Posts Tagged Mac
Disinflections
Posted by Angela Brett in News on May 12, 2021
I enjoy taking words that have irregular inflections, and inflecting other words the same way — for instance, saying *squoke as the past tense of squeak, analogous with speak and spoke, or even *squought, analogous with seek and sought. Sometimes those disinflections, as I’ve decided to call them, look or sound like other words… for instance, analogous with fly, flew, and flown, I could use crew and crown as past tenses of cry, or boo and bone as past tenses of buy. Indeed, analogous with buy and bought, the past tense of fly could be *flought, but then again, perhaps the present tense of bought could be ‘batch’ or ‘beak’, or ‘bite’, analogous with caught and catch, or sought and seek, or fought and fight.
The Disinflectant app
For a while now, I’ve wanted to make an app to find these automatically, and now that I have a bit of free time, I’ve made a prototype, mostly reusing code I wrote to generate the rhyme database for Rhyme Science. I’m calling the app Disinflectant for now. Here’s what it does:
- Read words from a file and group them by lemma.
Words with the same lemma are usually related, though since this part is using text only, if two distinct lemmas are homographs (words with the same spelling but different meanings) such as bow🎀, bow🏹, bow🚢, and bow🙇🏻♀️, then they’re indistinguishable. This part is done using the Natural Language framework (henceforth referred to as ‘the lemmatiser’), so I didn’t write any complicated rules to do this. - Find out the pronunciation of the word, as text representing phonemes.
This is done using the text-to-speech framework, so again, nothing specific to Disinflectant. The pronunciation is given in phoneme symbols defined by the API, not IPA. - Find all the different ways that words with the same lemma can be transformed into another by switching a prefix or suffix for another. For instance:
| Transform type | Transform | by analogy with |
|---|---|---|
| Spelling suffix | y→own | fly→flown |
| Pronunciation suffix | IYk→AOt | seek→sought |
| Spelling prefix | e→o | eldest→oldest |
| Pronunciation prefix | 1AW→w1IY | our→we’re |
Most prefixes in English result in words with different lemmas, so Disinflectant didn’t find many prefix transforms, and the ones it found didn’t really correspond to any actual grammatical inflection. I had it prefer suffixes over prefixes, and only add a prefix transform if there is no suffix found, so that bus→buses would result in the spelling suffix transform ∅→es and not the prefix transform bu→buse.
Each transform can apply to multiple pairs of real words. I included a way to label each transform with something like ‘past tense’, so the app could ask, ‘why isn’t crew the past tense of cry?’ but didn’t end up filling in any of them, so it just calls them all inflections.
- Apply each transform individually to each word, and see whether the transformed version matches another word with a different lemma.
It could just make up words such as ‘squoke’, but then there would be hundreds of millions of possibilities and they wouldn’t be very interesting to sift through, so it’s better to look for real words that match.
That’s it. Really just four steps of collecting and comparing data, with all the linguistic heavy lifting done by existing frameworks.
The limitations
Before I show you some of the results, here are some limitations:
- So far I’ve only given it a word list, and not a text corpus. This means that any words which have different lemmas or different pronunciations depending on context (such as ‘moped’ in ‘she moped around’, with the lemma ‘mope’, vs. ‘she rode around on her moped’, with the lemma ‘moped’.) I have code to work with corpora to add homographs to rhyme.science, but I haven’t tried it in this app yet.
- It’s only working with prefixes and suffixes. So it might think ‘woke’ should be the past tense of ‘weak’ (by analogy with ‘speak’ and ‘spoke’) but won’t generalise that to, say, ‘slope’ as the past tense of ‘sleep’ unless there is another word ending in a p sound to model it on. I could fairly easily have it look for infix transforms as well, but haven’t done so yet.
- It doesn’t distinguish between lemmas which are spelled the same, as mentioned above.
The results
For my first full test run, I gave it the SCOWL 40 list, with 60523 words, and (after about a day and a half of processing on my mid-2014 MacBook Pro — it’s not particularly optimised yet) it found 157687 disinflections. The transform that applied to the most pairs of actually-related words was adding a ‘z’ sound to the end of a word, as for a plural or possessive noun or second-person present-tense verb ending in a voiced sound. This applies to 7471 pairs of examples. The SCOWL list I used includes possessives of a lot of words, so that probably inflates the count for this particular transform. It might be interesting to limit it to transforms with many real examples, or perhaps even more interesting to limit it to transforms with only one example.
I just had it log what it found, and when a transform applied to multiple pairs of words, pick a random pair to show for the ‘by analogy with’ part in parentheses. Here are some types of disinflections it found, roughly in order from least interesting to most interesting:
Words that actually are related, just not so much that they have the same lemma:
Some words are clearly derived from each other and maybe should have the same lemma; others just have related meanings and etymology.
- Why isn’t shoppers (S1AApIXrz) with lemma shopper the inflection of shops (S1AAps) with lemma shop? (by analogy with lighter’s → light’s)
- Why isn’t constraint (kIXnstr1EYnt) with constraint same the inflection of constrain (kIXnstr1EYn) with lemma constrain? (by analogy with shopped → shop)
- Why isn’t diagnose (d1AYIXgn1OWs) with lemma diagnose the inflection of diagnosis (d1AYIXgn1OWsIXs) with lemma diagnosis? (by analogy with he → his)
- Why isn’t sieves (s1IHvz) with lemma sieve the inflection of sift (s1IHft) with lemma sift? (by analogy with knives → knifed)
- Why isn’t snort (sn1AOrt) with lemma snort the inflection of snored (sn1AOrd) with lemma snore? (by analogy with leapt → leaped)
Words that definitely should have had the same lemma, for the same reason the words in the analogy do:
These represent bugs in the lemmatiser.
- Why isn’t patrolwoman’s (pIXtr1OWlwUHmIXnz) with lemma patrolwoman’s the inflection of patrolwomen (pIXtr1OWlwIHmIXn) with lemma patrolwomen? (by analogy with patrolman’s → patrolmen)
- Why isn’t blacker (bl1AEkIXr) with lemma black the inflection of blacken (bl1AEkIXn) with lemma blacken? (by analogy with whiter → whiten)
Transforms formed from words which have the same lemma, but probably shouldn’t:
These also probably represent bugs in the lemmatiser.
- Why isn’t car (k1AAr) with lemma car the inflection of air (1EHr) with lemma air? (by analogy with can’t → ain’t)
Both ‘can’t’ and ‘ain’t’ are given the lemma ‘not’. I don’t think this is correct, but it’s possible I’m using the API incorrectly or I don’t understand lemmatisation.
