Posts Tagged AppleScript
Etymological family trees
Posted by Angela Brett in News on December 30, 2021
A while ago I found a post about Surprising shared word etymologies, where the author had found words with common origins (according to Etymological Wordnet) which had the most dissimilar meanings (according to GloVe: Global Vectors for Word Representation.) I loved the post, but my main takeaway from it was the The History of English Podcast, linked in the Further reading section. I immediately started listening to that, in reverse order (that’s just the easiest thing to do in the Apple Podcasts app. Back when podcasts were in iTunes, I used to listen to all my podcasts on shuffle, so if you like order, this is an improvement) starting from Episode 148. I’ve since finished it and started listening to something else before I go back for the newer episodes. I was in it for the English, but I also learnt lot more history than I expected to.
The diagrams
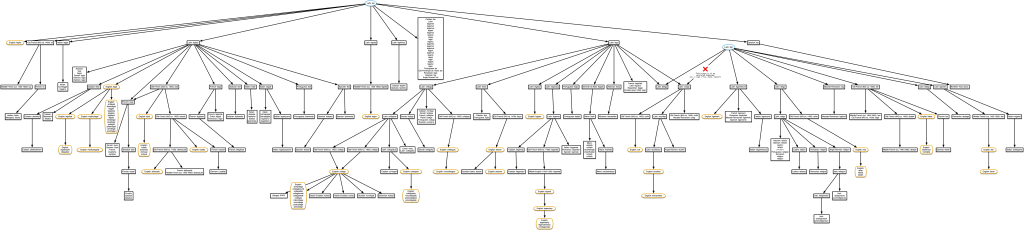
Back in October, hearing about how yet another absurd list of words all derived from the same root word (I think in this case it was bloom, flower, phallus, bollocks, belly, flatulence, bloat, fluid, bladder, blow, and blood from episode 62) I decided I couldn’t just listen to these ridiculous linguistic family trees any more; I had to see them. As you might have seen in previous posts, my go-to for creating that kind of diagram is using AppleScript to control OmniGraffle. So I wrote an AppleScript to make tree diagrams showing words that are all derived from the same root word(s) as a given word. Before I bore you with the details, I’ll show you a little example. This is what it gave when I asked for the English word ‘little’.

The root word is in a blue oval, the words in the same language as the one I asked about (in this case, English) are in brown rounded rectangles, and the words in other languages are in black rectangles. I thought about having a different colour and shape for each language, and a legend, but decided to keep things simple for now.
Image descriptions
The script also generates a simple image description, which I’ve used in the caption. I intended it for use as alt text, but some of these diagrams are difficult to read at the size shown, so even people who don’t use screen readers can benefit from the description. You can also click on any diagram for a full-sized pdf version.
It doesn’t describe the entire structure of the tree (I’m trying not to get distracted researching nice ways to do that for arbitrary trees!) but it’s probably better than nothing. It only lists the words in the language you asked about (assuming that is English), since English screen readers likely wouldn’t read the other ones correctly anyway. It might be cool to autogenerate sound files using text-to-speech in voices made for the other languages and attach those to the nodes to enrich the experience when navigating through them in OmniGraffle or some other format it can export, but that’s a project for another day.
On the subject of accessibility, I’m happy that the History of English Podcast provides transcripts, so I can easily find the episodes relevant to some of these diagrams.
Simplifying the diagrams
Sometimes the diagrams get crowded when a lot of words are derived from another word in the same language, or a lot of other languages derived words from the same word. I wrote a second script to group words into a single node if they’re all derived from the same word, don’t have any words derived from them, and are all in the same kind of shape as the word they’re derived from. That last constraint means that if you searched for an English word, English words all derived from the same English word will be grouped together, and non-English words all derived from the same non-English word will be grouped together, but English words derived from a non-English word (or vice versa) are not, because I think they are more interesting and less obvious.
It’s actually quite satisfying to watch this script at work, as it deletes extra nodes and puts the text into a single node, so I made a screen recording of it doing this to the diagram of the English word ‘pianoforte’. I’m almost tempted to add pleasant whooshing sound effects as it sweeps through removing nodes.
The data
Words and their etymologies
The data from Etymological Wordnet comes as a tab-separated-values file. AppleScript is best at telling other applications what to do, not doing complicated things itself, so I left all the tsv parsing up to Numbers, and had my script communicate with Numbers to get the data. The full data has too many rows for Numbers to handle, but I only needed the rows with the type rel:etymology, so I created a file with just those rows using this command:
grep 'rel:etymology' etymwn.tsv > etymology.tsv
then opened the resulting etymology.tsv file in Numbers, and saved it as a numbers file. This means missing out of a few etymological links (some of which are mentioned below), but it’s good enough for most words.
The file simply relates words to the words in the first column to words they are derived from in the third column.
Languages
Each word is listed with a language abbreviation, a colon, then the word. The readme that comes with the Etymological Wordnet data says, ‘Words are given with ISO 639-3 codes (additionally, there are some ISO 639-2 codes prefixed with “p_” to indicate proto-languages).’ However, I found that not all of the protolanguage codes used were in ISO 639-2, so I ended up using ISO 639-5 data for protolanguages and ISO 639-3 data for the other languages, both converted to Numbers files and accessed the same way as the etymology data.
The algorithm
The script starts by finding the ultimate root word(s) of whatever word you entered. It finds the word each word is immediately derived from, then finds the word that was derived from, and so on, until it gets to a word that doesn’t have any further origin. Some words have multiple origins, either because they’re compound words, homographs, or just were influenced by multiple words, so sometimes the script ends up with several ultimate root words. This part of the script ignores origins that have hyphens in them, because they’re likely common prefixes or suffixes, and if you’re looking up ‘coagulate’, you’re unlikely to want every single word derived from a Latin word with a prefix ‘co-‘.
For each of the root words, the script finds all words derived from it, and all words derived from those, and so on, and adds them to the diagram.
The code
In case you want to try making your own trees, I’ve put the AppleScripts and the Numbers sheets used for this in a git repository. It turns out having the version history is not terribly useful without tools to diff AppleScript, which is not plain text. It is possible to save AppleScript as plain text, but I didn’t do that in the beginning, so the existing version history is not so useful. It looks like AS Source Diff could help.
There are a lot of frustrating things about AppleScript when you’re used to using more modern programming languages. Sometimes that’s part of the fun, and sometimes it’s part of the not-fun.
Trees from Surprising Shared Etymologies
I tried making diagrams of some of the interesting related words mentioned in The History of English Podcast, such as the one with flower, bollocks, phallus and blood mentioned earlier, but the data usually didn’t go back that far. So I tried the ones mentioned in the Surprising shared etymologies post, because I knew they were found in the same data. In several cases I found the links didn’t actually hold up, as the words were descended from unrelated homonyms. I’ve done my best to figure out which parts of these trees are correct, but can’t guarantee I got everything right, so take this information with a grain of research.
“piano” & “plainclothed”
This was a bit of a puzzle, because there is actually no origin given in the data for English word ‘piano’, although it is given as the origin of many words in other languages. But their example in the ‘datasets’ section shows English: pianoforte, so I used that instead.
I could have added a row to the spreadsheet linking English ‘pianoforte’ with English ‘piano’, and then the many words in other languages that derive from English ‘piano’ would have shown in the diagram as well. Click on the diagram for a pdf version.

