Posts Tagged audio word clouds
Top 35 Adjectives Twitter user @realdonaldtrump uses before nouns
Posted by Angela Brett in News on December 3, 2020
Edit: As of 8 January, 2021, @realdonaldtrump is no longer a Twitter user, but he was at the time of this post.
Version 2.0.1 of my iOS app NastyWriter has 184 different insults (plus two extra special secret non-insults that appear rarely for people who’ve paid to remove ads 🤫) which it can automatically add before nouns in the text you enter. “But Angela,” I hear you not asking, “you’re so incredibly nice! How could you possibly come up with 184 distinct insults?” and I have to admit, while I’ve been known to rap on occasion, I have not in fact been studying the Art of the Diss — I have a secret source. (This is a bonus joke for people with non-rhotic accents.)
My secret source is the Trump Twitter Archive. Since NastyWriter is all about adding gratuitous insults immediately before nouns, which Twitter user @realdonaldtrump is such a dab hand at, I got almost all of the insults from there. But I couldn’t stand to read it all myself, so I wrote a Mac app to go through all of the tweets and find every word that seemed to be an adjective immediately before a noun. I used NSLinguisticTagger, because the new Natural Language framework did not exist when I first wrote it.
Natural language processing is not 100% accurate, because language is complicated — indeed, the app thought ‘RT’, ‘bit.ly’, and a lot of twitter @usernames (most commonly @ApprenticeNBC) and hashtags were adjectives, and the usernames and hashtags were indeed used as adjectives (usually noun adjuncts) e.g. in ‘@USDOT funding’. One surprising supposed adjective was ‘gsfsgh2kpc’, which was in a shortened URL mentioned 16 times, to a site which Amazon CloudFront blocks access to from my country.
For each purported adjective the app found, I had a look at how it was used before adding it to NastyWriter’s insult collection. Was it really an adjective used before a noun? Was it used as an insult? Was it gratuitous? Were there any other words it was commonly paired with, making a more complex insult such as ‘totally conflicted and discredited’, or ‘frumpy and very dumb’? Was it often in allcaps or otherwise capitalised in a specific way?
But let’s say we don’t care too much about that and just want to know roughly which adjectives he used the most. Can you guess which is the most common adjective found before a noun? I’ll give you a hint: he uses it a lot in other parts of sentences too. Here are the top 35 as of 6 November 2020:
- ‘great’ appears 4402 times
- ‘big’ appears 1351 times
- ‘good’ appears 1105 times
- ‘new’ appears 1034 times
- ‘many’ appears 980 times
- ‘last’ appears 809 times
- ‘best’ appears 724 times
- ‘other’ appears 719 times
- ‘fake’ appears 686 times
- ‘American’ appears 592 times
- ‘real’ appears 510 times
- ‘total’ appears 509 times
- ‘bad’ appears 466 times
- ‘first’ appears 438 times
- ‘next’ appears 407 times
- ‘wonderful’ appears 375 times
- ‘amazing’ appears 354 times
- ‘only’ appears 325 times
- ‘political’ appears 310 times
- ‘beautiful’ appears 298 times
- ‘fantastic’ appears 279 times
- ‘tremendous’ appears 270 times
- ‘massive’ appears 268 times
- ‘illegal’ appears 254 times
- ‘incredible’ appears 254 times
- ‘nice’ appears 251 times
- ‘strong’ appears 250 times
- ‘greatest’ appears 248 times
- ‘true’ appears 247 times
- ‘major’ appears 243 times
- ‘same’ appears 236 times
- ‘terrible’ appears 231 times
- ‘presidential’ appears 221 times
- ‘much’ appears 217 times
- ‘long’ appears 215 times
So as you can see, he doesn’t only insult. The first negative word, ‘fake’, is only the ninth most common, though more common than its antonyms ‘real’ and ‘true’, if they’re taken separately (‘false’ is in 72nd position, with 102 uses before nouns, while ‘genuine’ has only four uses.) And ‘illegal’ only slightly outdoes ‘nice’.
