Posts Tagged speech synthesis
Seddit 1.5 supports multilingual Reddit listening. Also, Joey sang my half-baked PSOLA song!
Posted by Angela Brett in My Software on October 9, 2025
A while ago I added the possibility to configure Seddit (my text-to-speech-focused hands-free Reddit client for macOS and iOS) with multiple voices so that each user’s content could be read in a different voice. Of course, iOS and macOS come with voices that speak a huge variety of different languages, so you could theoretically select, say, a Japanese voice, a French voice, and three English voices, and download Reddit posts and comments in all of those languages. However, until now, Seddit would randomly assign a voice to each user, without regard for the language that user had written in, so if you did that, you could end up with English posts pronounced as if they were French, Japanese character names read out in English, and so on.
In the latest version, if you select voices that speak multiple languages in the Voices tab of the Settings screen, when Seddit encounters a post or comment by a user it hasn’t chosen a voice for yet, it will detect which of those languages the post or comment is probably in, and choose a voice that knows how to pronounce that language.
Of course, this isn’t perfect — it still always uses the same voice for each user, so if a user sometimes posts in French, and sometimes in English, or if they write in multiple languages within a single post because it’s a language-learning subreddit, then some of that is going to be spoken using an inappropriate voice. Also, if someone only writes in English but the first comment that Seddit encounters of theirs is an image meme and the text ‘c’est la vie!’ Seddit might determine that the user speaks French, and then hilariously mispronounce the rest of their posts. Note, if there is not enough text in the user’s first post for Seddit to even guess the language, it will not definitively choose a voice for that user until it encounters another post by them. I have yet to find either of these situations in practice, even while looking for them, so I hope it’s a rare issue.

Nonetheless, all of these situations are better than Seddit just randomly picking a voice for each user, regardless of which language they happen to be writing in. You should try it out, especially if you want to listen to Reddit content in various languages!
I also redesigned the Settings screen on iOS and iPadOS so it’s fullscreen and has a close button in the top right, as per Apple’s human interface guidelines, instead of a ‘Done’ button taking up a lot of space at the bottom and making the tabs look weird.
Note, while writing this post, I tested the regular ‘Start Speaking’ menu command on macOS and the ‘Speak’ command on iOS and found that it will sometimes switch to appropriate voices if I select multilingual text, even if my System Speech Language est réglé sur えい語。 Okay, it doesn’t work well for the French/English parts of that sentence. Maybe it’s only good with switching between languages if I switch scripts, e.g. בַּרְוָזָן утконос カモノハシ. Yep, that works, although if I select any other text along with πλατύπους, it’ll read it as ‘Greek small letter pi’ etc. I guess Greek letters are used too often in English for the speech engine to assume we actually switched to Greek. There were certainly plenty of Greek letters in the Princeton Companion to Mathematics.
Anyhow, I’m thinking I could improve Seddit further by giving each user a voice in each language you’ve selected voices for, and detecting the language for each post/comment, or for each sentence. Though macOS doesn’t do that unless you switch scripts… when I tried adding ‘J’imagine qu’il choisit une nouvelle langue pour chaque phrase.’ as a separate sentence and selected it along with a few English sentences, it read the whole thing in a French voice.
On the subject of interesting text-to-speech behaviour, and interesting behaviour in general, remember my half-written Lola parody about Pitch Synchronous Overlap and Add? Well, the lovely Joey Marianer had an appointment in town a while ago, and sneakily recorded the song in a parking building as a surprise, because I’m usually home so there’s little chance to record things at home without my hearing. I was duly surprised and delighted. Even the disclaimer about the missing bridge sounds like it scans as a bridge! Now you can also be surprised, delighted, and probably confused as to why this half-baked song was considered worth singing.
So I leave my bags behind (Galilee Song parody, now actually sung!) and another new version of Seddit
Posted by Angela Brett in My Software, video on September 2, 2025
Hey look, Joey Marianer sang the parody song lyrics from my last post! Check there for the lyrics and the aviation incidents referenced.
There are some more song parody lyrics, but first, a word from my sponsor: me. Just like last time, I’ve released a new version of Seddit, my text-to-speech-focussed Reddit client for macOS and iOS. This has a feature I’ve wanted to add for a while — the possibility to select multiple voices, and read each user’s posts and comments in a different one. The variety makes it easier to keep paying attention when listening for a long time, and having each user consistently use the same voice should make it easier to follow conversations.
I made some other changes in this version too. Here’s a full list of them:
Features
- Added the possibility to have each user’s posts and comments spoken in a different voice
- Added settings for whether to read out the subreddit name, and date and time for each post.
- Added the option to load no comments — this was for Joey, who wanted to try listening to short story subreddits while obeying the “don’t read the comments” rule of the internet.
Bug fixes
- Fixed a bug whereby turning off the ‘Say “Link” instead of reading out URLs’ setting would not work
- Fixed a bug where comments that weren’t loaded would be read as “comment by unknown user” Comments that aren’t loaded due to the comment depth settings are also no longer displayed.
- Fixed a potential crash when opening the app if posts had been deleted on another device
On the subject of text-to-speech, nine or ten years ago I read a book and a bunch of papers on speech synthesis in order to write a term paper for my Web Development for Linguistics degree. The term paper was longer than the text of my thesis, because my thesis also included source code for a web site and a Mac app. Anyway, from this book I learnt about PSOLA (Pitch Synchronous Overlap and Add) which is used to change the pitch and duration of sounds for text-to-speech, as one might do to change prosody, or create a robot choir.
Newer voices don’t use PSOLA so much, as (to put it simply) they have more samples of actual speech in different situations, so they don’t need to modify samples for the sake of prosody. Note, this is ‘newer voices’ as of a decade or two ago; I don’t know whether the latest crop of ML-based voices do things the same way. Anyway, I assume this is why the newer macOS voices don’t support the TUNE format I used for my robot choir.
At the time, I wrote an utterly silly partial parody of Lola, by The Kinks, about PSOLA. I thought maybe I’d finish it or maybe even make it less silly[why?], but I never did, and now I don’t remember enough about how PSOLA works to fully understand what I originally wrote. So here is that draft. It really doesn’t scan, but I hope it doesn’t scan in amusing ways:
I was trying to synthesise some prosody,
but my source and filter were mixed up just like granola
G-R-A-N-O-L-A, granola.
So I found a new way to make it sound rad
It’s called pitch-synchronous overlap and add, that is PSOLA
P-S-O-L-A PSOLA. Pso-pso-pso-P-SOLA.
Well I didn’t want to sound like a smallpox blight
So I really took care with my to get my epochs right
for PSOLA. Pso-pso-pso-P-SOLA.
If you’re not dumb then you’ll soon understand
How I speak like a woman then sound like a man
It’s P-SOLA. Pso-pso-pso-P-SOLA. Pso-pso-pso-P-SOLA.
[It doesn’t look like I wrote anything for the bridge (is that a bridge?) of the song, so just pretend it keeps going roughly like before]
It was used to make synthesized speech sound natural
But now there’s some super-sized features that fill that role-uh
R-O-L-E hyphen U-H role-uh
So that’s my guess if you’re wondering why r-
ecent voices don’t sing in my robot choir:
No PSOLA.