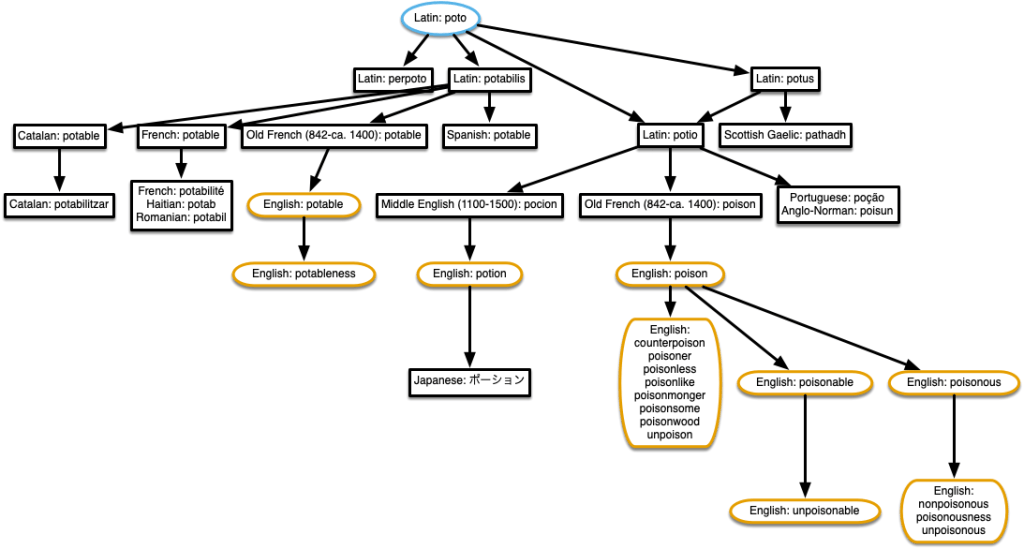
“potable” & “poison”
Also potion! According to the data, Latin potio is derived both from Latin poto, and from Latin potus, which is itself derived from Latin poto. The word is its own niece! I had to make a change to the script to ensure there wouldn’t be double connections in this case.
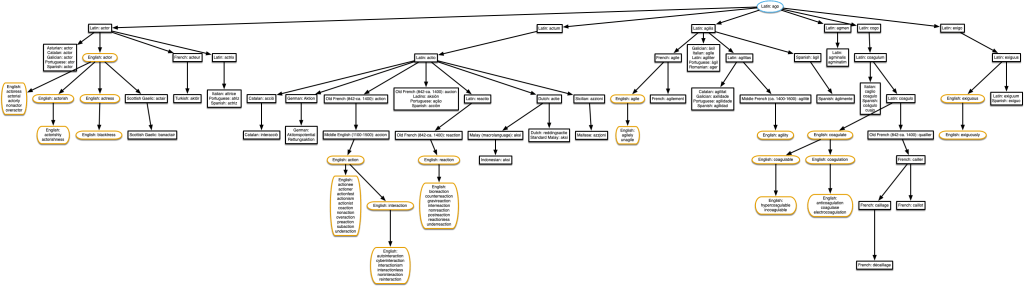
“actor” & “coagulate”
Agile and exiguous, too! It’s starting to get a bit complicated.
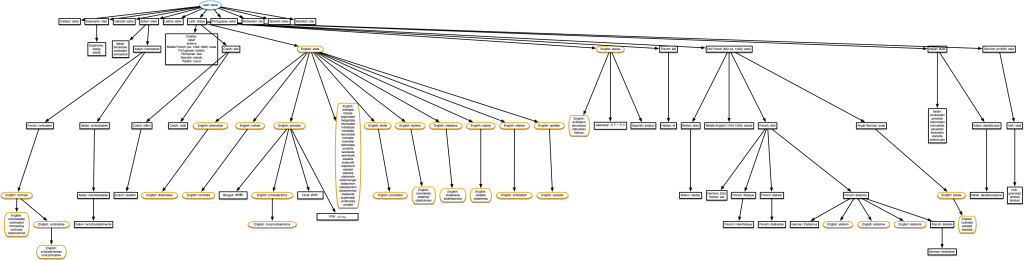
“estate” & “contrast”
This tree also includes ‘prostate’, but only ‘pro-state’ (meaning favouring the government) derives from English ‘state’ as shown here. Prostate the body part is actually related, but only if we go back to the Proto-Indo-European root *sta-, which is not in the Etymological Wordnet data. Since the data doesn’t distinguish between the two meanings of ‘prostate’, this tree erroneously includes prostatectomy and cryoprostatectomy, a procedure I was happier not knowing about.
If you think it’s surprising that ‘estate’ and ‘contrast’ are related, have a look at other words derived from *sta-. Understand, obstetrics, Taurus, Kazakhstan… if Etymological Wordnet had that data, this tree would resemble Pando.
“pay” & “peace”
This one comes up in episode 59 of the podcast — the word ‘pay’ literally meant ‘make peace’. It’s not too hard to imagine how paying someone would pacify them. The diagram is incorrect though. ‘Peace’ is shown as being derived from Middle English pece. This is actually the source of ‘piece’, but not ‘peace’. As far as I can tell, pece (and therefore also ‘piece’) shouldn’t even be in this tree. The word ‘peace’ is derived from Middle English pees, near the middle of the diagram, so it is still related to ‘pay’.

