter and NastyWriter, the app you paste into will replace the automatically-generated adjectives with its own, and remember which nouns you removed the adjectives from.
The app is free to download, and will show ads unless you buy an in-app purchase to remove them. I’ve made NiceWriter available to run on M1 Macs as well, though I don’t have one to test it on, so I can’t guarantee it will work well.
I’ll post occasional Niceified text on the NastyWriter Tumblr, and the @NiceWriterApp Twitter.
NastyWriter 2.1
In the process of creating NiceWriter, I made a few improvements to NastyWriter — notably adding input and output parameters to its Siri Shortcut so you can set up a workflow to nastify the results of other Siri Shortcuts, and then pass them on to other actions. I also added four new insults, and fixed a few bugs. All of these changes are in NastyWriter 2.1.
That’s all you really need to know, but for more details on how I chose the adjectives for NiceWriter and what I plan to do next, read on.
Read the rest of this entry »Top 35 Adjectives Twitter user @realdonaldtrump uses before nouns
Posted by Angela Brett in News on December 3, 2020
Edit: As of 8 January, 2021, @realdonaldtrump is no longer a Twitter user, but he was at the time of this post.
Version 2.0.1 of my iOS app NastyWriter has 184 different insults (plus two extra special secret non-insults that appear rarely for people who’ve paid to remove ads 🤫) which it can automatically add before nouns in the text you enter. “But Angela,” I hear you not asking, “you’re so incredibly nice! How could you possibly come up with 184 distinct insults?” and I have to admit, while I’ve been known to rap on occasion, I have not in fact been studying the Art of the Diss — I have a secret source. (This is a bonus joke for people with non-rhotic accents.)
My secret source is the Trump Twitter Archive. Since NastyWriter is all about adding gratuitous insults immediately before nouns, which Twitter user @realdonaldtrump is such a dab hand at, I got almost all of the insults from there. But I couldn’t stand to read it all myself, so I wrote a Mac app to go through all of the tweets and find every word that seemed to be an adjective immediately before a noun. I used NSLinguisticTagger, because the new Natural Language framework did not exist when I first wrote it.
Natural language processing is not 100% accurate, because language is complicated — indeed, the app thought ‘RT’, ‘bit.ly’, and a lot of twitter @usernames (most commonly @ApprenticeNBC) and hashtags were adjectives, and the usernames and hashtags were indeed used as adjectives (usually noun adjuncts) e.g. in ‘@USDOT funding’. One surprising supposed adjective was ‘gsfsgh2kpc’, which was in a shortened URL mentioned 16 times, to a site which Amazon CloudFront blocks access to from my country.
For each purported adjective the app found, I had a look at how it was used before adding it to NastyWriter’s insult collection. Was it really an adjective used before a noun? Was it used as an insult? Was it gratuitous? Were there any other words it was commonly paired with, making a more complex insult such as ‘totally conflicted and discredited’, or ‘frumpy and very dumb’? Was it often in allcaps or otherwise capitalised in a specific way?