Disinflections
Posted by Angela Brett in News on May 12, 2021
I enjoy taking words that have irregular inflections, and inflecting other words the same way — for instance, saying *squoke as the past tense of squeak, analogous with speak and spoke, or even *squought, analogous with seek and sought. Sometimes those disinflections, as I’ve decided to call them, look or sound like other words… for instance, analogous with fly, flew, and flown, I could use crew and crown as past tenses of cry, or boo and bone as past tenses of buy. Indeed, analogous with buy and bought, the past tense of fly could be *flought, but then again, perhaps the present tense of bought could be ‘batch’ or ‘beak’, or ‘bite’, analogous with caught and catch, or sought and seek, or fought and fight.
The Disinflectant app
For a while now, I’ve wanted to make an app to find these automatically, and now that I have a bit of free time, I’ve made a prototype, mostly reusing code I wrote to generate the rhyme database for Rhyme Science. I’m calling the app Disinflectant for now. Here’s what it does:
- Read words from a file and group them by lemma.
Words with the same lemma are usually related, though since this part is using text only, if two distinct lemmas are homographs (words with the same spelling but different meanings) such as bow🎀, bow🏹, bow🚢, and bow🙇🏻♀️, then they’re indistinguishable. This part is done using the Natural Language framework (henceforth referred to as ‘the lemmatiser’), so I didn’t write any complicated rules to do this. - Find out the pronunciation of the word, as text representing phonemes.
This is done using the text-to-speech framework, so again, nothing specific to Disinflectant. The pronunciation is given in phoneme symbols defined by the API, not IPA. - Find all the different ways that words with the same lemma can be transformed into another by switching a prefix or suffix for another. For instance:
| Transform type | Transform | by analogy with |
|---|---|---|
| Spelling suffix | y→own | fly→flown |
| Pronunciation suffix | IYk→AOt | seek→sought |
| Spelling prefix | e→o | eldest→oldest |
| Pronunciation prefix | 1AW→w1IY | our→we’re |
Most prefixes in English result in words with different lemmas, so Disinflectant didn’t find many prefix transforms, and the ones it found didn’t really correspond to any actual grammatical inflection. I had it prefer suffixes over prefixes, and only add a prefix transform if there is no suffix found, so that bus→buses would result in the spelling suffix transform ∅→es and not the prefix transform bu→buse.
Each transform can apply to multiple pairs of real words. I included a way to label each transform with something like ‘past tense’, so the app could ask, ‘why isn’t crew the past tense of cry?’ but didn’t end up filling in any of them, so it just calls them all inflections.
- Apply each transform individually to each word, and see whether the transformed version matches another word with a different lemma.
It could just make up words such as ‘squoke’, but then there would be hundreds of millions of possibilities and they wouldn’t be very interesting to sift through, so it’s better to look for real words that match.
That’s it. Really just four steps of collecting and comparing data, with all the linguistic heavy lifting done by existing frameworks.
The limitations
Before I show you some of the results, here are some limitations:
- So far I’ve only given it a word list, and not a text corpus. This means that any words which have different lemmas or different pronunciations depending on context (such as ‘moped’ in ‘she moped around’, with the lemma ‘mope’, vs. ‘she rode around on her moped’, with the lemma ‘moped’.) I have code to work with corpora to add homographs to rhyme.science, but I haven’t tried it in this app yet.
- It’s only working with prefixes and suffixes. So it might think ‘woke’ should be the past tense of ‘weak’ (by analogy with ‘speak’ and ‘spoke’) but won’t generalise that to, say, ‘slope’ as the past tense of ‘sleep’ unless there is another word ending in a p sound to model it on. I could fairly easily have it look for infix transforms as well, but haven’t done so yet.
- It doesn’t distinguish between lemmas which are spelled the same, as mentioned above.
The results
For my first full test run, I gave it the SCOWL 40 list, with 60523 words, and (after about a day and a half of processing on my mid-2014 MacBook Pro — it’s not particularly optimised yet) it found 157687 disinflections. The transform that applied to the most pairs of actually-related words was adding a ‘z’ sound to the end of a word, as for a plural or possessive noun or second-person present-tense verb ending in a voiced sound. This applies to 7471 pairs of examples. The SCOWL list I used includes possessives of a lot of words, so that probably inflates the count for this particular transform. It might be interesting to limit it to transforms with many real examples, or perhaps even more interesting to limit it to transforms with only one example.
I just had it log what it found, and when a transform applied to multiple pairs of words, pick a random pair to show for the ‘by analogy with’ part in parentheses. Here are some types of disinflections it found, roughly in order from least interesting to most interesting:
Words that actually are related, just not so much that they have the same lemma:
Some words are clearly derived from each other and maybe should have the same lemma; others just have related meanings and etymology.
- Why isn’t shoppers (S1AApIXrz) with lemma shopper the inflection of shops (S1AAps) with lemma shop? (by analogy with lighter’s → light’s)
- Why isn’t constraint (kIXnstr1EYnt) with constraint same the inflection of constrain (kIXnstr1EYn) with lemma constrain? (by analogy with shopped → shop)
- Why isn’t diagnose (d1AYIXgn1OWs) with lemma diagnose the inflection of diagnosis (d1AYIXgn1OWsIXs) with lemma diagnosis? (by analogy with he → his)
- Why isn’t sieves (s1IHvz) with lemma sieve the inflection of sift (s1IHft) with lemma sift? (by analogy with knives → knifed)
- Why isn’t snort (sn1AOrt) with lemma snort the inflection of snored (sn1AOrd) with lemma snore? (by analogy with leapt → leaped)
Words that definitely should have had the same lemma, for the same reason the words in the analogy do:
These represent bugs in the lemmatiser.
- Why isn’t patrolwoman’s (pIXtr1OWlwUHmIXnz) with lemma patrolwoman’s the inflection of patrolwomen (pIXtr1OWlwIHmIXn) with lemma patrolwomen? (by analogy with patrolman’s → patrolmen)
- Why isn’t blacker (bl1AEkIXr) with lemma black the inflection of blacken (bl1AEkIXn) with lemma blacken? (by analogy with whiter → whiten)
Transforms formed from words which have the same lemma, but probably shouldn’t:
These also probably represent bugs in the lemmatiser.
- Why isn’t car (k1AAr) with lemma car the inflection of air (1EHr) with lemma air? (by analogy with can’t → ain’t)
Both ‘can’t’ and ‘ain’t’ are given the lemma ‘not’. I don’t think this is correct, but it’s possible I’m using the API incorrectly or I don’t understand lemmatisation.
Words that are related, but the lemmatiser was considering an unrelated homograph of one of the words, and the actual related word was not picked up because of the first limitation above:
- Why isn’t skier’s (sk1IYIXrz) with lemma skier the inflection of skied (sk1IYd) with lemma sky? (by analogy with downer’s → downed)
In this case, the text-to-speech read ‘skied’ as the past tense of ‘ski’, but the lemmatiser read it as the past participle of ‘sky’, as in, ‘blue-skied’, which I think is a slightly obscure choice, and might be considered a bug in the lemmatiser. - Why isn’t ground (gr1AWnd) with lemma ground the inflection of grinding (gr1AYndIHN) with lemma grind? (by analogy with rewound → rewinding)
Here the lemmatiser is presumedly reading it as the noun or verb ‘ground’ rather than the past and past participle of ‘grind’.
Pronunciation transforms finding homophones of actual related words:
- Why isn’t sheikhs (S1EYks) with lemma sheikh the inflection of shaking (S1EYkIHN) with lemma shake? (by analogy with outstrips → outstripping)
‘Sheikhs’ sounds just like ‘shakes’, which is indeed the present tense or plural of ‘shake’. - Why isn’t soled (s1OWld) with lemma sole the inflection of selling (s1EHlIHN) with lemma sell? (by analogy with sold → selling)
‘Soled’ sounds just like ‘sold’, which is indeed the past tense of ‘sell’.