“cancer” & “cancel” & “chancellor”
As explained in episode 99 of The History of English Podcast, chancellor is just the Parisian French version of the Norman French canceler. The word ‘cancel’ didn’t come from ‘canceler’, though — ‘cancel’ and ‘chancellor’ both come from a word meaning lattice, whether the lattice a chancellor stands behind, or that of crossing something out to cancel it. The same word also give rise to ‘incarcerate’, but that link is not in the data.
As far as I can tell, these are not actually related to the English word ‘cancer’, though. There are two unrelated Latin words ‘cancer’, one meaning ‘lattice’, and the other meaning ‘crab’, and thus crab-like cancer tumours.

“fantastic” & “phenotype”
This also shows that ‘craptastic’ is related to ‘phasor’. Sometimes the best things about these are the lists of derivative slang words.

“college” & “legalize”
Also ‘cull’, ‘legend’, and ‘colleague’.
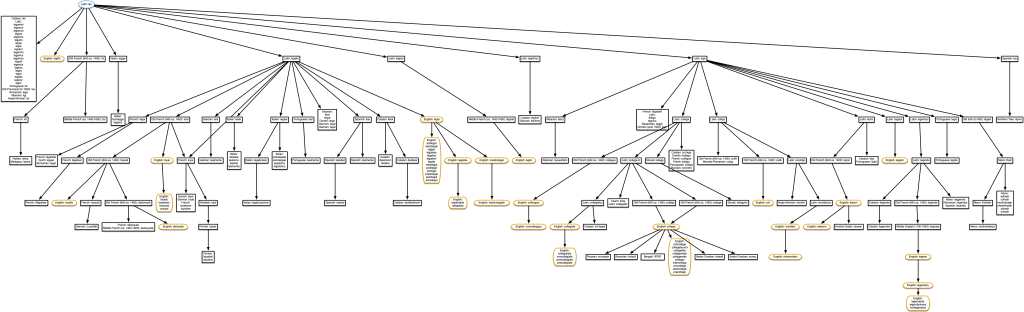
“lien” & “ligament”
‘Cull’ should not be in this diagram, as it’s related to a different homonym of Latin colligo. See the ‘Limitations‘ section below.

“journal” & “journey”
Surprising shared word etymologies says:
While it seems like “journal” and “journey” should be close cousins, their nearest common ancestor is in fact quite old – the Latin “diurnus”, meaning “daily”.
This seems about right from the data, and I’m surprised they didn’t both come from the Old French jor. My dictionary of French etymology doesn’t list the French versions of either word.