But let’s say we don’t care too much about that and just want to know roughly which adjectives he used the most. Can you guess which is the most common adjective found before a noun? I’ll give you a hint: he uses it a lot in other parts of sentences too. Here are the top 35 as of 6 November 2020:
- ‘great’ appears 4402 times
- ‘big’ appears 1351 times
- ‘good’ appears 1105 times
- ‘new’ appears 1034 times
- ‘many’ appears 980 times
- ‘last’ appears 809 times
- ‘best’ appears 724 times
- ‘other’ appears 719 times
- ‘fake’ appears 686 times
- ‘American’ appears 592 times
- ‘real’ appears 510 times
- ‘total’ appears 509 times
- ‘bad’ appears 466 times
- ‘first’ appears 438 times
- ‘next’ appears 407 times
- ‘wonderful’ appears 375 times
- ‘amazing’ appears 354 times
- ‘only’ appears 325 times
- ‘political’ appears 310 times
- ‘beautiful’ appears 298 times
- ‘fantastic’ appears 279 times
- ‘tremendous’ appears 270 times
- ‘massive’ appears 268 times
- ‘illegal’ appears 254 times
- ‘incredible’ appears 254 times
- ‘nice’ appears 251 times
- ‘strong’ appears 250 times
- ‘greatest’ appears 248 times
- ‘true’ appears 247 times
- ‘major’ appears 243 times
- ‘same’ appears 236 times
- ‘terrible’ appears 231 times
- ‘presidential’ appears 221 times
- ‘much’ appears 217 times
- ‘long’ appears 215 times
So as you can see, he doesn’t only insult. The first negative word, ‘fake’, is only the ninth most common, though more common than its antonyms ‘real’ and ‘true’, if they’re taken separately (‘false’ is in 72nd position, with 102 uses before nouns, while ‘genuine’ has only four uses.) And ‘illegal’ only slightly outdoes ‘nice’.
He also talks about American things a lot, which is not surprising given his location. ‘Russian’ comes in 111st place, with 62 uses, so about a tenth as many as ‘American’. As far as country adjectives go, ‘Iranian’ is next with 40 uses before nouns, then ‘Mexican’ with 39, and ‘Chinese’ with 37. ‘Islamic’ has 33. ‘Jewish’ and ‘White’ each have 27 uses as adjectives before nouns, though the latter is almost always describing a house rather than people. The next unequivocally racial (i.e. referring to a group of people rather than a specific region) adjective is ‘Hispanic’, with 25. I’m not an expert on what’s unequivocally racial, but I can tell you that ‘racial’ itself has nine adjectival uses before nouns, and ‘racist’ has three.
“But Angela,” I hear you not asking, “why are you showing us a list of words and numbers? Didn’t you just make an audiovisual word cloud generator a few months ago?” and the answer is, yes, indeed, I did make a word cloud generator that makes visual and audio word clouds, So here is an audiovisual word cloud of all the adjectives found at least twice before nouns in tweets by @realdonaldtrump in The Trump Twitter Archive, with Twitter usernames filtered out even if they are used as adjectives. More common words are larger and louder. Words are panned left or right so they can be more easily distinguished, so this is best heard in stereo.
There are some nouns in there, but they are only counted when used as attributive nouns to modify other nouns, e.g. ‘NATO countries’, or ‘ObamaCare website’.
NastyWriter 2.0.1
Posted by Angela Brett in NastyWriter on November 28, 2020

I came upon a secret stash of free time, so I finally put finishing touches on the Siri Shortcuts I’d added to NastyWriter, made the app work properly in Dark Mode, added the latest gratuitous insults harvested from Twitter (I’ll write another post about how I did that), and released it. Then somebody pointed out something that still didn’t work in Dark Mode, so I fixed that and a few related things, and released it again. Thus NastyWriter’s version number (2.0.1) is the reverse of what it was before (1.0.2.)

I added Siri Shortcuts to NastyWriter soon after iOS 12 came out, just to learn a bit about them. You can add a shortcut with whatever text you’ve entered, and then run the shortcut whenever you like to get a freshly-nastified version of the same text.
There’s also a ‘Give me an insult’ shortcut (which you can find in the Shortcuts app) which just gives a random insult, surrounded by unpleasant emoji.
As I added these soon after iOS 12 came out, they don’t support parameters, which are new in iOS 13. I may work on that next, so you’ll be able to nastify text on the fly, or nastify the output from another shortcut as part of a longer workflow.

Since Tom Lehrer recently released all his music and lyrics into the public domain, I took this opportunity to update the screenshots of NastyWriter in the App Store to show Tom Lehrer’s song ‘She’s My Girl’ where they had previously shown Shakespeare’s Sonnet 18. You can read a full nastification of this on the NastyWriter tumblr.