Pronunciation transforms based on an incorrect pronunciation:
These represent bugs in the text-to-speech. Try them yourself on a Mac by setting the system voice to an older American English one such as Victoria, selecting the word, and choosing Speech→Start Speaking from the Edit menu or the contextual menu.
- Why isn’t nape’s (n1AEpIYz) with lemma nape the inflection of nappy (n1AEpIY) with lemma nappy? (by analogy with suffocation’s → suffocation)
The text-to-speech pronounces ‘nape’ correctly, but pronounces ‘napes’ like ‘naps’ and ‘nape’s’ like ‘nappies’. - Why isn’t mice (m1AYs) with lemma mouse the inflection of me (m1IY) with lemma I? (by analogy with modernity’s → modernity)
The text-to-speech pronounces ‘modernity’ correctly, but pronounces ‘modernity’s’ like ‘modernitice’.
- Why isn’t queue’s (ky1UWz) with lemma queue the inflection of cubing (ky1UWbIHN) with lemma cubing? (by analogy with lambs → lambing)
The text-to-speech pronounces the ‘b’ in ‘lambing’. I’m not sure if there is an accent where this is the correct pronunciation, but it isn’t in the dictionaries I’ve checked.
Small transforms that can be applied to many other words:
Sometimes it will find that a word with the same lemma can have one letter or phonemes changed or added, and then there are a huge number of words that the transform can apply to. I wonder if you could almost change any final letter or phoneme to any other.
- Why isn’t mine (m1AYn) with lemma I the inflection of mind (m1AYnd) with lemma mind? (by analogy with shoe → shod)
- Why isn’t ham (h1AEm) with lemma ham the inflection of hay (h1EY) with lemma hay? (by analogy with them → they)
This one could also be extended to hair (from them → their) to get a full set of weird pronouns. - Why isn’t hearth (h1AArT) with lemma hearth the inflection of heart (h1AArt) with lemma heart? (by analogy with sheikh → sheik)
- Why isn’t captor (k1AEptIXr) with lemma captor the inflection of captain (k1AEptIXn) with lemma same? (by analogy with whiter → whiten)
- Why isn’t colt (k1OWlt) with lemma colt the inflection of coal (k1OWl) with lemma coal? (by analogy with shopped → shop)
Spelling prefixes and suffixes that don’t quite correspond to how the inflections are formed:
Sometimes changes such as doubling the final consonant are made when an -ing or -ed is added. Since Disinflectant only sees this as a suffix being added, it thinks that specific consonant can also be added to words that end in other consonants.
- Why isn’t braking (br1EYkIHN) with lemma brake the inflection of bra (br1AA) with lemma bra? (by analogy with picnicking → picnic)
- Why isn’t garbs (g1AArbz) with lemma garbs the inflection of garbling (g1AArblIHN) with lemma garble? (by analogy with corrals → corralling)
- Why isn’t badgering (b1AEJIXrIHN) with lemma badger the inflection of badge (b1AEJ) with lemma badge? (by analogy with transferring → transfer)
- Why isn’t bobsled (b1AAbslEHd) with lemma bobsled the inflection of bobs (b1AAbz) with lemma bob? (by analogy with patrolled → patrol)
Disinflection I might have come up with myself:
- Why isn’t hay (h1EY) with lemma hay the inflection of highs (h1AYz) with lemma high? (by analogy with lay → lies)
- Why isn’t bowled (b1OWld) with lemma bowl the inflection of belling (b1EHlIHN) with lemma bell? (by analogy with sold → selling)
- Why isn’t bodies (b1AAdIYz) with lemma body the inflection of bodice (b1AAdIXs) with lemma bodice? (by analogy with emphases → emphasis)
- Why isn’t lease (l1IYs) with lemma lease the inflection of loosed (l1UWst) with lemma loose? (by analogy with geese → goosed)
- Why isn’t wield (w1IYld) with lemma wield the inflection of welt (w1EHlt) with lemma welt? (by analogy with kneeled → knelt)
- Why isn’t gauze (g1AOz) with lemma gauze the inflection of goo (g1UW) with lemma goo? (by analogy with draws → drew)
- Why isn’t cheese (C1IYz) with lemma cheese the inflection of chosen (C1OWzIXn) with lemma choose? (by analogy with freeze → frozen)
Transforms based on abbreviations:
- Why isn’t chuckle (C1UXkIXl) with lemma chuckle the inflection of chuck’s (C1UXks) with lemma chuck? (by analogy with mile → mi’s)
- Why isn’t cooperative’s (kOW1AApIXrrIXtIHvz) with lemma cooperative the inflection of cooper (k1UWpIXr) with lemma cooper? (by analogy with negative’s → neg)
- Why isn’t someday (s1UXmdEY) with lemma someday the inflection of some (s1UXm) with lemma some? (by analogy with Friday → Fri)
Other really weird stuff I’d never think of:
- Why isn’t comedy (k1AAmIXdIY) with lemma comedy the inflection of comedown (k1UXmdAWn) with lemma comedown? (by analogy with fly → flown)
- Why isn’t aisle (1AYl) with lemma aisle the inflection of meal (m1IYl) with lemma meal? (by analogy with I → me)
- Why isn’t hand (h1AEnd) with lemma hand the inflection of hens (h1EHnz) with lemma hen? (by analogy with manned → men’s)
- Why isn’t out (1AWt) with lemma same the inflection of wheat (w1IYt) with lemma same? (by analogy with our → we’re)
If people are interested, once I’ve fixed it up a bit I could either release the app, or import a bigger word list and some corpora, and then publish the whole output as a CSV file. Meanwhile, I’ll probably just tweet or blog about the disinflections I find interesting.
Accessibility is for Everyone
Posted by Angela Brett in Culture, News on February 26, 2021
Accessibility is for everyone. I say that whenever an abled person finds a way that an accessibility feature benefits them. But that’s not all that it means. There are really three different meanings to that phrase:
- Accessibility exists to make things accessible to everyone.
- At some point, everyone has some kind of impairment which accessibility can help them with.
- Changes that make things more accessible can be useful, convenient, or just plain fun, even for people who are 100% unimpaired.
Is this article for everyone?
This is a bare-bones outline of ways accessibility is for everyone, with a few lists of examples from my personal experience, and not much prose. This topic is fractal, though, and like a Koch Snowflake, even its outline could extend to infinite length. I’ve linked to more in-depth references where I knew of them, but tried not to go too far into detail on how to make things accessible. There are much better references for that — let me know of the ones you like in the comments.
I am not everyone
Although I do face mobility challenges in the physical world, as a software developer, I know the most about accessibility as it applies to computers. Within that, I have most experience with text-to-speech, so a lot of the examples relate to that. I welcome comments on aspects I missed. I am not an expert on accessibility, but I’d like to be.
The accessibility challenges that affect me the most are:
- A lack of fluency in the language of the country I live in
- Being short (This sounds harmless, but I once burnt my finger slightly because my microwave is mounted above my line of sight.)
- Cerebral palsy spastic diplegia
That last thing does not actually affect how I use computers very much, but it is the reason I’ve had experience with modern computers from a young age.
Accessibility makes things accessible to everyone
Accessibility is for everyone — it allows everyone to use or take part in something, not just people with a certain range of abilities. This is the real goal of accessibility, and this alone is enough to justify improving accessibility. The later points in this article might help to convince people to allocate resources to accessibility, but always keep this goal in mind.