This is the tree I get if I start from the word ‘journal’. If I start with ‘journey’, it shows that Latin diurnum is also given as an origin of Old French jor, but this adds a lot of complication to the tree and only one extra English word, ‘abatjour’.
“educate” & “subdue”
I’m not sure how they got these two, to be honest. They may indeed be related, if, as etymonline says, subdue came from the same root as subduce, and subduce and educate came from Proto-Indo-European *deuk- (or *dewk-, as wiktionary spells it). There’s a lot about other words from that root (not including ‘subdue’) in episode 85 of the podcast.
I don’t know how they got this from the Etymological Wordnet data, though. Etymological Wordnet was extracted from an older version of wiktionary, and it doesn’t have very many Proto-Indo-European roots. The post says that ‘subdue’ comes from the latin subduco, meaning ‘lead under’. But even looking at all the data (not just the rows with ‘rel:etymology‘), ‘subdue’ is only linked to other English words. Perhaps they were looking at ‘subduce’ instead.
The post also says they both come from Latin duco. If I look at all the data, I can get to Latin duco from ‘educate’ (via Latin educatio and educo.) But looking more closely at that link on wiktionary (the source of Etymological Wordnet’s data) it seems there are two meanings of Latin educo, one coming from Latin duco and one coming from Latin dux, and it’s the dux origin that seems more relevant to education. However Proto-Indo-European *deuk- is the hypothetical source of dux, so that’s how it relates to subdue.
I’m getting a bit lost following these words around wiktionary and etymonline. I believe they’re related, but I’m not sure if they’re related via Latin duco, and I haven’t a clue how the relationship was found in the Etymological Wordnet data (I should probably read and/or run their ruby code to find out), so I can’t generate even an erroneous family tree of it.
Limitations
Did you notice that the word ‘cull’ shows up in both the tree for ‘college’ and the one for ‘ligament’? Does that mean that ‘ligament’ is also related to ‘college’? Nope. The issue here is that the Latin colligo has two distinct meanings with different origins, one via Latin ligo, and one via Latin lego. ‘cull’ derives from the ‘bring together’ meaning of colligo, which derives from lego, so it’s actually not related to ‘ligament’. Only one origin for colligo is shown on each of these two trees, since neither ‘college’ nor ‘ligament’ are derived from colligo, so the script only got to colligo when coming down from one of the ultimate root words, rather than when going up from the search word. But if we create a tree starting with the word ‘cull’, it gets both origins and the resulting tree makes it look like ‘college’ and ‘ligament’ are related.
Since the data only has plain text for each word, there’s no way for the script to know for sure that colligo isn’t one word with multiple origins (like ‘fireside’ is), but actually two separate words with different origins. And there’s no way for it to know which origin for colligo happens to be the one that ultimately gave rise to ‘cull’.
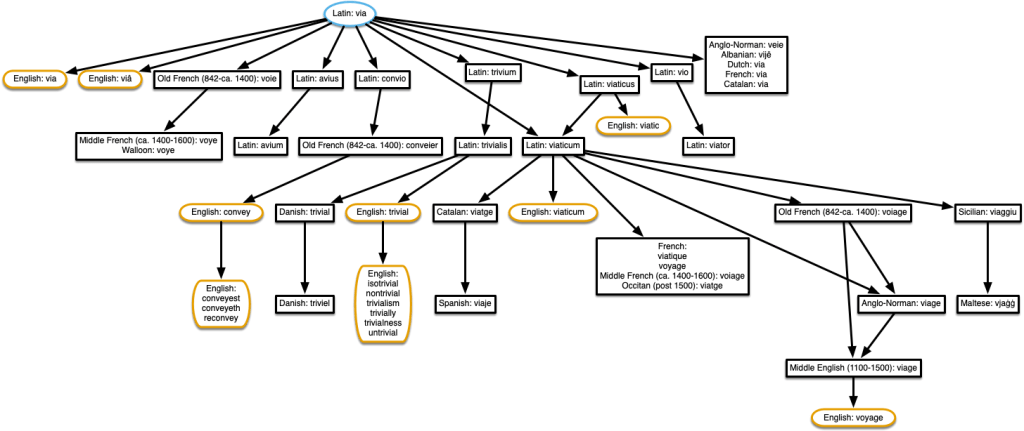
A trivial example
I’ll leave you with a tree I found while looking for a trivial example to show at the beginning. Here’s the tree for ‘trivial’. There are many more related words given in episode 37 of The History of English Podcast.
Audio Word Clouds
Posted by Angela Brett in News on August 1, 2020
For my comprehensive channel trailer, I created a word cloud of the words used in titles and descriptions of the videos uploaded each month. Word clouds have been around for a while now, so that’s nothing unusual. For the soundtrack, I wanted to make audio versions of these word clouds using text-to-speech, with the most common words being spoken louder. This way people with either hearing or vision impairments would have a somewhat similar experience of the trailer, and people with no such impairments would have the same surplus of information blasted at them in two ways.
I checked to see if anyone had made audio word clouds before, and found Audio Cloud: Creation and Rendering, which makes me wonder if I should write an academic paper about my audio word clouds. That paper describes an audio word cloud created from audio recordings using speech-to-text, while I wanted to create one from text using text-to-speech. I was mainly interested in any insights into the number of words we could perceive at once at various volumes or voices. In the end, I just tried a few things and used my own perception and that of a few friends to decide what worked. Did it work? You tell me.