He also talks about American things a lot, which is not surprising given his location. ‘Russian’ comes in 111st place, with 62 uses, so about a tenth as many as ‘American’. As far as country adjectives go, ‘Iranian’ is next with 40 uses before nouns, then ‘Mexican’ with 39, and ‘Chinese’ with 37. ‘Islamic’ has 33. ‘Jewish’ and ‘White’ each have 27 uses as adjectives before nouns, though the latter is almost always describing a house rather than people. The next unequivocally racial (i.e. referring to a group of people rather than a specific region) adjective is ‘Hispanic’, with 25. I’m not an expert on what’s unequivocally racial, but I can tell you that ‘racial’ itself has nine adjectival uses before nouns, and ‘racist’ has three.
“But Angela,” I hear you not asking, “why are you showing us a list of words and numbers? Didn’t you just make an audiovisual word cloud generator a few months ago?” and the answer is, yes, indeed, I did make a word cloud generator that makes visual and audio word clouds, So here is an audiovisual word cloud of all the adjectives found at least twice before nouns in tweets by @realdonaldtrump in The Trump Twitter Archive, with Twitter usernames filtered out even if they are used as adjectives. More common words are larger and louder. Words are panned left or right so they can be more easily distinguished, so this is best heard in stereo.
There are some nouns in there, but they are only counted when used as attributive nouns to modify other nouns, e.g. ‘NATO countries’, or ‘ObamaCare website’.
Audio Word Clouds
Posted by Angela Brett in News on August 1, 2020
For my comprehensive channel trailer, I created a word cloud of the words used in titles and descriptions of the videos uploaded each month. Word clouds have been around for a while now, so that’s nothing unusual. For the soundtrack, I wanted to make audio versions of these word clouds using text-to-speech, with the most common words being spoken louder. This way people with either hearing or vision impairments would have a somewhat similar experience of the trailer, and people with no such impairments would have the same surplus of information blasted at them in two ways.
I checked to see if anyone had made audio word clouds before, and found Audio Cloud: Creation and Rendering, which makes me wonder if I should write an academic paper about my audio word clouds. That paper describes an audio word cloud created from audio recordings using speech-to-text, while I wanted to create one from text using text-to-speech. I was mainly interested in any insights into the number of words we could perceive at once at various volumes or voices. In the end, I just tried a few things and used my own perception and that of a few friends to decide what worked. Did it work? You tell me.

Voices
There’s a huge variety of English voices available on macOS, with accents from Australia, India, Ireland, Scotland, South Africa, the United Kingdom, and the United States, and I’ve installed most of them. I excluded the voices whose speaking speed can’t be changed, such as Good News, and a few novelty voices, such as Bubbles, which aren’t comprehensible enough when there’s a lot of noise from other voices. I ended up with 30 usable voices. I increased the volume of a few which were harder to understand when quiet.
I wondered whether it might work best with only one or a few voices or accents in each cloud, analogous to the single font in each visual word cloud. That way people would have a little time to adapt to understand those specific voices rather than struggling with an unfamiliar voice or accent with each word. On the other hand, maybe it would be better to have as many voices as possible in each word cloud so that people could distinguish between words spoken simultaneously by voice, just as we do in real life. In the end I chose the voice for each word randomly, and never got around to trying the fewer-distinct-voices version. Being already familiar with many of these voices, I’m not sure I would have been a good judge of whether that made it easier to get used to them.
Arranging the words
It turns out making an audio word cloud is simpler than making a visual one. There’s only one dimension in an audio word cloud — time. Volume could be thought of as sort of a second dimension, as my code would search through the time span for a free rectangle of the right duration with enough free volume. I later wrote an AppleScript to create ‘visual audio word clouds’ in OmniGraffle showing how the words fit into a time/volume rectangle. I’ve thus illustrated this post with a visual word cloud of this post, and a few audio word clouds and visual audio word clouds of this post with various settings.