Things I forgot to blog about, part n+1: NanoRhymo #2
Posted by Angela Brett in NanoRhymo on January 21, 2020
In November 2018 I created NanoRhymo (inspired by NaNoWriMo), in which I wrote and tweeted a very short rhyming poem every day. I did the same thing in April 2019 for Global Poetry Writing Month. I started pretty late with NanoRhymo in 2019, and didn’t end up with a poem for each day of November, but I’ve started it again on January 1 and made up for the missing poems. In November, I mostly stuck to writing something based on a random rhyme from the rhyming dictionary I made, rhyme.science — either a new one I’d found each day, or one generated earlier for the @RhymeScience twitter feed. In January, I’ve often been inspired by other things.
I’ll continue writing a NanoRhymo a day for as long as I can. Here’s what I’ve written so far:
Day 1, inspired by the rhymes later, translator, and (in non-rhotic accents) convey to:
When you’ve got a thought to convey to
many mortals, sooner or later,
then you ought to get a translator.
Day 2, inspired by the rhyme chunked and bunked, and the folk etymology of ‘chunder’:
Sailors lying in their bunks
would shout “Ahoy there, mate… watch under!”
and then let loose digested chunks
on hapless seamen sleeping under.
That’s why even now, down under,
[I am lying; truth debunks!]
some refer to puke as chunder.
[This is half-digested junk
Please accept my weak apology
and not this doubtful etymology.]
Day 3, inspired by a friend’s experience learning flying trapeze:
My friend Robert Burke tried the flying trapeze.
It meant lots of work mulling hypotheses,
and then much amusement and catching catchees,
to end up all bruised on the backs of the knees.
Day 4, inspired by the rhyme spermicides and germicide’s:
Looking at small things up close and myopically,
one might prevent overgrowth with a germicide.
But looking at large things afar, macroscopically,
one must prevent unchecked growth with a spermicide.
Day 5, inspired by the rhyme explainable and containable:
As soon as the bug is explainable,
we can hope that it might be containable,
and our neural nets will be retrainable,
and our code is so very maintainable
that this progress is surely sustainable!
Day 6, inspired by the rhyme freaking and unspeaking:
Mouth agape, stunned, unspeaking
Eyes wide open, silent freaking,
What could this strange vision be?
a music video, on MTV?!
Day 7, inspired by the rhyme trekked and collect:
Over much terrain they trekked;
specimens they did collect,
to show just how diverse life was
before we killed it off, just ‘cause.
Day 8, inspired by the rhyme interleaved and peeved:
If rhyming couplets leave you peeved,
here, I tried ABAB.
Now the rhymes are interleaved!
This rhyme and rhythm’s reason-free.
Day 9, a rewrite of Day 8 that can be sung to a possibly recognisable tune:
If rhyming couplets leave you peeved,
Then try to make them interleaved
Or don’t, and then just let the hate flow through ya
Just AAB, then CCB
This rhyme and rhythm’s reason-free.
At least it can be sung to Hallelujah.
The most Hallelujest Joey Marianer sang that version:
Day 10, inspired by the rhyme platitudes and latitude’s, and my general dislike of casual hemispherism:
I’m just fine with the end-of-year platitudes —
“Happy Holidays”, nice and generic,
but please, be inclusive of latitudes:
“Happy Winter” is too hemispheric!
Day 11, another Hallelujah, inspired by Joey’s singing of the previous Hallelujah:
A kitchen scale, a petrol gauge,
a cylinder, a final page
will tell you up to what things have amounted.
An abacus, a quipu string,
some tally sticks, to always sing,
are all things on which Joey can be counted.
Day 12, inspired by the rhyme deprecations and lamentations, some deprecated code I was removing from the software I develop at work, and also complaints about macOS Catalina dropping support for 32-bit applications. I imagine it sung to the tune of Camp Bachelor Alma Mater:
Hear the coders’ lamentations
over apps that will not run,
due to years-old deprecations,
updates that they’ve never done.