Words that are related, but the lemmatiser was considering an unrelated homograph of one of the words, and the actual related word was not picked up because of the first limitation above:
- Why isn’t skier’s (sk1IYIXrz) with lemma skier the inflection of skied (sk1IYd) with lemma sky? (by analogy with downer’s → downed)
In this case, the text-to-speech read ‘skied’ as the past tense of ‘ski’, but the lemmatiser read it as the past participle of ‘sky’, as in, ‘blue-skied’, which I think is a slightly obscure choice, and might be considered a bug in the lemmatiser. - Why isn’t ground (gr1AWnd) with lemma ground the inflection of grinding (gr1AYndIHN) with lemma grind? (by analogy with rewound → rewinding)
Here the lemmatiser is presumedly reading it as the noun or verb ‘ground’ rather than the past and past participle of ‘grind’.
Pronunciation transforms finding homophones of actual related words:
- Why isn’t sheikhs (S1EYks) with lemma sheikh the inflection of shaking (S1EYkIHN) with lemma shake? (by analogy with outstrips → outstripping)
‘Sheikhs’ sounds just like ‘shakes’, which is indeed the present tense or plural of ‘shake’. - Why isn’t soled (s1OWld) with lemma sole the inflection of selling (s1EHlIHN) with lemma sell? (by analogy with sold → selling)
‘Soled’ sounds just like ‘sold’, which is indeed the past tense of ‘sell’.
Pronunciation transforms based on an incorrect pronunciation:
These represent bugs in the text-to-speech. Try them yourself on a Mac by setting the system voice to an older American English one such as Victoria, selecting the word, and choosing Speech→Start Speaking from the Edit menu or the contextual menu.
- Why isn’t nape’s (n1AEpIYz) with lemma nape the inflection of nappy (n1AEpIY) with lemma nappy? (by analogy with suffocation’s → suffocation)
The text-to-speech pronounces ‘nape’ correctly, but pronounces ‘napes’ like ‘naps’ and ‘nape’s’ like ‘nappies’. - Why isn’t mice (m1AYs) with lemma mouse the inflection of me (m1IY) with lemma I? (by analogy with modernity’s → modernity)
The text-to-speech pronounces ‘modernity’ correctly, but pronounces ‘modernity’s’ like ‘modernitice’.
- Why isn’t queue’s (ky1UWz) with lemma queue the inflection of cubing (ky1UWbIHN) with lemma cubing? (by analogy with lambs → lambing)
The text-to-speech pronounces the ‘b’ in ‘lambing’. I’m not sure if there is an accent where this is the correct pronunciation, but it isn’t in the dictionaries I’ve checked.
Small transforms that can be applied to many other words:
Sometimes it will find that a word with the same lemma can have one letter or phonemes changed or added, and then there are a huge number of words that the transform can apply to. I wonder if you could almost change any final letter or phoneme to any other.
- Why isn’t mine (m1AYn) with lemma I the inflection of mind (m1AYnd) with lemma mind? (by analogy with shoe → shod)
- Why isn’t ham (h1AEm) with lemma ham the inflection of hay (h1EY) with lemma hay? (by analogy with them → they)
This one could also be extended to hair (from them → their) to get a full set of weird pronouns. - Why isn’t hearth (h1AArT) with lemma hearth the inflection of heart (h1AArt) with lemma heart? (by analogy with sheikh → sheik)
- Why isn’t captor (k1AEptIXr) with lemma captor the inflection of captain (k1AEptIXn) with lemma same? (by analogy with whiter → whiten)
- Why isn’t colt (k1OWlt) with lemma colt the inflection of coal (k1OWl) with lemma coal? (by analogy with shopped → shop)
Spelling prefixes and suffixes that don’t quite correspond to how the inflections are formed:
Sometimes changes such as doubling the final consonant are made when an -ing or -ed is added. Since Disinflectant only sees this as a suffix being added, it thinks that specific consonant can also be added to words that end in other consonants.
- Why isn’t braking (br1EYkIHN) with lemma brake the inflection of bra (br1AA) with lemma bra? (by analogy with picnicking → picnic)
- Why isn’t garbs (g1AArbz) with lemma garbs the inflection of garbling (g1AArblIHN) with lemma garble? (by analogy with corrals → corralling)
- Why isn’t badgering (b1AEJIXrIHN) with lemma badger the inflection of badge (b1AEJ) with lemma badge? (by analogy with transferring → transfer)
- Why isn’t bobsled (b1AAbslEHd) with lemma bobsled the inflection of bobs (b1AAbz) with lemma bob? (by analogy with patrolled → patrol)
Disinflection I might have come up with myself:
- Why isn’t hay (h1EY) with lemma hay the inflection of highs (h1AYz) with lemma high? (by analogy with lay → lies)
- Why isn’t bowled (b1OWld) with lemma bowl the inflection of belling (b1EHlIHN) with lemma bell? (by analogy with sold → selling)
- Why isn’t bodies (b1AAdIYz) with lemma body the inflection of bodice (b1AAdIXs) with lemma bodice? (by analogy with emphases → emphasis)
- Why isn’t lease (l1IYs) with lemma lease the inflection of loosed (l1UWst) with lemma loose? (by analogy with geese → goosed)
- Why isn’t wield (w1IYld) with lemma wield the inflection of welt (w1EHlt) with lemma welt? (by analogy with kneeled → knelt)
- Why isn’t gauze (g1AOz) with lemma gauze the inflection of goo (g1UW) with lemma goo? (by analogy with draws → drew)
- Why isn’t cheese (C1IYz) with lemma cheese the inflection of chosen (C1OWzIXn) with lemma choose? (by analogy with freeze → frozen)
Transforms based on abbreviations:
- Why isn’t chuckle (C1UXkIXl) with lemma chuckle the inflection of chuck’s (C1UXks) with lemma chuck? (by analogy with mile → mi’s)
- Why isn’t cooperative’s (kOW1AApIXrrIXtIHvz) with lemma cooperative the inflection of cooper (k1UWpIXr) with lemma cooper? (by analogy with negative’s → neg)
- Why isn’t someday (s1UXmdEY) with lemma someday the inflection of some (s1UXm) with lemma some? (by analogy with Friday → Fri)
Other really weird stuff I’d never think of:
- Why isn’t comedy (k1AAmIXdIY) with lemma comedy the inflection of comedown (k1UXmdAWn) with lemma comedown? (by analogy with fly → flown)
- Why isn’t aisle (1AYl) with lemma aisle the inflection of meal (m1IYl) with lemma meal? (by analogy with I → me)
- Why isn’t hand (h1AEnd) with lemma hand the inflection of hens (h1EHnz) with lemma hen? (by analogy with manned → men’s)
- Why isn’t out (1AWt) with lemma same the inflection of wheat (w1IYt) with lemma same? (by analogy with our → we’re)
If people are interested, once I’ve fixed it up a bit I could either release the app, or import a bigger word list and some corpora, and then publish the whole output as a CSV file. Meanwhile, I’ll probably just tweet or blog about the disinflections I find interesting.
That time Steve Wozniak taught me to Segway and then played Tetris and pranks through a concert
Posted by Angela Brett in Story Time, video on September 5, 2020
A few weeks ago I posted a video of myself talking about the time Steve Wozniak gave me a laptop, and I said:
A few years later, I met Woz, had pizza and learnt to Segway with him, and watched him play Tetris and pranks all through a concert of The Dead, but that will probably be a different 18-minute video.
Well, last week I indeed recorded an 18-minute video about the time I met Woz; the raw video was coincidentally imported into Photos at the same minute of the day as the previous one, and was one second longer than it.