Voices
There’s a huge variety of English voices available on macOS, with accents from Australia, India, Ireland, Scotland, South Africa, the United Kingdom, and the United States, and I’ve installed most of them. I excluded the voices whose speaking speed can’t be changed, such as Good News, and a few novelty voices, such as Bubbles, which aren’t comprehensible enough when there’s a lot of noise from other voices. I ended up with 30 usable voices. I increased the volume of a few which were harder to understand when quiet.
I wondered whether it might work best with only one or a few voices or accents in each cloud, analogous to the single font in each visual word cloud. That way people would have a little time to adapt to understand those specific voices rather than struggling with an unfamiliar voice or accent with each word. On the other hand, maybe it would be better to have as many voices as possible in each word cloud so that people could distinguish between words spoken simultaneously by voice, just as we do in real life. In the end I chose the voice for each word randomly, and never got around to trying the fewer-distinct-voices version. Being already familiar with many of these voices, I’m not sure I would have been a good judge of whether that made it easier to get used to them.
Arranging the words
It turns out making an audio word cloud is simpler than making a visual one. There’s only one dimension in an audio word cloud — time. Volume could be thought of as sort of a second dimension, as my code would search through the time span for a free rectangle of the right duration with enough free volume. I later wrote an AppleScript to create ‘visual audio word clouds’ in OmniGraffle showing how the words fit into a time/volume rectangle. I’ve thus illustrated this post with a visual word cloud of this post, and a few audio word clouds and visual audio word clouds of this post with various settings.
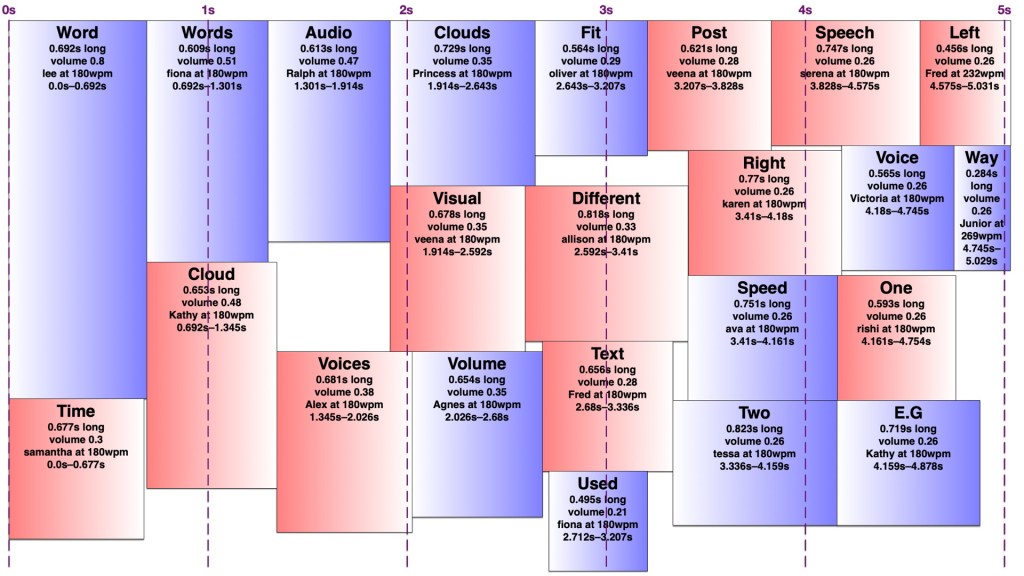
However, words in an audio word cloud can’t be oriented vertically as they can in a visual word cloud, nor can there really be ‘vertical’ space between two words, so it was only necessary to search along one dimension for a suitable space. I limited the word clouds to five seconds, and discarded any words that wouldn’t fit in that time, since it’s a lot easier to display 301032 words somewhat understandably in nine minutes than it is to speak them. I used the most common (and therefore louder) words first, sorted by length, and stopped filling the audio word cloud once I reached a word that would no longer fit. It would sometimes still be possible to fit a shorter, less common word in that cloud, but I didn’t want to include words much less common than the words I had to exclude.
I set a preferred volume for each word based on its frequency (with a given minimum and maximum volume so I wouldn’t end up with a hundred extremely quiet words spoken at once) and decided on a maximum total volume allowed at any given point. I didn’t particularly take into account the logarithmic nature of sound perception. I then found a time in the word cloud where the word would fit at its preferred volume when spoken by the randomly-chosen voice. If it didn’t fit, I would see if there was room to put it at a lower volume. If not, I’d look for places it could fit by increasing the speaking speed (up to a given maximum) and if there was still nowhere, I’d increase the speaking speed and decrease the volume at once. I’d prioritise reducing the volume over increasing the speed, to keep it understandable to people not used to VoiceOver-level speaking speeds. Because of the one-and-a-bit dimensionality of the audio word cloud, it was easy to determine how much to decrease the volume and/or increase the speed to fill any gap exactly. However, I was still left with gaps too short to fit any word at an understandable speed, and slivers of remaining volume smaller than my per-word minimum.
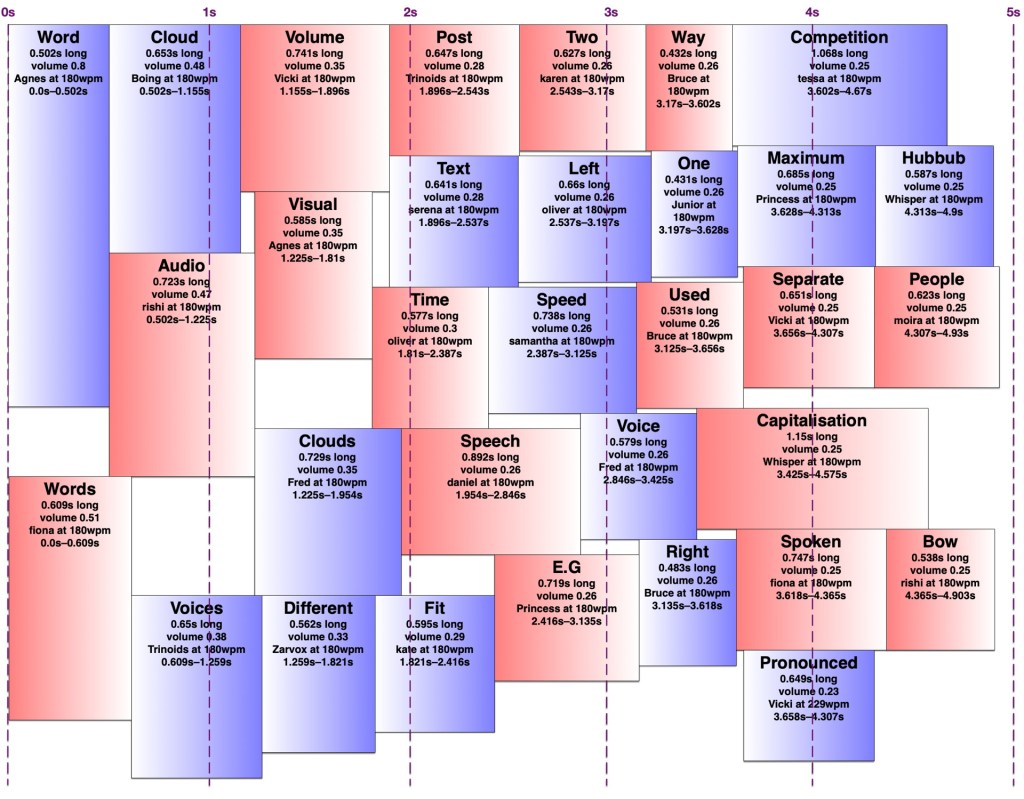
I experimented with different minimum and maximum word volumes, and maximum total volumes, which all affected how many voices might speak at once (the ‘hubbub level’, as I call it). Quite late in the game, I realised I could have some voices in the right ear and some in the left, which makes it easier to distinguish them. In theory, each word could be coming from a random location around the listener, but I kept to left and right — in fact, I generated separate left and right tracks and adjusted the panning in Final Cut Pro. Rather than changing the logic to have two separate channels to search for audio space in, I simply made my app alternate between left and right when creating the final tracks. By doing this, I could increase the total hubbub level while keeping many of the words understandable. However, the longer it went on for, the more taxing it was to listen to, so I decided to keep the hubbub level fairly low.
The algorithm is deterministic, but since voices are chosen randomly, and different voices take different amounts of time to speak the same words even at the same number of words per minute, the audio word clouds created from the same text can differ considerably. Once I’d decided on the hubbub level, I got my app to create a random one for each month, then regenerated any where I thought certain words were too difficult to understand.
Capitalisation