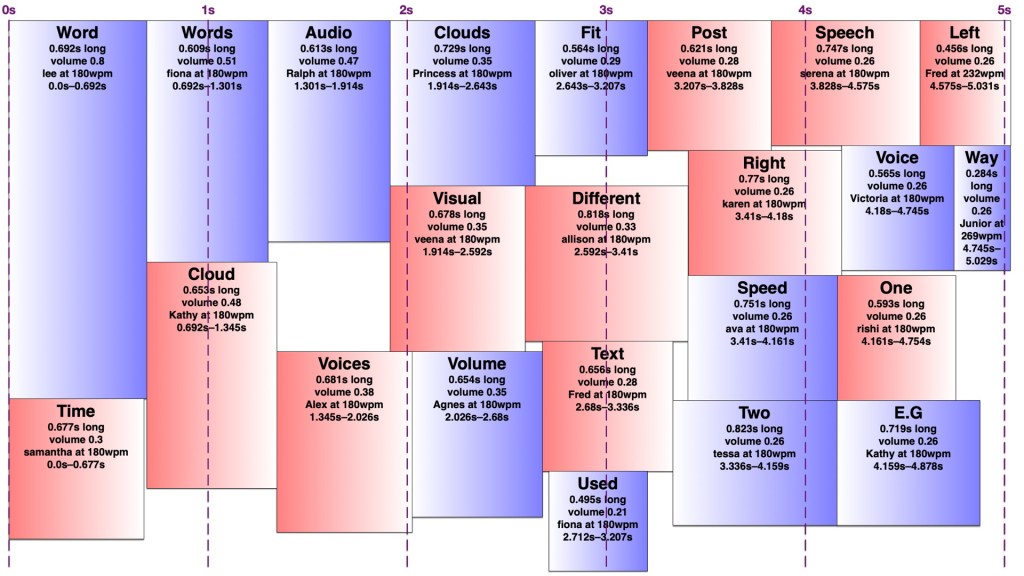
However, words in an audio word cloud can’t be oriented vertically as they can in a visual word cloud, nor can there really be ‘vertical’ space between two words, so it was only necessary to search along one dimension for a suitable space. I limited the word clouds to five seconds, and discarded any words that wouldn’t fit in that time, since it’s a lot easier to display 301032 words somewhat understandably in nine minutes than it is to speak them. I used the most common (and therefore louder) words first, sorted by length, and stopped filling the audio word cloud once I reached a word that would no longer fit. It would sometimes still be possible to fit a shorter, less common word in that cloud, but I didn’t want to include words much less common than the words I had to exclude.
I set a preferred volume for each word based on its frequency (with a given minimum and maximum volume so I wouldn’t end up with a hundred extremely quiet words spoken at once) and decided on a maximum total volume allowed at any given point. I didn’t particularly take into account the logarithmic nature of sound perception. I then found a time in the word cloud where the word would fit at its preferred volume when spoken by the randomly-chosen voice. If it didn’t fit, I would see if there was room to put it at a lower volume. If not, I’d look for places it could fit by increasing the speaking speed (up to a given maximum) and if there was still nowhere, I’d increase the speaking speed and decrease the volume at once. I’d prioritise reducing the volume over increasing the speed, to keep it understandable to people not used to VoiceOver-level speaking speeds. Because of the one-and-a-bit dimensionality of the audio word cloud, it was easy to determine how much to decrease the volume and/or increase the speed to fill any gap exactly. However, I was still left with gaps too short to fit any word at an understandable speed, and slivers of remaining volume smaller than my per-word minimum.