The final video, with turning the camera on and off trimmed out, is two seconds longer than the previous one.
The background is a little blurry, but in the first take the entire picture was blurry, so in comparison, a little artful background blur is fine.
The short version: I met a friend of Woz by complaining by email that the lights were turned off in Woz’s office, and then met that friend in San Francisco when I went there for WWDC 2004. We met Woz, who had flashing lights in his teeth, at a pizza restaurant, and then went to a concert, where we rode Segways and Woz confused people by flashing tooth lights and lasers at them while playing Tetris.
Here’s a playlist with both of my Woz stories. Perhaps this will be the start of a series of 18-minute videos about my ridiculous life, or perhaps not. I don’t have any more Woz stories, but I do have more stories.
That time Steve Wozniak bought me a laptop
Posted by Angela Brett in Story Time, video on August 21, 2020
People seem to enjoy hearing this story, and Woz’s 70th birthday seems like a good occasion to tell it to more people. I in a lot of details of varying relevance (and was looking down at notes on my iPad a bit to keep track of them), because it my video and I may as well tell it my own way. But if you don’t have eighteen minutes to spare, there’s a short version in the next paragraph (to avoid spoilers.)
The short version: My then-boyfriend left my PowerBook in a phone booth, the PowerBook was held for ransom and not recovered, and meanwhile my sister emailed the Woz (who knew of me from having called me on my birthday half a year earlier) and offered to buy me a replacement.
A few years later, I met Woz, had pizza and learnt to Segway with him, and watched him play Tetris and pranks all through a concert of The Dead, but that will probably be a different 18-minute video.
If you think my life is ridiculous, well, you’re right, but also, you should see Steve Wozniak’s life! (His autobiography, iWoz, would be a great book to read to a cool kid at bedtime.) And check out the events, challenges, and fundraising going on at wozbday.com.
Apple Watch vs. Macintosh Classic boot time
Posted by Angela Brett in Culture on April 27, 2015
I somehow ended up buying an Apple Watch the other day, though I’d intended to wait a while first. I have a pretty neat Casio digital watch already, of course, but I’d never had a wearable computer. Now that I have one, I’d better get to work writing apps for it in order to rationalise my purchase, though my hopes of making millions on a fart app have already been dashed. But first, my friend (and fellow Apple Watch early adopter) Phil and I visited a friend’s collection of old Apple computers, and tested the startup time of the 2015 Apple Watch running Watch OS 1.0 against a 1991 Macintosh Classic running System 7.1. Here’s my video of the test:
And here’s Phil’s:
Since the Apple watch probably won’t need to be restarted very often, the difference might not add up to many lifetimes, but it was fun to test. An Apple Watch engineer suggested the results would be different at the bottom of a swimming pool.
I’ve spent much more time with Macintosh Classics than with my Apple Watch so far, and I don’t think it’s really fair to compare them, but so far I like the watch better. Among other things, the Apple Watch has a greater variety of available straps, is lighter on the wrist, is more likely to tell the correct time, and will show the time prominently without the addition of third-party software such as the SuperClock control panel.
My MacBook (My Monkey parody)
Posted by Angela Brett in NaPoWriMo on April 4, 2015
 It’s Poetry Writing Month again! I’m not sure if I’ll write a poem every day for the rest of the month, since I’ve recently landed back in Vienna and should be concentrating on looking for a job, but I have one I prepared earlier. Also, I recited the poem I opened last NaPoWriMo with at Open Mic 2.0 on the first of April. The audience seemed confused, so I followed it with a cover of the more self-explanatory Chicken Monkey Duck.
It’s Poetry Writing Month again! I’m not sure if I’ll write a poem every day for the rest of the month, since I’ve recently landed back in Vienna and should be concentrating on looking for a job, but I have one I prepared earlier. Also, I recited the poem I opened last NaPoWriMo with at Open Mic 2.0 on the first of April. The audience seemed confused, so I followed it with a cover of the more self-explanatory Chicken Monkey Duck.
This is a parody of Jonathan Coulton’s ‘My Monkey‘, but since I don’t have a monkey butler named Brian Dennehy, I project feelings onto my MacBook Pro instead. I wrote it a few weeks ago after being away from my Time Capsule for quite a while.
My MacBook gets homesick sometimes.
My MacBook has a lot of things that need to be backed up.
My MacBook lacks power sometimes.
My MacBook’s not the only one that’s starting to act up.
‘Cause every MacBook needs time to thrive
when not all processes are queued live
to wake recharged with a renewed drive.
It doesn’t mean my MacBook doesn’t love you.
[My MacBook Sneuf is new and shiny still, but she’s worn out and she is sorry]
[My MacBook, she loves you. My MacBook loves you very much]
[My MacBook says My MacBook says]
[My MacBook says she’s sorry she’s a MacBook, but she’s got to be a MacBook ’cause she’s so insanely great]
My MacBook gets frazzled sometimes.
My MacBook’s used to Europe and needs sockets to adapt.
My MacBook gets bitter, sometimes.
My MacBook feels cut off when high-speed data use is capped.
And while there’s no pain in her diodes,
and she’s not going to send you STOP codes,
it’s hard to hold back all these uploads.
It doesn’t mean my MacBook doesn’t love you.
[My MacBook Sneuf is new and shiny still, but she’s worn out and she is sorry]
[My MacBook, she loves you. My MacBook loves you very much]
[My MacBook says My MacBook says]
[My MacBook says she’s sorry she’s a MacBook, but she’s got to be a MacBook ’cause she’s so insanely great]
My MacBook feels lacking sometimes.
My MacBook cut herself up so she wouldn’t weigh you down.
My MacBook feels lucky, sometimes.
My MacBook hopes that you will always carry her around.
She says she’ll stay with you for always.
It doesn’t matter what Tim Cook says,
’cause every MacBook model decays
It doesn’t mean my MacBook doesn’t love you.
[My MacBook Sneuf is new and shiny still, but she’s worn out and she is sorry]
[My MacBook, she loves you. My MacBook loves you very much]
[My MacBook says My MacBook says]
[My MacBook says she’s sorry she’s a MacBook, but she’s got to be a MacBook ’cause she’s so insanely great]
It doesn’t mean my MacBook doesn’t love you.
∎
In other news, I have uploaded videos of the first Jonathan Coulton concert on JoCo Cruise 2015, which has pretty bad audio but interesting video during Re: Your Brains, at least. I’ve also uploaded the Adam Sak and Hello, The Future! show, the first jam session, the Patrick Rothfuss and Paul and Storm concert, the Magic: The Gathering match between Jonathan Coulton and Storm DiCostanzo, and the first part of the concert with The Oatmeal in it. More forthcoming.