In my visual word clouds, I kept the algorithm case-sensitive, so that a word with the same spelling but different capitalisation would be counted as a separate word, and displayed twice. There are arguments for keeping it like this, and arguments to collapse capitalisations into the same word — but which capitalisation of it? My main reason for keeping the case-sensitivity was so that the word cloud of Joey singing the entries to our MathsJam Competition Competition competition would have the word ‘competition’ in it twice.
Sometimes these really are separate words with different meanings (e.g. US and us, apple and Apple, polish and Polish, together and ToGetHer) and sometimes they’re not. Sometimes these two words with different meanings are pronounced the same way, other times they’re not. But at least in a visual word cloud, the viewer always has a way of understanding why the same word appears twice. For the audio word cloud, I decided to treat different capitalisations as the same word, but as I’ve mentioned, capitalisation does matter in the pronunciation, so I needed to be careful about which capitalisation of each word to send to the text-to-speech engine. Most voices pronounce ‘JoCo’ (short for Jonathan Coulton, pronounced with the same vowels as ‘go-go’) correctly, but would pronounce ‘joco’ or ‘Joco’ as ‘jocko’, with a different vowel in the first syllable. I ended up counting any words with non-initial capitals (e.g. JoCo, US) as separate words, but treating title-case words (with only the initial letter capitalised) as the same as all-lowercase, and pronouncing them in title-case so I wouldn’t risk mispronouncing names.
Further work
A really smart version of this would get the pronunciation of each word in context (the same way my rhyming dictionary rhyme.science finds rhymes for the different pronunciations of homographs, e.g. bow), group them by how they were pronounced, and make a word cloud of words grouped entirely by pronunciation rather than spelling, so ‘polish’ and ‘Polish’ would appear separately but there would be no danger of, say ‘rain’ and ‘reign’ both appearing in the audio word cloud and sounding like duplicates. However, which words are actually pronounced the same depend on the accent (e.g. whether ‘cot’ and ‘caught’ sound the same) and text normalisation of the voice — you might have noticed that some of the audio word clouds in the trailer have ‘aye-aye’ while others have ‘two’ for the Roman numeral ‘II’.
Similarly, a really smart visual word cloud would use natural language processing to separate out different meanings of homographs (e.g. bow🎀, bow🏹, bow🚢, and bow🙇🏻♀️) and display them in some way that made it obvious which was which, e.g. by using different symbols, fonts, styles, colours for different parts of speech. It could also recognise names and keep multi-word names together, count words with the same lemma as the same, and cluster words by semantic similarity, thus putting ‘Zoe Keating’ near ‘cello’, and ‘Zoe Gray’ near ‘Brian Gray’ and far away from ‘Blue’. Perhaps I’ll work on that next.

I’ve recently been updated to a new WordPress editor whose ‘preview’ function gives a ‘page not found’ error, so I’m just going to publish this and hope it looks okay. If you’re here early enough to see that it doesn’t, thanks for being so enthusiastic!
Perhaps I will not post something interesting every day for the rest of the month, but I should at least try.
Posted by Angela Brett in Holidailies on December 17, 2014
Today I watched this video from the Virtual Linguistics Campus:
After that, I intended to analyse some sentences myself, but I got sidetracked thinking of simple ways to make diagrams like the ones in the video. It looks like there are apps and LaTeX packages to do something like it, but just for fun, I modified the AppleScript I wrote for diagramming monduckens to turn text like this:
Clause(Adverb(Perhaps) NP(Noun(you)) VP(Auxiliary(will) Adverb(never) Verb(find) NP(Determiner(a) Noun(job)) PP(Preposition(as) NP(Determiner(a) Noun(linguist))))) Clause(Conjunction(but) Noun(you) VP(Auxiliary(should) Adverbial(at least) Verb(try)))
into a tree like this in OmniGraffle:

Note that I am not sure if this is strictly correct (I think the adverbial ‘at least’ could have been broken into words, and the conjunction perhaps shouldn’t have been included in the second clause) but it’s how it is in the video. Redone with only rectangles (which is an option when running the script) and using the exact same Tree nester script the monducken diagrams did, this can then be turned into a rather oversized and misaligned version of the sentence with rectangles around the constituents:

I didn’t have a lot of time, so it’s pretty crude as yet, but it would be fairly simple to adjust the settings of the shapes to be more like what’s in the video. I’m posting it now in order to continue with Holidailies.
While we’re on the subject of grammar, The Doubleclicks have just covered a Tom Lehrer song about adverbs. I get this song in my head every single time I answer a ‘how’ question with an L-Y adverb, so I am very happy about the cover.
Six of Clubs: Birthday Monduckenen-duckenen
Posted by Angela Brett in Bäume, Writing Cards and Letters on December 21, 2012
First, check out Vi Hart‘s video about the Thanksgiving turduckenen-duckenen:
Now have a look at Mike Phirman‘s song, Chicken Monkey Duck:
Okay, there are monkeys instead of turkeys, and the mathematics isn’t quite as explicit, but it’s pretty similar, don’t you think? Now, let’s imagine that Mike Phirman is actually singing the recipe for a fractal turducken, or rather, monducken. You can imagine all the monkeys are turkeys if you’d rather eat the result than present it to some pretty thing to please them. (Note: Please do not kill any actual monkeys.) Monkeys, like birds, belong in trees, so I wrote an AppleScript to draw binary trees in OmniGraffle based on the text of the song. You can try it for yourself if you like; all you need is a Mac, OmniGraffle, and a text file containing some words. See the bottom of this post for links and instructions.
If Mike’s reading the binary tree recipe layer by layer, like the first example in Vi’s video, one possible tree for the first stanza of Chicken Monkey Duck looks like this, where the orange ovals are monkeys, blue hexagons are chickens and green clouds are ducks. You can click it (or any other diagram in this post) for a scalable pdf version where you can read the words:
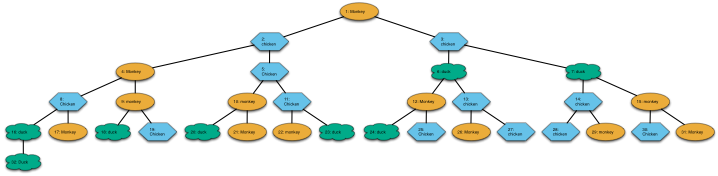
I added numbers so you can easily tell the chickens, monkeys and ducks apart and see which way to read the tree. It’s simple enough now, but the numbers will be useful for reading later trees which are not in such a natural reading order. This is called a breadth-first traversal of the tree, in case you’re interested. Now, what do birds and monkeys do in trees? They nest! So I wrote another script that will take any tree-like diagram in OmniGraffle and draw what it would look like if the birds, monkeys, or whatever objects they happen to be (the drawing is pretty abstract) were nested inside each other, just like the quails inside the chickens inside the ducks inside the turkey. This is what the monducken described by the first stanza of Chicken Monkey Duck, in the tree structure shown above, would look like:

The Monducken script allows using a different shape for each animal as redundant coding for colourblind people, even though it already chooses colours which most colourblind people should be able to distinguish. But that makes the nested version look a little messy, so here’s the above diagram using only ovals:

If you named this particular recipe in the other way, going down the left side of the tree and then reading each branch in turn in what is known as a pre-order traversal, it would be called a Monenmonenduckduckmon-monmonducken-enenmonduckmon-enmonduck-enduckmonducken-enmonen-duckenenmon-monenmon. It doesn’t sound nearly as nice as Turduckenailailenailail-duckenailailenailail because Mike Phirman didn’t take care to always put smaller animals inside large ones. I’m not holding that against him, because he didn’t realise he was writing a recipe, and besides, it’s his birthday. For reasons I’m not sure I can adequately explain, it’s always his birthday.
But what if I completely misunderstood the song, and his recipe is already describing the fractal monducken as a pre-order traversal, always singing a bird or monkey immediately before the birds and monkeys inside it? Well, don’t worry, I added a ‘pre-order’ option to the script, so you can see what that would look like. Here’s the tree:

and here’s how the actual birds/monkeys would look if you cut them in some way that showed all the animals, dyed them the correct colours, and looked through something blurry (here’s the version with different shapes):

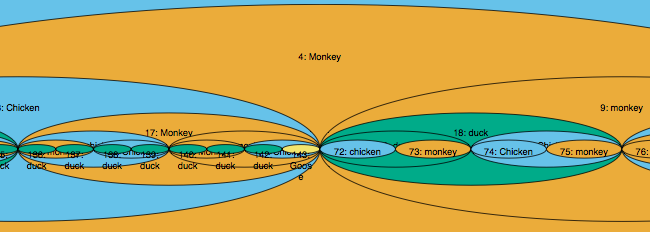
Okay, but that’s only the first stanza. What if we use the whole song? If we pretend the recipe is breadth-first, this just means all the extra monkeys and birds will be at the bottom levels of the tree, so the outer few layers of our monducken will be the same, but they’ll have a whole lot of other things inside them:


Here’s a close-up. Isn’t it beautiful?
If the entire song were treated as a pre-order monducken recipe, we’d still have the same monkey on the outside, but the rest would be quite different:


We could also read the birds and monkeys from left to right, as Vi did in her video. That’s what’s called an in-order tree traversal. But as delicious as they are mathematically, none of these orderings make much sense from a culinary perspective. Even if the monkeys were turkeys, it’s obvious that a nice big goose should be the outer bird. Vi suggested that herself. Of course, we could put the goose on the outside simply by reversing the song so it started with goose. But it would be much more fun and practical to pretend that Mike is naming the two inner birds before the one that contains them. This is called a post-order traversal, because you name the containing bird after the two birds or monkeys it will contain. It makes sense for a recipe. First you prepare a monkey (or turkey) and a chicken, then you immediately prepare a chicken and put them into it. You don’t have your workspace taken up with a whole lot of deboned birds you’re not ready to put anything into yet. Here’s one way the recipe could be done:

Note that no matter what kind of traversal we use, there are actually several ways the recipe could be interpreted. If Mike says ‘monkey chicken chicken’ you know you should take a monkey and a chicken and put them in a chicken. But if the next words are ‘monkey chicken’, do you take that stuffed chicken and a monkey and put them inside a chicken? Do you debone the monkey and the chicken and wait for the next bird to find out what to put them into? What if there’s no next bird? What if there’s only one more bird (let’s say a duck) and you end up with a stuffed chicken, a stuffed duck, and nothing to stuff them into? You’d have to throw one of them out, because obviously your oven only has room for one monducken. Assuming you want two things in each thing, and you don’t know how long the song’s going to be, the best way to minimise this kind of problem is to always take your latest stuffed thing and the next, unstuffed thing, and put them inside the thing after that. The worst that’ll happen is you’ll have to throw out one unstuffed bird or monkey. But then you end up with a really unbalanced monducken, with a whole lot of layers in one part and lonely debonely birdies floating around in the rest.
It helps to have a robot chef on hand to figure out how many full layers of monducken you can make without it being too asymmetric. Mine makes the trees completely balanced as deeply as possible, and then does whatever was easiest to program with the remaining birds and monkeys. In this case it was easiest for my program to stuff a whole lot of extra animals into that one monkey on the left. This is what it looks like, with the varied shapes this time. Luckily, geese are rectangular, so they fill your oven quite efficiently:

I like how you can see the explosion of duck radiating out from the inner left, engulfing all the other birds and monkeys before itself being swallowed by a goose. Such is life.
 If you would like to make diagrams like this yourself, there are two AppleScripts you can use. Both of them require OmniGraffle 5 for Mac, and if you want to make trees with more than 20 nodes you’ll probably need to register OmniGraffle.
If you would like to make diagrams like this yourself, there are two AppleScripts you can use. Both of them require OmniGraffle 5 for Mac, and if you want to make trees with more than 20 nodes you’ll probably need to register OmniGraffle.
The first is Monducken diagrammer, which you can download either as a standalone application (best if you don’t know what AppleScript is) or source code (if you want to tweak and critique my algorithms, or change it to use OmniGraffle Professional 5 instead of OmniGraffle 5.) Because it’s AppleScript, it works by telling other applications what to do, rather than doing things itself. So when you run it, TextEdit will ask you to open the text file you want to turn into a tree. Once you’ve opened one, OmniGraffle will start up (you may need to create a new document if it’s just started up) and ask you two things. First it will ask what kind of tree traversal the text file represents. Then it will ask you what kinds of shapes you want to use in your tree. You can select several shapes using the shift and command keys, just as you would for selecting multiple of just about anything on your Mac. Then you can sit back and watch as it creates some shapes and turns them into a tree.
The other one is Tree nester (standalone application/source code) You should have an OmniGraffle document open with a tree-like diagram in it (I suggest a tree generated using Monducken diagrammer; it has not been tested on anything else, and will probably just duplicate most of the shapes that aren’t trees or end up in an infinite loop if there’s a loopy tree) before you run this. It won’t ask any questions; it’ll just create a new layer in the front OmniGraffle document and draw nested versions of any trees into that layer.
If you’re looking at the source code, please bear in mind that I wrote most of this while on a train to Cologne last weekend, based on some code I wrote a while ago to draw other silly diagrams, and I really only dabble in AppleScript, and I forgot about the ‘outgoing lines’ and ‘incoming lines’ properties until I’d almost finished, so it probably isn’t the best quality AppleScript code. Not the worst either though. I welcome any tips.
How to gain super powers by sneaking into a particle physics lab
Posted by Angela Brett in The Afterlife, video on October 24, 2011
In the film Spider-Man 3, escaped convict Flint Marko jumps over a fence marked:
Danger
Particle Physics Test Facility
Keep Out
And ends up getting caught in a some kind of beam and becoming the Sandman, a being made out of sand who can change his shape at will. I watched it in the theatre with about a dozen people from CERN (all of them named Maikel), and one of them exclaimed, ‘Run to building 40, get a coffee!’
Unfortunately, you won’t turn into the Sandman by sneaking into CERN. But you might just turn into something like the Silver Surfer. Well, okay, maybe you wouldn’t travel faster than light, but you could levitate. I finally got to do so on their superconducting scooter at the Supra Show to celebrate 100 years of superconductivity a couple of weeks ago:
And you don’t even need to jump a fence! Just keep an eye on CERN’s homepage and MaNEP’s homepage, and sign up to the Globe’s mailing list to find out when there will be interesting talks and demonstrations for the general public. There are also a few other events coming up where it might make an appearance. I’ve seen the scooter at a couple of different events, and I don’t know how often they bring it out, but there are many other interesting talks and demonstrations.
There’s more information on how the superconducting scooter works in the video description. It’s essentially superdiamagnetism, as far as I know. Doesn’t quite have the same ring to it as Superman, but hey, it’s real! Welcome to the future. Here’s a nice explanation which begins with a Superman reference. Incidentally, you don’t have to be a superconductor to levitate due to diamagnetism. Even frogs can levitate, but it’s not easy.
Of course, the other way you could become a superhero is by using Generic™ brand hair gel.
By the way, the song in that video is Liquid Nitrogen, by CERN’s other LHC, Les Horribles Cernettes. My other superpower is knowing a song about almost every topic. Today, somebody brought up Malcolm Gladwell’s idea that becoming an expert at something takes 10 000 hours of practice, so I decided to find out how much time I’ve spent listening to funny music. I wrote an AppleScript to sum up the time spent listening to the selected songs in iTunes, and selected all the songs in my Silly Songs playlist. Alas, I have only listened to it for 3026 hours, at least since April 2005 when I dropped my iPod and lost all that information. So if it turns out there’s something I don’t have a song about, it’s because I’m not an expert. I am an expert on all of my music, including the ‘normal’ stuff, though, with 11 242 hours.
Back to superheroes: Could somebody who understands more about the relationship of electric power to superconductivity please make a joke involving Spider-Man’s ‘with great power comes great responsibility’? As far as I can tell, with great power comes the same great power, circulating forever, but that’s not very funny. Just like immortality without immunity to pain isn’t very funny after the Sun burns out, when you’re just floating through space for eons on end, occasionally getting stuck inside a star or black hole until it goes supernova or evaporates.
Addendum: I finally wrote a short story about that last sentence.
Addendum 2: Someone I know only as arthurd006_5 suggests ‘with great power comes great coercivity‘ but isn’t sure whether that works electromagnetically. It does sound nice though, and outside of electromagnetism, great coercion seems to come with great power.
AppleScript: Fixing tags of free music podcasts in iTunes
Posted by Angela Brett in The Afterlife on October 23, 2011
I’m a bit of a free music junkie. Free as in beer (or doughnuts, since I don’t like beer) is good, free as in speech is better, but this post is about the free as in doughnuts kind, which costs nothing until you get a taste for doughnuts and then end up buying out the whole Krispy Kreme, travelling around the world to have different doughnuts with different people, and getting too fat for your iPod. Download free music responsibly, kids (okay, I guess the beer metaphor would have made more sense.) Anyway, back to free music. One way I discover a lot of music is through podcasts which regularly publish individual songs. However, I use iTunes, and iTunes gives podcast tracks the name and artist given in the podcast feed (often taken from the title of a blog post) over whatever was set in the ID3 tags of the mp3 file itself. This might be a good idea for non-music podcasts, and maybe some music podcasts, where the details aren’t necessarily filled out, but for some of the music podcasts I subscribe to it doesn’t really work out. Particularly if there’s a blog post associated with each podcast episode, the title tends to include the artist name and sometimes some other information.
I can’t be bothered fixing all of the tracks manually, so a few years ago I wrote a few AppleScripts to fix up the metadata of the music podcasts I was subscribed to, and also add the tracks to my Songs playlist (which I use as the basis of most of my smart playlists) and turn off the ‘Remember position’ and ‘Skip while shuffling’ options that are turned on by default for podcast tracks. I’ve since subscribed to and made scripts to fix a few more music podcasts, and it occurred to me that other people might find the scripts useful, so I’ve just tidied up the code and added a way to choose which playlist to add the tracks to. There are links to the scripts and related podcasts below.

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported License.
Please tell me if you do something cool with it.