Ideally, everyone should be able to use a product without asking for special accommodations. If not, there should be a plan to accommodate those who ask, when possible. At the very least, nobody should be made to feel like they’re being too demanding just for asking for the same level of access other people get by default. Accessibility is not a feature — lack of accessibility is a bug.
Don’t make people ask
If some people have to ask questions when others don’t, the product is already less accessible to them — even if you can provide everything they ask for. This applies in a few scenarios:
- Asking for help to use the product (e.g. help getting into a building, or using a app)
- Asking for help accessing the accessibility accommodations. For example, asking for the key for an elevator, or needing someone else to configure the accessibility settings in software. Apple does a great job of this by asking about accessibility needs, with the relevant options turned on, during installation of macOS.
- Asking about the accommodations available to find out if something is accessible to them before wasting time, spoons, or money on it. Make this information publicly available, e.g. on the website of your venue or event, or in your app’s description. Here’s a guide on writing good accessibility information.
Asking takes time and effort, and it can be difficult and embarrassing, whether because someone has to ask many times a day, or because they don’t usually need help and don’t like acknowledging when they do.
In software, ‘making people ask’ is making them set up accessibility in your app when they’ve already configured the accessibility accommodations they need in the operating system. Use the system settings, rather than having your own settings for font size, dark mode, and so on. If the user has to find your extra settings before they can even use your app, there’s a good chance they won’t. Use system components as much as possible, and they’ll respect accessibility options you don’t even know about.
If they ask, have an answer
Perhaps you don’t have the resources to provide certain accommodations to everyone automatically, or it doesn’t make sense to. In that case:
- make it clear what is available.
- make asking for it as easy as possible (e.g. a checkbox or text field on a booking form, rather than instructions to call somebody)
- make an effort to provide whatever it is to those who ask for it.
Assume the person really does need what they’re asking for — they know their situation better than you do.
If the answer is ‘no, sorry’, be compassionate about it
If you can’t make something accessible to a given group of people, don’t feel bad; we all have our limitations. But don’t make those people feel bad either — they have their limitations too, and they’re the ones missing out on something because of it. Remember that they’re only asking for the same thing everyone else gets automatically — they didn’t choose to need help just to annoy you.
If you simply didn’t think about their particular situation, talk with them about steps you could take. Don’t assume you know what they can or can’t do, or what will help them.
Everyone can be impaired
Accessibility is for everyone. But just like how even though all lives matter it is unfortunately still necessary to remind some people that black lives do, to achieve accessibility for everyone, we need to focus on the people who don’t get it by default. So who are they?
Apple’s human interface guidelines for accessibility say this better than I could:
Approximately one in seven people worldwide have a disability or impairment that affects the way they interact with the world and their devices. People can experience impairments at any age, for any duration, and at varying levels of severity. Situational impairments — temporary conditions such as driving a car, hiking on a bright day, or studying in a quiet library — can affect the way almost everyone interacts with their devices at various times.
Almost everyone.
This section will mostly focus on accessibility of devices such as computers, tablets, and phones. It’s what I know best, and malfunctioning hardware can be another source of impairment. Even if you don’t consider yourself disabled, if you haven’t looked through the accessibility settings of your devices yet, do so — you’re sure to find something that will be useful to you in some situations. I’ll list some ways accessibility can help with hardware issues and other situational impairments below.
Apple defines four main kinds of impairment:
Vision
There’s a big gap between someone with 20/20 full-colour vision in a well-lit room looking at an appropriately-sized, undamaged screen, and someone with no vision whatsoever. There’s even a big gap between someone who is legally blind and someone with no vision whatsoever. Whenever we are not at the most abled end of that spectrum, visual accessibility tools can help.
Here are some situations where I’ve used Vision accessibility settings to overcome purely situational impairments:
- When sharing a screen over a videoconference or to a projector, use screen zoom, and large cursor or font sizes. On macOS when using a projector, you can also use Hover Text, however this does not show up when screensharing over a videoconference. This makes things visible to the audience regardless of the size of their videoconference window or how far they are from the projector screen.
- When an internet connection is slow, or you don’t want to load potential tracking images in emails, image descriptions (alt text) let you know what you’re missing.
- When a monitor doesn’t work until the necessary software is installed and configured, use a screenreader to get through the setup. I’ve done this on a Mac, after looking up how to use VoiceOver on another device.
Hearing
There’s a big gap between someone with perfect hearing and auditory processing using good speakers at a reasonable volume in an otherwise-quiet room, and someone who hears nothing at all. There’s even a big gap between someone who is Deaf and someone who hears nothing at all. Whenever we are not at the most abled end of that spectrum, hearing accessibility tools can help.
Here are some situations where I’ve used Hearing accessibility settings when the environment or hardware was the only barrier:
- When one speaker is faulty, change the panning settings to only play in the working speaker, and turn on ‘Play stereo audio as mono’.
- When a room is noisy or you don’t want to disturb others with sound, use closed captions.
Physical and Motor
There’s a big gap between someone with a full range of controlled, pain-free movement using a perfectly-functioning device, in an environment tailored to their body size, and someone who can only voluntarily twitch a single cheek muscle (sorry, but we can’t all be Stephen Hawking.) Whenever we are not at the most abled end of that spectrum, motor accessibility tools can help.
Here are some situations where you can use Physical and Motor accessibility to overcome purely situational impairments:
- When a physical button on an iPhone doesn’t work reliably, use Back Tap, Custom Gestures, or the AssistiveTouch button to take over its function.
- When you’re carrying something bulky, use an elevator. I’ve shared elevators with people who have strollers, small dogs, bicycles, suitcases, large purchases, and disabilities. I’ve also been yelled at by someone who didn’t think I should use an elevator, because unlike him, I had no suitcase. Don’t be that person.
Literacy and Learning
This one is also called Cognitive. There’s a big gap between an alert, literate, neurotypical adult of average intelligence with knowledge of the relevant environment and language, and… perhaps you’ve thought of a disliked public figure you’d claim is on the other end of this spectrum. There’s even a big gap between that person and the other end of this spectrum, and people in that gap don’t deserve to be compared to whomever you dislike. Whenever we are not at the most abled end of that spectrum, cognitive accessibility considerations can help.
Here are some situations where I’ve used accessibility when the environment was the only barrier to literacy:
- When watching or listening to content in a language you know but are not fluent in, use closed captions or transcripts to help you work out what the words are, and find out the spelling to look them up.
- When reading in a language you know but are not fluent in, use text-to-speech in that language to find out how the words are pronounced.
- When consuming content in a language you don’t know, use subtitles or translations.
Accessibility features benefit abled people
Sometimes it’s hard to say what was created for the sake of accessibility and what wasn’t. Sometimes products for the general public bring in the funding needed to improve assistive technologies. Here are some widely-used things which have an accessibility aspect:
- The Segway was based on self-balancing technology originally developed for wheelchairs. Segways and the like are still used by some people as mobility devices, even if they are not always recognised as such.
- Voice assistants such as Siri rely on speech recognition and speech synthesis technology that has applications in all four domains of accessibility mentioned above.
- Light or Dark mode may be a style choice for one person and an essential visual accessibility tool for another.
Other technology is more strongly associated with accessibility. Even when your body, your devices, or your environment don’t present any relevant impairment, there are still ways that these things can be useful, convenient, or just plain fun.
Useful
Some accessibility accommodations let abled people do things they couldn’t do otherwise.
- Transcripts, closed captions, and image descriptions are easily searchable.