Haiku Detector Update
Posted by Angela Brett in Haiku Detector on April 27, 2013
On Monday I posted a quick-and-dirty Haiku Detector Mac application I’d written which finds haiku (in terms of syllable counts and line breaks, not aesthetics) in any given text. Since then I’ve made it less dirty and maybe more quick. It now shows progress when it’s busy looking for haiku in a long text, and gives you a count of the sentences it looked at and the haiku it found. You can also copy all the haiku (Copy All Haiku in the Edit menu) or save them to a file (Save in the File menu.) Here’s where you can download the new version, which should still work on Mac OS X 10.6 and later. And here are a few more haiku I’ve found with it.
There’s only one (not counting a by-line) in the feature articles of the April 27 edition of New Scientist:
Inside a cosy
new gut the eggs hatch and the
cycle continues.
From Flatland: a romance of many dimensions, by Edwin Abbott Abbott:
On the reply to
this question I am ready
to stake everything.“I come,” said he, “to
proclaim that there is a land
of Three Dimensions.”Man, woman, child, thing—
each as a Point to the eye
of a Linelander.This was the Climax,
the Paradise, of my strange
eventful History.
Here are a few more from Flatland which I’m editing this post to add, since I liked them more on the second reading:
Let us begin by
casting back a glance at the
region whence you came.Therefore, pray have done
with this trifling, and let us
return to business.Even if I were
a baby, I could not be
so absurd as that.
From Last Chance to See, by Douglas Adams and Mark Carwardine, which I somehow ended up with a text file of many years ago and eventually got a book of:
I’ve been here for five
days and I’m still waiting for
something to go right.We each went off to
our respective rooms and sat
in our separate heaps.They’re nocturnal birds
and therefore very hard to
find during the day.It looked like a great
horn-plated tin opener
welded to its face.We keep searching for
more females, but we doubt if
there are any more.The very laws of
physics are telling you how
far you are from home.Foreigners are not
allowed to drive in China,
and you can see why.`Just the one left,’ she
said, putting it down on the
ground in front of her.Yet it was hunted
to extinction in little
more than fifty years.And conservation
is very much in tune with
our own survival.
And here’s my own haiku about a particularly amusing passage in that book:
Here Douglas Adams
trudges through his anagram:
Sago mud salad.
Charles Darwin’s most popular work, The Formation of Vegetable Mould Through the Action of Worms with Observations on their Habits, only contained 12 mostly-lacklustre haiku, but I like to think this one is a metaphor:
Worms do not always
eject their castings on the
surface of the ground.
Something about lack of worm castings being only skin-deep.
But most of these don’t mention nature or seasons, as haiku should. So here are some from Sylva, or A Discourse of Forest Trees:
Dieu, and thence rode to
Blois and on to Tours, where he
stayed till the autumn.How graphic, and how
refreshing, is the pithy
point thus neatly scored—
Meteorology, or Weather Explained, by J.G. M’Pherson contains some very poetic-sounding unintentional haiku:
“It’ll pe aither
ferry wat, or mohr rain”—a
poor consolation!“Beware of rain” when
the sheep are restive, rubbing
themselves on tree stumps.The brilliant flame, as
well as the smoky flame, is
a fog-producer.Till ten o’clock the
sun was not seen, and there was
no blue in the sky.But, strange to say, there
is a healing virtue in
breathing different air.There is much pleasure
in verifying such an
interesting problem.
Unfortunately, there are no haiku in Dijkstra’s ‘Go To Statement Considered Harmful‘.
The app still uses a lot of memory if you process a novel or two, and may have trouble saving files in that case; It looks like it’s a bug in the speech synthesis library (or my use of it) or simply a caching strategy that doesn’t work well when the library is used in this rather unusual and intensive way. Anyway, if you ever try to save a file and the Save dialog doesn’t appear, try copying instead, and relaunch the program.
Next I think I’ll experiment with finding the best haiku based on the parts of speech at the ends of lines. But first, I’d better start working on the thing I’ve plan to do for the six of hearts.
If you’ve found any nice unintentional haiku, or if you can’t run Haiku Detector yourself but have ideas for freely-available texts it could be run on, let me know in the comments.
Five of Hearts: Haiku Detector
Posted by Angela Brett in CERN, Haiku Detector, Writing Cards and Letters on April 23, 2013
 A few weeks ago, a friend linked to Times Haiku, a website listing unintentional haiku found in The New York Times, saying ‘I’d actually pay for a script that could check for Haiku in my writings. That would make prose-production a lot more exciting! Who’s up to the script-writing-challenge?’
A few weeks ago, a friend linked to Times Haiku, a website listing unintentional haiku found in The New York Times, saying ‘I’d actually pay for a script that could check for Haiku in my writings. That would make prose-production a lot more exciting! Who’s up to the script-writing-challenge?’
I knew I could do it, having written syllable-counting code for my robot choir (which I really need to create an explanation page about.) I told her I’d make it that weekend. That was last weekend, when I decided at the last moment to write an article about neutron stars and ISOLTRAP, and then chickened out of that and wrote a poem about it. So I put off the haiku program until yesterday. It was fairly quick to write, so here it is: Haiku Detector. It should work on Mac OS X 10.6 and above. Just paste or type text into the top part of the window, and any detected haiku will appear in the bottom part.
Haiku Detector looks for sentences with seventeen syllables, and then goes through the individual words and checks whether the sentence can be split after the fifth and twelfth syllables without breaking a word in half. Then it double-checks the last line still has five syllables, because sometimes the punctuation between words is pronounced. The Times Haiku-finding program has a database of syllable counts per word, but I didn’t need that since I can use the Mac OS X speech synthesis API to count the syllables. Haiku Detector makes no attempt to check for kigo (season words.)
The first place I looked for haiku was the Wikipedia page for Haiku in English. Due to the punctuation, it didn’t actually find any of the example haiku on the page, but it did find this:
Robert Spiess (Red Moon
Anthology, Red Moon Press,
1996)
How profound. Next, having declared myself contributing troubadour for New Scientist magazine, I fed this week’s feature articles through it, and found:
A pill that lowers
arousal doesn’t teach shy
people what to doMeanwhile, there are signs
that the tide is turning in
favour of shyness.So by 4000
years ago, the stage was set