Day 13, inspired by the rhyme whoop’s and sloop’s, and the tradition on JoCo Cruise of ending the final concert with the song Sloop John B:
Have some more whoops on me,
hearing the Sloop John B
as JoCo Cruise comes to an end.
You still have all night.
Hang loose, or sleep tight.
Well, we feel so broke up
but you’ll stay my friend.
Day 14, to the tune of Morning Has Broken:
Something is broken;
look at that warning!
Unbalanced token.
Unknown keyword.
Raise the exceptions.
Erase all the warnings.
Raze preconceptions wrongly inferred.
Day 15, inspired by Hilbert’s paradox of the Grand Hotel:
The rooms are all full for as far out as they can see;
such a big guest house to fill, but oh well.
What’s this? Nonetheless, there’s a sign saying vacancy!
There’s always more room at the Hilbert hotel.
Day 16, inspired by the rhyme feeling’s and ceilings, and the song Happy, by Pharrell Williams:
Clap along if you feel like a room without a roof. 👏
Please applaud if you think you’re a chamber with no ceiling. 👏
Clap along If you feel like happiness is the truth. 👏
Please applaud if you think there’s veracity in good feelings. 👏
For day 17, I let Pico, emacs, ed, vi count as the NanoRhymo, even though it does not mention the text editor nano.
November ended with no more rhymes, but I started it up again on January 1, simply because I was inspired to, and I continued to get ideas every day since. I’m not promising to keep this up daily all year (indeed, I promise not to keep it up during MarsCon and JoCo Cruise 2020) but I’ll post NanoRhymi whenever I feel inspired to.
Day 18 (on January 1, 2020) was inspired by the rhyme unworthy and incur the:
Don’t worry that you might incur the
sentence, “That person’s unworthy.”
Just try what you wish, and try plenty,
and have a great year twenty-twenty.
Day 19, inspired by the rhyme verb and kerb, but using the North American ‘curb’ spelling because it’s closer to the verb derived from the noun:
If you’d punch down, or kick to the curb
for verbing a noun, or nouning a verb,
researching the past will amount your disturb.
So many of the words we used today, including some in that poem, were once strictly parts of speech other than the ones they’re used as without a second thought today, and people objected to their shifts in usage just as they object to all manner of language change today.
Day 20, inspired by the rhymes occur to, Berta, and (in non-rhotic accents) subverter:
If it were to occur to Berta the subverter to hurt Alberta,
she’d prefer to assert a slur to refer to her to stir internal murder.
(Stones break bones but names make shame — heals more slowly, hurts the same.)
Day 21, inspired by the rhyme unconcealed and unpeeled:
While you’re growing in the field,
all your goodness is concealed,
till some lovely creature picks you,
doesn’t think they have to fix you,
lets you chill, let down your shield;
then, when you are fully peeled,
your sweetest inner self revealed,
that cunning rascal bites and licks you.
Day 22, inspired by the rhymes for fish, dwarfish, and (maybe in some non-rhotic accents with the cot-caught merger) standoffish, the ‘teach a man to fish‘ metaphor, and of course, my own poem, They Might Not Be Giants:
If a person’s always asking for fish,
don’t give them one, and go away, standoffish.
Teach techniques that they’ll expand on.
Be the shoulders they will stand on.
Not a giant — generous and dwarfish.
And then the same thing as a limerick:
There once was a man asking for fish,
who got one from someone standoffish.
Then shoulders to stand on
and tricks to expand on,
were given by someone quite dwarfish.
Day 23, inspired by… certain kinds of transphobic people, I guess:
Some folk seem to be offended
by the thought the queerly gendered
might themselves become offended
when they’re purposely misgendered,
so they’ve boorishly defended
all the hurt that they intended
towards the “easily offended”
who are “wimps” to try to end it.