- I’ve used text-to-speech APIs to generate the initial rhyme database for my rhyming dictionary, rhyme.science
- I’ve used text-to-speech to find out how words are pronounced in different languages and accents.
- Menstruators can use handbasins in accessible restroom stalls to rinse out menstrual cups in privacy. (This is not an argument for using accessible stalls when you don’t need them — it’s an argument for more handbasins installed in stalls!)
Convenient
Some accessibility tech lets abled people do things they would be able to do without it, but in a more convenient way.
- People who don’t like switching between keyboard and mouse can enable full keyboard access on macOS to tab through all controls. They can also use keyboard shortcuts.
- People who don’t want to watch an entire video to find out a piece of information can quickly skim a transcript.
- I’ve used speak announcements on my Mac for decades. If my Mac announces something while I’m on the other side of the room, I know whether I need to get up and do something about it.
- Meeting attendees could edit automatic transcripts from videoconferencing software (e.g. Live Transcription in Zoom) to make meeting minutes.
- I’ve used text-to-speech on macOS and iOS to speak the names of emojis when I wasn’t sure what they were.
- Pre-chopped produce and other prepared foods save time even for people who have the dexterity and executive function to prepare them themselves.
Fun
Some accessibility tech lets us do things that are not exactly useful, but a lot of fun.
- Hosts of the Lingthusiasm podcast, Lauren Gawne and Gretchen McCulloch, along with Janelle Shane, fed transcripts of their podcasts into an artificial intelligence to generate a quirky script for a new episode, and then recorded that script.
- I’ve used text-to-speech to sing songs I wrote that I was too shy to sing myself.
- I’ve used text-to-speech APIs to detect haiku in any text.
- Automated captions of video conferencing software and videos make amusing mistakes that can make any virtual party more fun. Once you finish laughing, make sure anyone who needed the captions knows what was really said.
- I may have used the ’say’ command on a server through an ssh connection to surprise and confuse co-workers in another room. 😏
- I find stairs much more accessible if they have a handrail. You might find it much more fun to slide down the balustrade. 😁
Advocating accessibility is for everyone
I hope you’ve learnt something about how or why to improve accessibility, or found out ways accessibility can improve your own life. I’d like to learn something too, so put your own ideas or resources in the comments!
Audio Word Clouds
Posted by Angela Brett in News on August 1, 2020
For my comprehensive channel trailer, I created a word cloud of the words used in titles and descriptions of the videos uploaded each month. Word clouds have been around for a while now, so that’s nothing unusual. For the soundtrack, I wanted to make audio versions of these word clouds using text-to-speech, with the most common words being spoken louder. This way people with either hearing or vision impairments would have a somewhat similar experience of the trailer, and people with no such impairments would have the same surplus of information blasted at them in two ways.
I checked to see if anyone had made audio word clouds before, and found Audio Cloud: Creation and Rendering, which makes me wonder if I should write an academic paper about my audio word clouds. That paper describes an audio word cloud created from audio recordings using speech-to-text, while I wanted to create one from text using text-to-speech. I was mainly interested in any insights into the number of words we could perceive at once at various volumes or voices. In the end, I just tried a few things and used my own perception and that of a few friends to decide what worked. Did it work? You tell me.

Voices
There’s a huge variety of English voices available on macOS, with accents from Australia, India, Ireland, Scotland, South Africa, the United Kingdom, and the United States, and I’ve installed most of them. I excluded the voices whose speaking speed can’t be changed, such as Good News, and a few novelty voices, such as Bubbles, which aren’t comprehensible enough when there’s a lot of noise from other voices. I ended up with 30 usable voices. I increased the volume of a few which were harder to understand when quiet.
I wondered whether it might work best with only one or a few voices or accents in each cloud, analogous to the single font in each visual word cloud. That way people would have a little time to adapt to understand those specific voices rather than struggling with an unfamiliar voice or accent with each word. On the other hand, maybe it would be better to have as many voices as possible in each word cloud so that people could distinguish between words spoken simultaneously by voice, just as we do in real life. In the end I chose the voice for each word randomly, and never got around to trying the fewer-distinct-voices version. Being already familiar with many of these voices, I’m not sure I would have been a good judge of whether that made it easier to get used to them.
Arranging the words
It turns out making an audio word cloud is simpler than making a visual one. There’s only one dimension in an audio word cloud — time. Volume could be thought of as sort of a second dimension, as my code would search through the time span for a free rectangle of the right duration with enough free volume. I later wrote an AppleScript to create ‘visual audio word clouds’ in OmniGraffle showing how the words fit into a time/volume rectangle. I’ve thus illustrated this post with a visual word cloud of this post, and a few audio word clouds and visual audio word clouds of this post with various settings.
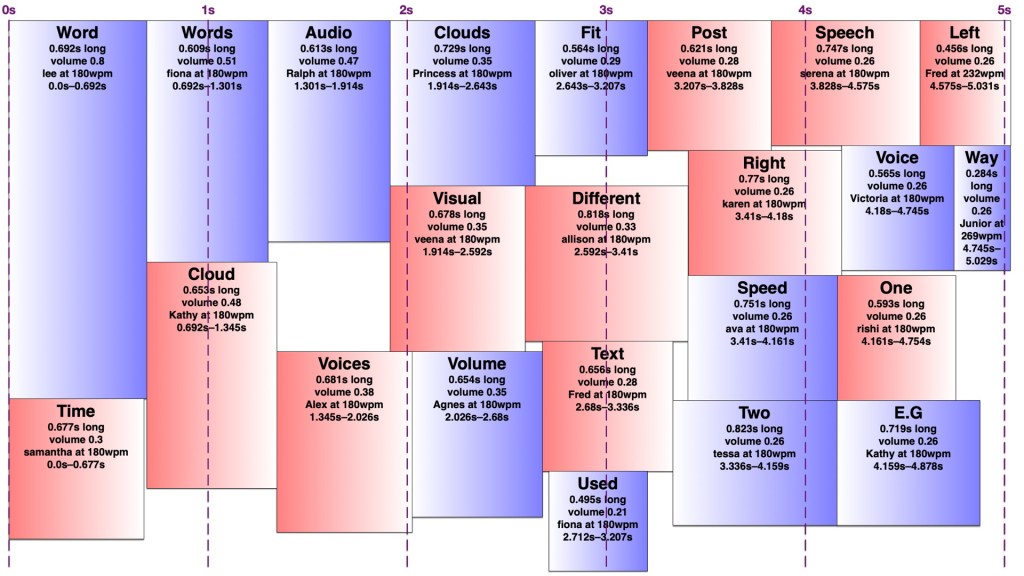
However, words in an audio word cloud can’t be oriented vertically as they can in a visual word cloud, nor can there really be ‘vertical’ space between two words, so it was only necessary to search along one dimension for a suitable space. I limited the word clouds to five seconds, and discarded any words that wouldn’t fit in that time, since it’s a lot easier to display 301032 words somewhat understandably in nine minutes than it is to speak them. I used the most common (and therefore louder) words first, sorted by length, and stopped filling the audio word cloud once I reached a word that would no longer fit. It would sometimes still be possible to fit a shorter, less common word in that cloud, but I didn’t want to include words much less common than the words I had to exclude.