for the next big step.This heat makes the air
spin faster, so pulling the
storm towards the city.Some will be cooler
and less humid — suitable
for outdoor sports, say.
The last ones seem almost seasonal.
I needed to stress-test the app with a large body of text, so I grabbed the first novel of which I had the full text handy: John Scalzi‘s Old Man’s War, which I had on my iPad on my lap to read while my code was compiling. This book has at least one intentional haiku in it, which Haiku Detector detected. Apart from that, some of my favourites are:
I hate that her last
words were “Where the hell did I
put the vanilla.”As I said, this is
the place where she’s never been
anything but dead.“I barely know him,
but I know enough to know
he’s an idiot.”She’d find me again
and drag me to the altar
like she had before.A gaper was not
long in coming; one swallow
and Susan was in.They were nowhere to
be found, an absence subtle
and yet substantial.And it stares at me
like it knows something truly
strange has just happened.
I haven’t got up to that fifth one in the novel yet, but it mentions a swallow, which I understand is (when accompanied by more swallows) a harbinger of Spring or Summer depending on which language you get your idioms from, so there’s the kigo.
Next I figured I should try some scientific papers — the kinds of things with words that the Times haiku finder would not have in its syllable database. You probably can’t check this unless your workplace also provides access to Physics Letters B, but I can assure you that the full text of the ISOLTRAP paper about neutron stars does not contain any detectable haiku. However, the CMS paper announcing the discovery of the boson consistent with the Higgs does:
In the endcaps, each
muon station consists of
six detection planes.
As is usual for CMS papers, the author and institute lists are about as long as the paper itself, and that’s where most of the haiku were too. Here are a few:
[102]
LHC Higgs Cross Section
Working Group, in: S.University
of California, Davis,
Davis, USA
That’s ‘one hundred and two’ in case anyone who doesn’t say it that way was wondering.
And here are some from my own blog. I used the text from a pdf I made of it before the last JoCo Cruise Crazy, so the last few months aren’t represented:
Beds of ground cover
spread so far in front of him
they made him tired.Apologies to
those who only understand
half of this poem.I don’t remember
what colour he said it was,
but it was not green.His eyes do not see
the gruesome manuscript scrawled
over the white wall.• Lines 1 to 3 have
four syllables each, with stress
on the first and last.
(That’s not how you write a haiku!)
I don’t wear armour
and spikes to threaten you, but
to protect myself.A single female
to perpetuate the genes
of a thousand men.Kerblayvit is a
made-up placeholder name, and
a kerblatent cheat.He wasn’t the first,
but he stepped on the moon soon
after Neil Armstrong.He just imagined
that in front of him there was
a giant dunnock.
(there are plenty more where that one came from, at the bottom of the page)
She was frustrated
just trying to remember
what the thing was called.Please don’t consider
this a failing; it is part
of your programming.
While writing this program, I discovered that that the speech API now has an easier way to count syllables, which wasn’t available when I wrote the robot choir. The methods I used to separate the text into sentences and the view I used to display the haiku are also new. Even packaging the app for distribution was different. I don’t get to write Mac software often enough these days.
Yet again, I didn’t even bother to deal out the cards because I already had something to inspire me. In my halfhearted attempt to find a matching card, I came across one about electronics in the service of ALICE, so I ran the latest instalment of Probably Never, by Alice, into it, and got this:
Or well, I have to
put up with getting called a
fake girl all the time.The jackhole who called
me a “he/she” recognized
that he crossed the line.
If that sounds interesting, subscribe to Probably Never, and I could probably forward you the rest of that episode if you want.
And finally, two unintentional haiku from this very post:
Haiku Detector
makes no attempt to check for
kigo (season words.)(there are plenty more
where that one came from, at the
bottom of the page)
Wait; make that three!
And finally, two
unintentional haiku
from this very post:
Have fun playing with Haiku Detector, and post any interesting haiku you find in the comments. Also, let me know of any bugs or other foibles it has; I wrote it pretty quickly, so it’s bound to have some.
I know what I’m doing for the six of hearts; I’ve planned it for a long time but still haven’t actually started it. It’s musical, so it will probably be terrible; brace yourselves. By the way, I keep forgetting to mention, but They Might Not Be Giants will be published in Offshoots 12. Yay!
Six of Clubs: Birthday Monduckenen-duckenen
Posted by Angela Brett in Bäume, Writing Cards and Letters on December 21, 2012
First, check out Vi Hart‘s video about the Thanksgiving turduckenen-duckenen:
Now have a look at Mike Phirman‘s song, Chicken Monkey Duck:
Okay, there are monkeys instead of turkeys, and the mathematics isn’t quite as explicit, but it’s pretty similar, don’t you think? Now, let’s imagine that Mike Phirman is actually singing the recipe for a fractal turducken, or rather, monducken. You can imagine all the monkeys are turkeys if you’d rather eat the result than present it to some pretty thing to please them. (Note: Please do not kill any actual monkeys.) Monkeys, like birds, belong in trees, so I wrote an AppleScript to draw binary trees in OmniGraffle based on the text of the song. You can try it for yourself if you like; all you need is a Mac, OmniGraffle, and a text file containing some words. See the bottom of this post for links and instructions.
If Mike’s reading the binary tree recipe layer by layer, like the first example in Vi’s video, one possible tree for the first stanza of Chicken Monkey Duck looks like this, where the orange ovals are monkeys, blue hexagons are chickens and green clouds are ducks. You can click it (or any other diagram in this post) for a scalable pdf version where you can read the words:
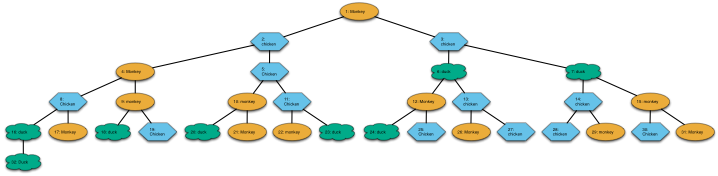
I added numbers so you can easily tell the chickens, monkeys and ducks apart and see which way to read the tree. It’s simple enough now, but the numbers will be useful for reading later trees which are not in such a natural reading order. This is called a breadth-first traversal of the tree, in case you’re interested. Now, what do birds and monkeys do in trees? They nest! So I wrote another script that will take any tree-like diagram in OmniGraffle and draw what it would look like if the birds, monkeys, or whatever objects they happen to be (the drawing is pretty abstract) were nested inside each other, just like the quails inside the chickens inside the ducks inside the turkey. This is what the monducken described by the first stanza of Chicken Monkey Duck, in the tree structure shown above, would look like:

The Monducken script allows using a different shape for each animal as redundant coding for colourblind people, even though it already chooses colours which most colourblind people should be able to distinguish. But that makes the nested version look a little messy, so here’s the above diagram using only ovals:

If you named this particular recipe in the other way, going down the left side of the tree and then reading each branch in turn in what is known as a pre-order traversal, it would be called a Monenmonenduckduckmon-monmonducken-enenmonduckmon-enmonduck-enduckmonducken-enmonen-duckenenmon-monenmon. It doesn’t sound nearly as nice as Turduckenailailenailail-duckenailailenailail because Mike Phirman didn’t take care to always put smaller animals inside large ones. I’m not holding that against him, because he didn’t realise he was writing a recipe, and besides, it’s his birthday. For reasons I’m not sure I can adequately explain, it’s always his birthday.
But what if I completely misunderstood the song, and his recipe is already describing the fractal monducken as a pre-order traversal, always singing a bird or monkey immediately before the birds and monkeys inside it? Well, don’t worry, I added a ‘pre-order’ option to the script, so you can see what that would look like. Here’s the tree:

and here’s how the actual birds/monkeys would look if you cut them in some way that showed all the animals, dyed them the correct colours, and looked through something blurry (here’s the version with different shapes):

Okay, but that’s only the first stanza. What if we use the whole song? If we pretend the recipe is breadth-first, this just means all the extra monkeys and birds will be at the bottom levels of the tree, so the outer few layers of our monducken will be the same, but they’ll have a whole lot of other things inside them:


Here’s a close-up. Isn’t it beautiful?
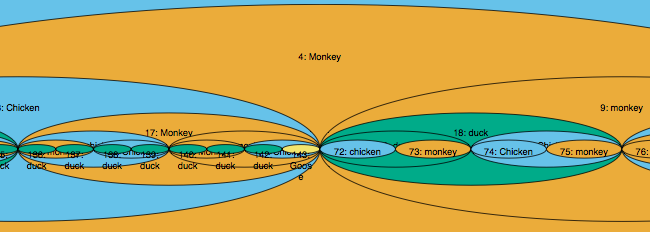
If the entire song were treated as a pre-order monducken recipe, we’d still have the same monkey on the outside, but the rest would be quite different:


We could also read the birds and monkeys from left to right, as Vi did in her video. That’s what’s called an in-order tree traversal. But as delicious as they are mathematically, none of these orderings make much sense from a culinary perspective. Even if the monkeys were turkeys, it’s obvious that a nice big goose should be the outer bird. Vi suggested that herself. Of course, we could put the goose on the outside simply by reversing the song so it started with goose. But it would be much more fun and practical to pretend that Mike is naming the two inner birds before the one that contains them. This is called a post-order traversal, because you name the containing bird after the two birds or monkeys it will contain. It makes sense for a recipe. First you prepare a monkey (or turkey) and a chicken, then you immediately prepare a chicken and put them into it. You don’t have your workspace taken up with a whole lot of deboned birds you’re not ready to put anything into yet. Here’s one way the recipe could be done:

Note that no matter what kind of traversal we use, there are actually several ways the recipe could be interpreted. If Mike says ‘monkey chicken chicken’ you know you should take a monkey and a chicken and put them in a chicken. But if the next words are ‘monkey chicken’, do you take that stuffed chicken and a monkey and put them inside a chicken? Do you debone the monkey and the chicken and wait for the next bird to find out what to put them into? What if there’s no next bird? What if there’s only one more bird (let’s say a duck) and you end up with a stuffed chicken, a stuffed duck, and nothing to stuff them into? You’d have to throw one of them out, because obviously your oven only has room for one monducken. Assuming you want two things in each thing, and you don’t know how long the song’s going to be, the best way to minimise this kind of problem is to always take your latest stuffed thing and the next, unstuffed thing, and put them inside the thing after that. The worst that’ll happen is you’ll have to throw out one unstuffed bird or monkey. But then you end up with a really unbalanced monducken, with a whole lot of layers in one part and lonely debonely birdies floating around in the rest.
It helps to have a robot chef on hand to figure out how many full layers of monducken you can make without it being too asymmetric. Mine makes the trees completely balanced as deeply as possible, and then does whatever was easiest to program with the remaining birds and monkeys. In this case it was easiest for my program to stuff a whole lot of extra animals into that one monkey on the left. This is what it looks like, with the varied shapes this time. Luckily, geese are rectangular, so they fill your oven quite efficiently:

I like how you can see the explosion of duck radiating out from the inner left, engulfing all the other birds and monkeys before itself being swallowed by a goose. Such is life.
 If you would like to make diagrams like this yourself, there are two AppleScripts you can use. Both of them require OmniGraffle 5 for Mac, and if you want to make trees with more than 20 nodes you’ll probably need to register OmniGraffle.
If you would like to make diagrams like this yourself, there are two AppleScripts you can use. Both of them require OmniGraffle 5 for Mac, and if you want to make trees with more than 20 nodes you’ll probably need to register OmniGraffle.
The first is Monducken diagrammer, which you can download either as a standalone application (best if you don’t know what AppleScript is) or source code (if you want to tweak and critique my algorithms, or change it to use OmniGraffle Professional 5 instead of OmniGraffle 5.) Because it’s AppleScript, it works by telling other applications what to do, rather than doing things itself. So when you run it, TextEdit will ask you to open the text file you want to turn into a tree. Once you’ve opened one, OmniGraffle will start up (you may need to create a new document if it’s just started up) and ask you two things. First it will ask what kind of tree traversal the text file represents. Then it will ask you what kinds of shapes you want to use in your tree. You can select several shapes using the shift and command keys, just as you would for selecting multiple of just about anything on your Mac. Then you can sit back and watch as it creates some shapes and turns them into a tree.
The other one is Tree nester (standalone application/source code) You should have an OmniGraffle document open with a tree-like diagram in it (I suggest a tree generated using Monducken diagrammer; it has not been tested on anything else, and will probably just duplicate most of the shapes that aren’t trees or end up in an infinite loop if there’s a loopy tree) before you run this. It won’t ask any questions; it’ll just create a new layer in the front OmniGraffle document and draw nested versions of any trees into that layer.
If you’re looking at the source code, please bear in mind that I wrote most of this while on a train to Cologne last weekend, based on some code I wrote a while ago to draw other silly diagrams, and I really only dabble in AppleScript, and I forgot about the ‘outgoing lines’ and ‘incoming lines’ properties until I’d almost finished, so it probably isn’t the best quality AppleScript code. Not the worst either though. I welcome any tips.
Eight of Spades: The Synaesthetist
Posted by Angela Brett in Birds of Canada, Schmetterlinge, Writing Cards and Letters on April 29, 2012
 I’ve mentioned before that I have grapheme-colour synaesthesia. That means that I intuitively associate each letter or number with a colour. The colours have stayed the same throughout my life, as far as I remember, and they are not all the same colours that other grapheme-colour synaesthetes (such as my father and brother) associate with the same letters. I still see text written in whichever colour it’s written in, but in my mind it has other colours too. If I have to remember the number of a bus line, there’s a chance I’ll remember the number that goes with the colour it was written in rather than the correct letter, or I’ll remember the correct letter and look in vain for a bus with a number written in that colour.
I’ve mentioned before that I have grapheme-colour synaesthesia. That means that I intuitively associate each letter or number with a colour. The colours have stayed the same throughout my life, as far as I remember, and they are not all the same colours that other grapheme-colour synaesthetes (such as my father and brother) associate with the same letters. I still see text written in whichever colour it’s written in, but in my mind it has other colours too. If I have to remember the number of a bus line, there’s a chance I’ll remember the number that goes with the colour it was written in rather than the correct letter, or I’ll remember the correct letter and look in vain for a bus with a number written in that colour.
Well, I’ve been wondering whether it could work the other way.
- Could grapheme-colour synaesthetes learn to look at a sequence of colours that correspond to letters in their synaesthesia, and read a word?
- Could this be used to send code messages that only a single synaesthete can easily read?
- Could colours be used to help grapheme-colour synaesthetes learn to read a new alphabet, either one constructed for the purposes of secret communication, or a real script they will be able to use for something?
- What would be the difference in learning time for a grapheme-colour synaesthete using their own colours for the replacement graphemes, a grapheme-colour synaesthete using random colours, and a non-synaesthete?
I know that for me, there are quite a few letters with similar colours, and a few that are black or white, so reading a novel code wouldn’t be infallible, but I suspect I would be able to learn a new alphabet a little more easily or read it more naturally if it were presented in the ‘right’ colours. I wonder whether the reason the Japanese symbol for ‘ka’ seemed so natural and right to me was that it seemed to be the same colour as the letter k.
It occurred to me that, as a programmer and a grapheme-colour synaesthete, I could test these ideas, or at least come up with some tools that scientists working in this area could use to test them. So I wrote a little Mac program called Synaesthetist. You can download it from here. In it, you choose the colours that you associate with different letters (or just make up some if you don’t have grapheme-colour synaesthesia and you want to know what it’s like) and save them to a file.