Day 24, a double dactyl inspired by a conversation with someone who’s considering hormone therapy with one aim being a reduction of schlength, during which we noticed that ‘endocrinologist’ is a double dactyl, and also inspired by Paul and Storm’s habit of calling Jonathan Coulton ‘Dr. Smallpenis‘ (with the ‘e’ unstressed) which began on JoCo Cruise 2013:
Dr. Jon Smallpənis,
Endocrinologist,
helps you to shrink all the
parts that aren’t you.
Piss off, dysphoria!
Spironolactone could
soon make you tinkle the
whole darn day through.
Spironolactone is a medication that blocks the effect of testosterone, which as a side effect can increase urinary frequency.
Day 25, inspired by the rhyme eleven words and heavenwards:
Dear Father, a prayer I remember, amen.
Another, sincere from a vendor, again.
As if by reciting just ten or eleven words
I’ll lift myself quite transcendentally heavenwards.
Day 26, inspired by what I was actually told at my first comprehensive annual checkup:
Sit up straight!
Lose some weight!
Take these pills!
Cure your ills!
Your heart is beating!
You’re good at breathing!
With those two habits kept up,
We’ll see you at the next year’s checkup.
They really did seem impressed by how well I could breathe. I wasn’t too good at it when I started, but I have been practising my whole life, and if I’m good then I may as well continue the habit.
Day 27, inspired by this Smarter Every Day video about activating smart speakers using laser light instead of sound:
Here’s a technique that is quite underhand
to beam gadgets speaking they might understand,
and give an unsound and light-fingered command.
This one works best in accents without the trap-bath split, so that ‘command’ rhymes with ‘understand’ and ‘underhand’.

Day 28, inspired by a container of those little dowel things to hold up shelves, which was labelled ‘Safety trans.’, and the song The Safety Dance, by Men Without Hats. This parody is presumedly to be sung by Women and Nonbinary People Without Hats:
You can trans[ition] iff you want to.
You can leave your assigned gender behind.
‘Cause your assigned gender ain’t trans and if you don’t trans[ition],
Well your assigned gender stays assigned.
Day 29, inspired by a video about Jason Padgett, who survived a vicious beating to end up with (among less attractive brain issues) savant skills and a kind of synaesthesia:
Acquired savants suffer pain,
to wake up with a better brain.
Get a bump, or have a seizure,
then end up with synaesthesia —
not the grapheme-colour kind,
rather, an amazing mind!
Day 30 is a version of day 29’s poem which can be sung to the tune of Hallelujah, with a second verse reminding people that synaesthesia is actually pretty common, affecting about 4.4% of people, (I have the grapheme-colour kind) and doesn’t necessarily confer superpowers:
Acquired savants suffer pain,
to wake up with a better brain
by healing from an injury or seizure.
They sometimes get amazing minds
associating different kinds
of input in a thing called synaesthesia.
Synaesthesia, synaesthesia, synaesthesia, synaesthesia.
But synaesthetes are everywhere,
not magical, or even rare.
It doesn’t make them smart or make things easier.
It just makes Thursday forest green,
or K maroon and 7 mean.
Your ‘the’-tastes-like-vanilla synaesthesia
Synaesthesia, synaesthesia, synaesthesia…
This refers to time-unit-color synaesthesia, grapheme-colour synaesthesia, ordinal linguistic personification (also known as sequence-personality synaesthesia), and lexical-gustatory synaesthesia, but there are many other kinds.
Day 31, a parody of ABBA’s Fernando for which I am deeply sorry:
Did you hear he goes commando?
I remember long ago another starry night like this.
In the firelight, commando,
he was wearing his new kilt and playing bagpipes by the fire.
I could hear his sudden screams
and sounds of mountain oysters sizzling in the fryer.
Day 32, inspired by two tweets I saw, each quoting the same tweet where someone had contrasted pictures of Prince Harry in the army with pictures of him with his wife, and claimed that getting out of the army and getting married was somehow emasculation caused by ‘toxic’ Hollywood feminism:
The two tweets happened to rhyme with each other and follow the same structure, from the ‘fellas, is it gay’ meme, so I put them together, and added a few lines:
Fellas, is is gay to have a wife?