I set a preferred volume for each word based on its frequency (with a given minimum and maximum volume so I wouldn’t end up with a hundred extremely quiet words spoken at once) and decided on a maximum total volume allowed at any given point. I didn’t particularly take into account the logarithmic nature of sound perception. I then found a time in the word cloud where the word would fit at its preferred volume when spoken by the randomly-chosen voice. If it didn’t fit, I would see if there was room to put it at a lower volume. If not, I’d look for places it could fit by increasing the speaking speed (up to a given maximum) and if there was still nowhere, I’d increase the speaking speed and decrease the volume at once. I’d prioritise reducing the volume over increasing the speed, to keep it understandable to people not used to VoiceOver-level speaking speeds. Because of the one-and-a-bit dimensionality of the audio word cloud, it was easy to determine how much to decrease the volume and/or increase the speed to fill any gap exactly. However, I was still left with gaps too short to fit any word at an understandable speed, and slivers of remaining volume smaller than my per-word minimum.
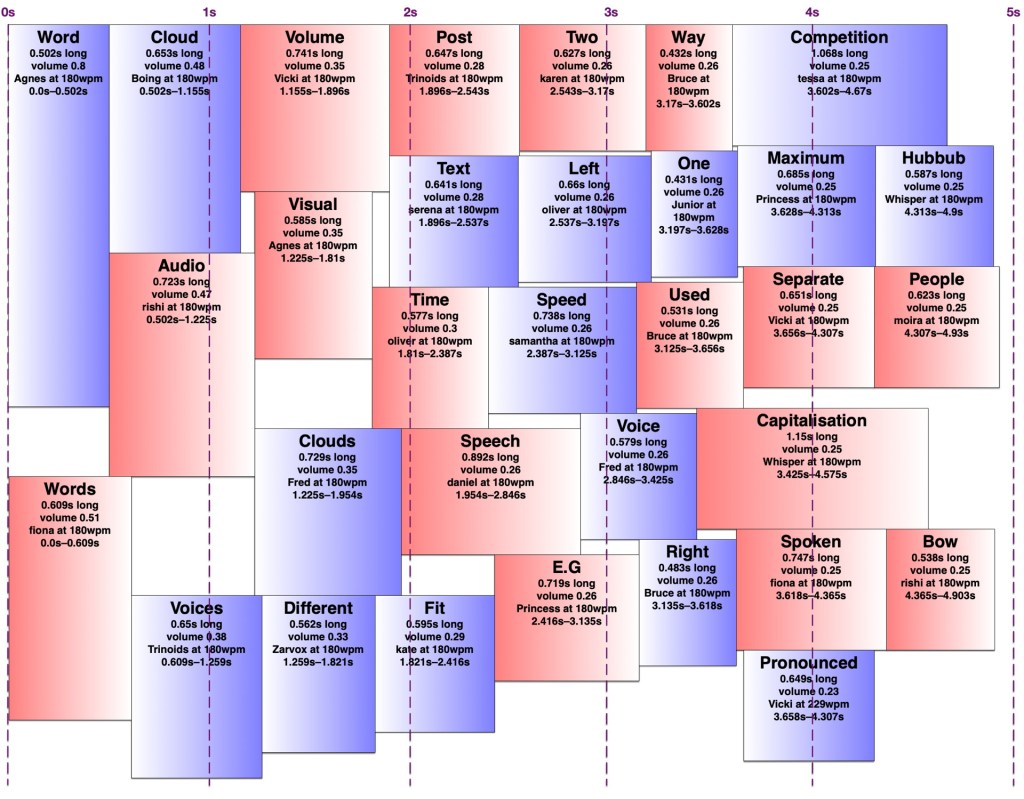
I experimented with different minimum and maximum word volumes, and maximum total volumes, which all affected how many voices might speak at once (the ‘hubbub level’, as I call it). Quite late in the game, I realised I could have some voices in the right ear and some in the left, which makes it easier to distinguish them. In theory, each word could be coming from a random location around the listener, but I kept to left and right — in fact, I generated separate left and right tracks and adjusted the panning in Final Cut Pro. Rather than changing the logic to have two separate channels to search for audio space in, I simply made my app alternate between left and right when creating the final tracks. By doing this, I could increase the total hubbub level while keeping many of the words understandable. However, the longer it went on for, the more taxing it was to listen to, so I decided to keep the hubbub level fairly low.
The algorithm is deterministic, but since voices are chosen randomly, and different voices take different amounts of time to speak the same words even at the same number of words per minute, the audio word clouds created from the same text can differ considerably. Once I’d decided on the hubbub level, I got my app to create a random one for each month, then regenerated any where I thought certain words were too difficult to understand.
Capitalisation

In my visual word clouds, I kept the algorithm case-sensitive, so that a word with the same spelling but different capitalisation would be counted as a separate word, and displayed twice. There are arguments for keeping it like this, and arguments to collapse capitalisations into the same word — but which capitalisation of it? My main reason for keeping the case-sensitivity was so that the word cloud of Joey singing the entries to our MathsJam Competition Competition competition would have the word ‘competition’ in it twice.
Sometimes these really are separate words with different meanings (e.g. US and us, apple and Apple, polish and Polish, together and ToGetHer) and sometimes they’re not. Sometimes these two words with different meanings are pronounced the same way, other times they’re not. But at least in a visual word cloud, the viewer always has a way of understanding why the same word appears twice. For the audio word cloud, I decided to treat different capitalisations as the same word, but as I’ve mentioned, capitalisation does matter in the pronunciation, so I needed to be careful about which capitalisation of each word to send to the text-to-speech engine. Most voices pronounce ‘JoCo’ (short for Jonathan Coulton, pronounced with the same vowels as ‘go-go’) correctly, but would pronounce ‘joco’ or ‘Joco’ as ‘jocko’, with a different vowel in the first syllable. I ended up counting any words with non-initial capitals (e.g. JoCo, US) as separate words, but treating title-case words (with only the initial letter capitalised) as the same as all-lowercase, and pronouncing them in title-case so I wouldn’t risk mispronouncing names.
Further work
A really smart version of this would get the pronunciation of each word in context (the same way my rhyming dictionary rhyme.science finds rhymes for the different pronunciations of homographs, e.g. bow), group them by how they were pronounced, and make a word cloud of words grouped entirely by pronunciation rather than spelling, so ‘polish’ and ‘Polish’ would appear separately but there would be no danger of, say ‘rain’ and ‘reign’ both appearing in the audio word cloud and sounding like duplicates. However, which words are actually pronounced the same depend on the accent (e.g. whether ‘cot’ and ‘caught’ sound the same) and text normalisation of the voice — you might have noticed that some of the audio word clouds in the trailer have ‘aye-aye’ while others have ‘two’ for the Roman numeral ‘II’.
Similarly, a really smart visual word cloud would use natural language processing to separate out different meanings of homographs (e.g. bow🎀, bow🏹, bow🚢, and bow🙇🏻♀️) and display them in some way that made it obvious which was which, e.g. by using different symbols, fonts, styles, colours for different parts of speech. It could also recognise names and keep multi-word names together, count words with the same lemma as the same, and cluster words by semantic similarity, thus putting ‘Zoe Keating’ near ‘cello’, and ‘Zoe Gray’ near ‘Brian Gray’ and far away from ‘Blue’. Perhaps I’ll work on that next.

I’ve recently been updated to a new WordPress editor whose ‘preview’ function gives a ‘page not found’ error, so I’m just going to publish this and hope it looks okay. If you’re here early enough to see that it doesn’t, thanks for being so enthusiastic!
How to fit 301032 words into nine minutes
Posted by Angela Brett in News on July 14, 2020
A few months ago I wrote an app to download my YouTube metadata, and I blogged some statistics about it and some haiku I found in my video titles and descriptions. I also created a few word clouds from the titles and descriptions. In that post, I said:
Next perhaps I’ll make word clouds of my YouTube descriptions from various time periods, to show what I was uploading at the time. […] Eventually, some of the content I create from my YouTube metadata will make it into a YouTube video of its own — perhaps finally a real channel trailer.