Then you can type in some text, and you’ll see the text with the letters in the right colours, like so:

But even though this sample is using the ‘right’ colours for the letters, it still looks all wrong to me. When I think of a word, usually the colour of the word is dominated by the first letter. So I added another view with a slider, where you can choose how much the first letter of a word influences the colours of the rest of the letters in the word.

This shows reasonably well what words are like for me, but sometimes the mix of colours doesn’t really resemble either original colour. It occurred to me that an even better representation would be to have the letters in their own colours, but outlined in the colour of the first letter. So I added that:

Okay, so that gives you some idea of what the words look like in my head. And maybe feeding text through this could help me to memorise it. Here’s an rtf file of the lyrics to Mike Phirman‘s song ‘Chicken Monkey Duck‘ in ‘my’ colours, with initial letter outline. I’ll study these and let you know it it helps me to memorise them. To be scientific about it, I really should recruit another synaesthete (who would have different colours from my own, and so might be hindered by my colours) and a non-synaesthete to try it as well, and define exactly how much it should be studied and how to measure success. But I’m writing a blog, not running a study, so if you want to try it, download the file. (I’d love it if somebody did run a study to answer some of my questions, though. I’d add whatever features were necessary to the app.)
But these functions don’t go too far in answering the questions I asked earlier. How about reading a code? Well, I figured I’d be more likely to intuit letters from coloured things if they looked a little bit like letters: squiggles rather than blobs. So first I added a view that simply distorts the letters randomly by an amount that you can control with the slider. I did this fairly quickly, so there are no spaces or word-wrapping yet.

I can’t read it when it gets too distorted, but perhaps it’s easier to read at low-distortion than it would be if the letters were all black. Maybe I’d be able to learn to ‘read’ the distorted squiggles based on colour alone, but I doubt it. This randomly distorts the letters every time you change the distortion amount of change the text, and it doesn’t keep the same form for each occurrence of the same letter. Maybe if it did, I’d be able to learn and read the new graphemes more easily than a non-synaesthete would. Okay, how about just switching to a font that uses a fictional alphabet? Here’s some text in a Klingon font I found:
![]()
I know that Klingon is its own language, and you can’t just write English words in Klingon symbols and call it Klingon. But the Futurama alien language fonts I found didn’t work, and Interlac is too hollow to show much colour.
Anyhow, maybe with practice I’ll be able to read that ‘Klingon’ easily. I certainly can’t read it fluently, but even having never looked at a table showing the correspondence between letters and symbols, I can figure out some words if I think about it, even when I copy some random text without looking. I intend to add a button to fetch random text from the web, and hide the plain text version, to allow testing of reading things that the synaesthete has never seen before, but I didn’t have time for that.
Another thing I’ll probably do is add a display of the Japanese kana syllabaries using the consonant colour as the outline and the vowel colour as the fill.
Here’s a screenshot of the whole app:

As I mentioned, you can download it and try it for yourself. It works on Mac OS X 10.7, and maybe earlier versions too. To use it, either open my own colour file (which is included with the download) or create a new document and add some characters and colours in the top left. Then enter some text on the bottom left, and it will appear in all the boxes on the right side. If you change the font in the bottom left, say to a Klingon font, it will change in all the other displays except the distorted one.
This is something I’ve coded fairly hastily on the occasional train trip or weekend, usually forgetting what I was doing between stints, so there are many improvements that could be made, and several features already halfway developed. It could do with an icon and some in-app help, too. I’m still working on this, so if you have any ideas for it, I’m all ears.
AppleScript: Fixing tags of free music podcasts in iTunes
Posted by Angela Brett in The Afterlife on October 23, 2011
I’m a bit of a free music junkie. Free as in beer (or doughnuts, since I don’t like beer) is good, free as in speech is better, but this post is about the free as in doughnuts kind, which costs nothing until you get a taste for doughnuts and then end up buying out the whole Krispy Kreme, travelling around the world to have different doughnuts with different people, and getting too fat for your iPod. Download free music responsibly, kids (okay, I guess the beer metaphor would have made more sense.) Anyway, back to free music. One way I discover a lot of music is through podcasts which regularly publish individual songs. However, I use iTunes, and iTunes gives podcast tracks the name and artist given in the podcast feed (often taken from the title of a blog post) over whatever was set in the ID3 tags of the mp3 file itself. This might be a good idea for non-music podcasts, and maybe some music podcasts, where the details aren’t necessarily filled out, but for some of the music podcasts I subscribe to it doesn’t really work out. Particularly if there’s a blog post associated with each podcast episode, the title tends to include the artist name and sometimes some other information.
I can’t be bothered fixing all of the tracks manually, so a few years ago I wrote a few AppleScripts to fix up the metadata of the music podcasts I was subscribed to, and also add the tracks to my Songs playlist (which I use as the basis of most of my smart playlists) and turn off the ‘Remember position’ and ‘Skip while shuffling’ options that are turned on by default for podcast tracks. I’ve since subscribed to and made scripts to fix a few more music podcasts, and it occurred to me that other people might find the scripts useful, so I’ve just tidied up the code and added a way to choose which playlist to add the tracks to. There are links to the scripts and related podcasts below.

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported License.
Please tell me if you do something cool with it.