Fellas, is it gay to be a human being with a life?
Fellas, is it gay to wear a suit?
Fellas, is it gay to dress to socialise instead of shoot?
(Fellas, is it toxic to be gay?
Fellas, why frame questions with a word she didn’t say?)
Day 33, another Hallelujah parody, inspired by Joey’s observation that NanoRhymo scans:
You want to practise writing verse.
The secret’s to be very terse.
You don’t have to try hard, just have to try mo’.
You write some dogg’rel every day
and some you’ll toss, but some will stay.
An atom at a time; it’s NanoRhymo.
NanoRhymo, NanoRhymo, NanoRhymo, NanoRhymo.
Day 34, inspired by a Twitter thread which began with my friend Rob Rix expressing frustration with type inference, and one of his followers suggesting the term ‘type deference’:
https://twitter.com/quephird/status/1217968127419416576
I love when it complies,
regards me with deference,
and bravely compiles
my unguarded dereference.
Day 35, inspired by… tea. I feel so rich when I make a pot of tea and top it up all day, having unlimited tea without feeling like maybe it’s wasteful to be using my eighth teabag of the day:
If hot tea’s an oddity,
the tea bag’s your commodity,
but if you drink a lot of tea,
you should make a pot of tea.
(To add some boiling water t’
whenever you want hotter tea.)
Day 36, inspired by my efforts to write an AppleScript to copy all my NanoRhymi and GloPoWriMo poems from Notes into a spreadsheet in Numbers, which initially failed because I had accidentally addressed the script to Pages instead, and Pages don’t know sheet:
👩🏻💻Hello there! Your finest Greek corpus, to go!
👩🍳The what now? Not understand corpus, no no!
👩🏻💻The active Greek corpus, the frontmost, the first, display all the corpora you have; am I cursed?
👩🍳I’m sorry? Your question is Greek to me… how?
👩🏻💻Okay then, just show me your bookcases, now!
👩🍳Bookcases? I have none; you’ve made a mistake.
👩🏻💻Ah, frack! You’re no linguist! You’re actually the baker!
The spreadsheet, by the way, shows I’ve written about a hundred of these small poems in total so far, in the course of my NanoRhymo and GloPoWriMo stints. I haven’t gone through it checking for notes that didn’t contain completed poems, so I don’t know the exact number yet. In the next roundup of these things, I’ll probably start numbering them based on that total, rather than the ‘days’ of any particular run of them.
Day 37 (today, as I write this), a parody of Taylor Swift’s ‘Shake it Off‘ inspired by another tweet by Rob Rix, in which he notices that a calculation done in Spotlight Search which should give the result zero does not, and remarks, ‘computers gonna compute’:
’Cause the bugs are are gonna ship, ship, ship, ship, ship
And an on bit is a blip, blip, blip, blip, blip
I’m just gonna flip, flip, flip, flip, flip
I flip it off ⌽, I flip it off 🖕🏻
That’s all of the NanoRhymi I have so far; I’ll post more here occasionally, but follow me on Twitter if you want to see them as they happen.
∎
In other news, please consider buying one or all of the MarsCon Dementia Track Fundraiser albums, which are albums of live comedy music performances from previous MarsCon Dementia Tracks, sold to raise funds for the performers’ hotel costs for the next one. The 2020 fundraiser album (with the concerts from MarsCon 2019) is nearly four hours of live comedy music for $20, and includes my performances of Chicken Monkey Duck and Why I Perform at Open Mics.
For yet more music, Joey and I will be participating in round #16 of SpinTunes, a songwriting competition following in the footsteps of Masters of Song Fu. I’ve been following it since the beginning, but never had the accompaniment to actually enter.

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported License.
Please tell me if you do something cool with it.