Me, two and a third months ago
TL;DR: I made a channel trailer of audiovisual word clouds showing each month of uploads:
It seemed like the only way to do justice to the number and variety of videos I’ve uploaded over the past thirteen years. My channel doesn’t exactly have a content strategy. This is best watched on a large screen with stereo sound, but there is no way you will catch everything anyway. Prepare to be overwhelmed.
Now for the ‘too long; don’t feel obliged to read’ part on how I did it. I’ve uploaded videos in 107 distinct months, so creating a word cloud for each month using wordclouds.com seemed tedious and slow. I looked into web APIs for creating word clouds automatically, and added the code to my app to call them, but then I realised I’d have to sign up for an account, including a payment method, and once I ran out of free word clouds I’d be paying a couple of cents each. That could easily add up to $5 or more if I wanted to try different settings! So obviously I would need to spend many hours programming to avoid that expense.
I have a well-deserved reputation for being something of a gadget freak, and am rarely happier than when spending an entire day programming my computer to perform automatically a task that it would otherwise take me a good ten seconds to do by hand. Ten seconds, I tell myself, is ten seconds. Time is valuable and ten seconds’ worth of it is well worth the investment of a day’s happy activity working out a way of saving it.
Douglas Adams in ‘Last chance to see…’
I searched for free word cloud code in Swift, downloaded the first one I found, and then it was a simple matter of changing it to work on macOS instead of iOS, fixing some alignment issues, getting it to create an image instead of arranging text labels, adding some code to count word frequencies and exclude common English words, giving it colour schemes, background images, and the ability to show smaller words inside characters of other words, getting it to work in 1116 different fonts, export a copy of the cloud to disk at various points during the progress, and also create a straightforward text rendering using the same colour scheme as a word cloud for the intro… before I knew it, I had an app that would automatically create a word cloud from the titles and descriptions of each month’s public uploads, shown over the thumbnail of the most-viewed video from that month, in colour schemes chosen randomly from the ones I’d created in the app, and a different font for each month. I’m not going to submit a pull request; the code is essentially unrecognisable now.
In case any of the thumbnails spark your curiosity, or you just think the trailer was too short and you’d rather watch 107 full videos to get an idea of my channel, here is a playlist of all the videos whose thumbnails are shown in this video:
It’s a mixture of super-popular videos and videos which didn’t have much competition in a given month.
Of course, I needed a soundtrack for my trailer. Music wouldn’t do, because that would reduce my channel trailer to a mere song for anyone who couldn’t see it well. So I wrote some code to make an audio version of each word cloud (or however much of it could fit into five seconds without too many overlapping voices) using the many text-to-speech voices in macOS, with the most common words being spoken louder. I’ll write a separate post about that; I started writing it up here and it got too long.
The handwritten thank you notes at the end were mostly from members of the JoCo Cruise postcard trading club, although one came with a pandemic care package from my current employer. I have regaled people there with various ridiculous stories about my life, and shown them my channel. You’re all most welcome; it’s been fun rewatching the concert videos myself while preparing to upload, and it’s always great to know other people enjoy them too.
I put all the images and sounds together into a video using Final Cut Pro 10.4.8. This was all done on my mid-2014 Retina 15-inch MacBook Pro, Sneuf.
Another Haiku Detector Update, and Some Observations on Mac Speech Synthesis
Posted by Angela Brett in Haiku Detector on May 18, 2015

I subjected Haiku Detector to some serious stress-testing with a 29MB text file (that’s 671481 sentences, containing 16810 haiku, of which some are intentional) a few days ago, and kept finding more things that needed fixing or could do with improvement. A few days in a nerdsniped daze later, I have a new version, and some interesting tidbits about the way Mac speech synthesis pronounces things. Here’s some of what I did:
- Tweaked the user interface a bit, partly to improve responsiveness after 10000 or so haiku have been found.
- Made the list of haiku stay scrolled to the bottom so you can see the new ones as they’re found.
- Added a progress bar instead of the spinner that was there before.
- Fixed a memory issue.
- Changed a setting so it should work in Mac OS X 10.6, as I said here it would, but I didn’t have a 10.6 system to test it on, and it turns out it does not run on one. I think 10.7 (Lion) is the lowest version it will run on.
- Added some example text on startup so that it’s easier to know what to do.
- Made it a Developer ID signed application, because now that I have a bit more time to do Mac development (since I don’t have a day job; would you like to hire me?), it was worth signing up to the paid Mac Developer Program again. Once I get an icon for Haiku Detector, I’ll put it on the app store.
- Fixed a few bugs and made a few other changes relating to how syllables are counted, which lines certain punctuation goes on, and which things are counted as haiku.
That last item is more difficult than you’d think, because the Mac speech synthesis engine (which I use to count syllables for Haiku Detector) is very clever, and pronounces words differently depending on context and punctuation. Going through words until the right number of syllables for a given line of the haiku are reached can produce different results depending on which punctuation you keep, and a sentence or group of sentences which is pronounced with 17 syllables as a whole might not have words in it which add up to 17 syllables, or it might, but only if you keep a given punctuation mark at the start of one line or the end of the previous. There are therefore many cases where the speech synthesis says the syllable count of each line is wrong but the sum of the words is correct, or vice versa, and I had to make some decisions on which of those to keep. I’ve made better decisions in this version than the last one, but I may well change things in the next version if it gives better results.
Here are some interesting examples of words which are pronounced differently depending on punctuation or context:
| ooohh | Pronounced with one syllable, as you would expect |
| ooohh. | Pronounced with one syllable, as you would expect |
| ooohh.. | Spelled out (Oh oh oh aitch aitch) |
| ooohh… | Pronounced with one syllable, as you would expect |
| H H | Pronounced aitch aitch |
| H H H | Pronounced aitch aitch aitch |
| H H H H H H H H | Pronounced aitch aitch aitch |
| Da-da-de-de-da | Pronounced with five syllables, roughly as you would expect |
| Da-da-de-de-da- | Pronounced dee-ay-dash-di-dash-di-dash-di-dash-di-dash. The dashes are pronounced for anything with hyphens in it that also ends in a hyphen, despite the fact that when splitting Da-da-de-de-da-de-da-de-da-de-da-de-da-da-de-da-da into a haiku, it’s correct punctuation to leave the hyphen at the end of the line:
Da-da-de-de-da- Though in a different context, where – is a minus sign, and meant to be pronounced, it might need to go at the start of the next line. Greater-than and less-than signs have the same ambiguity, as they are not pronounced when they surround a single word as in an html tag, but are if they are unmatched or surround multiple words separated by spaces. Incidentally, surrounding da-da in angle brackets causes the dash to be pronounced where it otherwise wouldn’t be. |
| U.S or u.s | Pronounced you dot es (this way, domain names such as angelastic.com are pronounced correctly.) |
| U.S. or u.s. | Pronounced you es |
| US | Pronounced you es, unless in a capitalised sentence such as ‘TAKE US AWAY’, where it’s pronounced ‘us’ |
I also discovered what I’m pretty sure is a bug, and I’ve reported it to Apple. If two carriage returns (not newlines) are followed by any integer, then a dot, then a space, the number is pronounced ‘zero’ no matter what it is. You can try it with this file; download the file, open it in TextEdit, select the entire text of the file, then go to the Edit menu, Speech submenu, and choose ‘Start Speaking’. Quite a few haiku were missed or spuriously found due to that bug, but I happened to find it when trimming out harmless whitespace.
Apart from that bug, it’s all very clever. Note how even without the correct punctuation, it pronounces the ‘dr’s and ‘st’s in this sentence correctly:
the dr who lives on rodeo dr who is better than the dr I met on the st john’s st turnpike
However, it pronounces the second ‘st’ as ‘saint’ in the following:
the dr who lives on rodeo dr who is better than the dr I met in the st john’s st john
This is not just because it knows there is a saint called John; strangely enough, it also gets this one wrong:
the dr who lives on rodeo dr who is better than the dr I met in the st john’s st park
I could play with this all day, or all night, and indeed I have for the last couple of days, but now it’s your turn. Download the new Haiku Detector and paste your favourite novels, theses, holy texts or discussion threads into it.
If you don’t have a Mac, you’ll have to make do with a few more haiku from the New Scientist special issue on the brain which I mentioned in the last post:
Being a baby
is like paying attention
with most of our brain.
But that doesn’t mean
there isn’t a sex difference
in the brain,” he says.
They may even be
a different kind of cell that
just looks similar.
It is easy to
see how the mind and the brain
became equated.
We like to think of
ourselves as rational and
logical creatures.
It didn’t seem to
matter that the content of
these dreams was obtuse.
I’d like to thank the people of the xkcd Time discussion thread for writing so much in so many strange ways, and especially Sciscitor for exporting the entire thread as text. It was the test data set that kept on giving.
Better (Robot-to-Human version)
Posted by Angela Brett in The Afterlife, Things To Listen To on January 23, 2015
I’ve been thinking of getting my robot choir (an app I wrote to make my Mac’s speech synthesis sing) to sing Jonathan Coulton covers for a while, but as many of his songs involve robots, singing them with a robot voice forces a change of perspective. I rewrote Better to be from the perspective of a robot whose partner is becoming human, rather than a human whose partner is becoming a robot. Here‘s a rough recording of it using the Trinoids voice and the karaoke file for the song:
Here are the lyrics:
Where did we go?
When was the moment that we came unplugged?
I think I know.
In fact I am sure ’cause I’ve had your chips bugged.
I remember the first big surprise,
the day you came home with your infant-bred eyes.
I looked inside them and lased you a note
but your return signal was smoke.
But it’s not smoke, it’s fire,
and your burning desire
to turn into something
that I don’t require.
You used to be OK
and I liked you that way,
but I don’t think that I like you better.
No I don’t think that I like you better.
Started out small:
some lungs and a heart and your lasers unwired.
Now you’re just six feet tall.
Even when fully charged your organics get tired.
And I’m tired of the evenings I spend
making small talk with your new human friends
and their stupid insistence on blocking my lasers
when they know I know the three laws.
And you climbed the wrong way out
of the uncanny gorge.
You went from bad data
to bad Geordi La Forge.
You used to be OK
and I liked you that way,
but I don’t think that I like you better.
No I don’t think that I like you better.
So that’s how it goes.
Tap my interface once if you still understand.
No data flows.
Wait, are your digits just five on your hand?
I can tell by your insider art
There’s more than a pump in your chimpanzee heart.
I tried to reason, but something’s gone wrong.
Why am I singing a song?
Well, I like to think different, but it’s not quite the same.
If this is a trojan, I know who to blame.
You used to be flawless; now you’re F-ing lawless,
and I don’t think that I like you better.
No I don’t think that I like you better.
Some lines stay close to the original when I perhaps should have struck out and gone with something completely different. If you have any suggestions, let me know; the beauty of robots is I can change the words and make a new recording in seconds.
The tune is based on Spektugalo’s UltraStar file for that song. I had to make some changes to the robot choir to handle the one-beat gaps between notes, and I made a few tweaks to timing after that, which probably messed up more than they fixed. When I started writing this parody, I assumed I had the source tracks of the original song to work with, but it turns out that song is not on JoCo Looks Back, so all I have is the karaoke version with some backing vocals. I’ve turned the volume of my vocals way up, both so they’re easier to understand and to obscure the backing vocals more when the lyrics are not the same. Consider this a demo.
Now that I have the tune done, I’ll probably record the original song and my entitled hipster parody of it soon. Maybe not too soon, though; I have a cruise to go on!
On the subject of cruises, I’ve just had some copies of my They Might Not Be Giants poster printed, and I’ll bring them with me on JoCo Cruise Crazy. If you are going on the cruise (or will just be in the area the night before) and you would like to buy one from me for less than it would cost through Zazzle, let me know and I’ll make sure I bring one for you. I can’t sell them on board the ship due to the cruise line needing a cut, but I can do so at the hotel before the cruise, the cruise port or airport after, or we can work out some kind of trade involving upcharged food or drink on the ship. They are A3 sized (just a tiny bit smaller than 11×17 inches) and printed beautifully on 300gsm silk-coated paper.
Recording: Te Harinui
Posted by Angela Brett in Culture, Holidailies, Things To Listen To on December 24, 2014
When Europeans colonised New Zealand, they brought not only mammals to drive many of the native birds to extinction, but also their religion to exterminate the native theodiversity. This began with Reverend Samuel Marsden on Christmas Day 1814, and there is a Christmas carol about it called Te Harinui. Since it just turned Christmas day about an hour ago in New Zealand, here‘s a recording of Te Harinui I just made.
It’s sung by the voice Vicki from my robot choir (an app I wrote to make my Mac sing using the built-in speech synthesis.) It has a couple of little glitches, and I couldn’t get it to pronounce the Māori words exactly right, but otherwise, I think this is the best Vicki has ever sounded. Usually I switch to Victoria because Vicki’s singing sounds weird. I made a couple of tweaks to the time allocated to consonants, and I think they helped. I used the music in the New Zealand Folk Song page, with a few small changes to the ‘glad tidings’ line to make it sound more like how I remember it.
You can see the effect of widespread hemispherism in the fact that the song opens by saying it isn’t snowy, as if being snowy were the default state and any deviation from it must be called out.
Now, I must get some good Christmas sleep.
Video: Christmastime is Wunnerful (Robot Protectors cover)
Posted by Angela Brett in Holidailies on December 14, 2014
I felt a bit bad about having to truncate the full-length instrumental that Colleen and Joseph made for JoCo Day is Wunnerful, so, having already taught my robot choir the main melody, I decided to record my own cover of Christmastime is Wunnerful. I was toying with the idea of making it a mashup with Jonathan Coulton’s other Christmas classic, Chiron Beta Prime (since the source tracks for that are available), when I realised that even without modification, Christmastime is Wunnerful is quite amusing to listen to while watching Tom Ellsworth‘s music video for Chiron Beta Prime. So I decided to edit that video (with Tom’s permission) to match my cover. Here is the result:
For comparison, here’s the original Chiron Beta Prime video. I didn’t have to change very much, really:
I had to pretty much abandon the ‘daily’ part of Holidailies because ended up flyng to New Zealand, which in itself takes more than a day without internet. But here’s some more holiday for you.
The voices I used were, in order of appearance:
Adult human male: Alex
Standard robots: Zarvox
Festive holiday figure robots for the purposes of augmenting human morale and productivity: Trinoids
Adult human female: Victoria
Human male emulation for the purposes of undetectable redaction: Ralph
Juvenile human: Junior
I also used the bells and ‘Message redacted’ tracks from Chiron Beta Prime, and the ‘Machines’ track from The Future Soon.

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported License.
Please tell me if you do something cool with it.