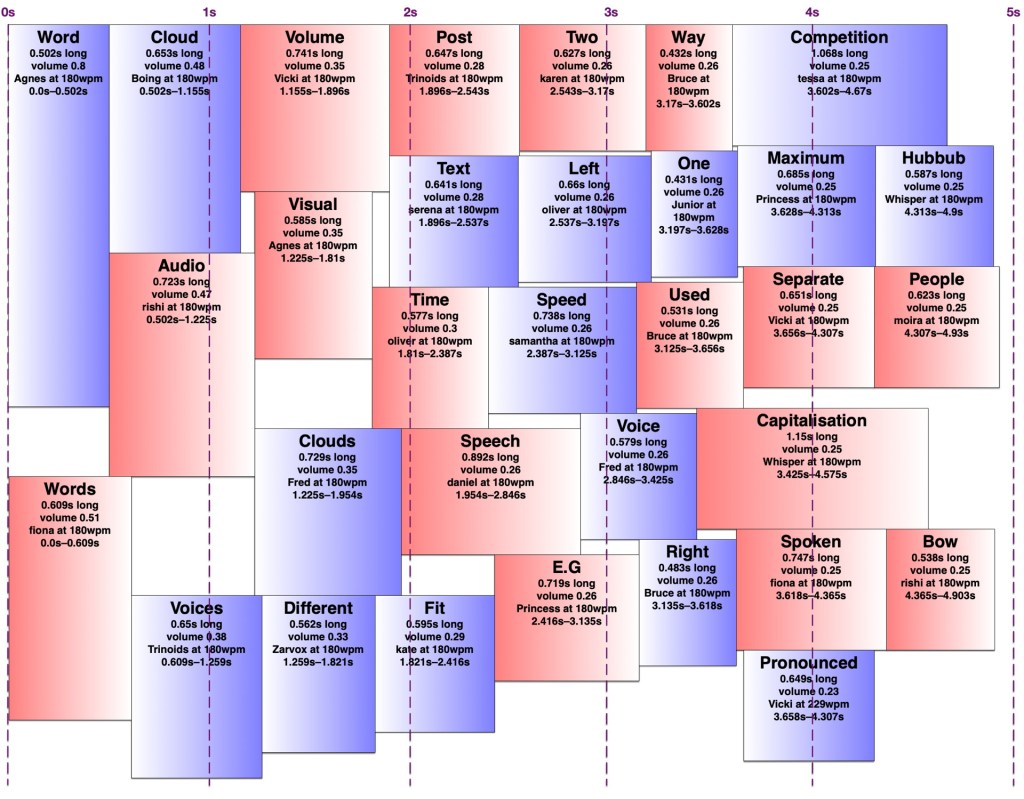
I experimented with different minimum and maximum word volumes, and maximum total volumes, which all affected how many voices might speak at once (the ‘hubbub level’, as I call it). Quite late in the game, I realised I could have some voices in the right ear and some in the left, which makes it easier to distinguish them. In theory, each word could be coming from a random location around the listener, but I kept to left and right — in fact, I generated separate left and right tracks and adjusted the panning in Final Cut Pro. Rather than changing the logic to have two separate channels to search for audio space in, I simply made my app alternate between left and right when creating the final tracks. By doing this, I could increase the total hubbub level while keeping many of the words understandable. However, the longer it went on for, the more taxing it was to listen to, so I decided to keep the hubbub level fairly low.
The algorithm is deterministic, but since voices are chosen randomly, and different voices take different amounts of time to speak the same words even at the same number of words per minute, the audio word clouds created from the same text can differ considerably. Once I’d decided on the hubbub level, I got my app to create a random one for each month, then regenerated any where I thought certain words were too difficult to understand.
Capitalisation

In my visual word clouds, I kept the algorithm case-sensitive, so that a word with the same spelling but different capitalisation would be counted as a separate word, and displayed twice. There are arguments for keeping it like this, and arguments to collapse capitalisations into the same word — but which capitalisation of it? My main reason for keeping the case-sensitivity was so that the word cloud of Joey singing the entries to our MathsJam Competition Competition competition would have the word ‘competition’ in it twice.
Sometimes these really are separate words with different meanings (e.g. US and us, apple and Apple, polish and Polish, together and ToGetHer) and sometimes they’re not. Sometimes these two words with different meanings are pronounced the same way, other times they’re not. But at least in a visual word cloud, the viewer always has a way of understanding why the same word appears twice. For the audio word cloud, I decided to treat different capitalisations as the same word, but as I’ve mentioned, capitalisation does matter in the pronunciation, so I needed to be careful about which capitalisation of each word to send to the text-to-speech engine. Most voices pronounce ‘JoCo’ (short for Jonathan Coulton, pronounced with the same vowels as ‘go-go’) correctly, but would pronounce ‘joco’ or ‘Joco’ as ‘jocko’, with a different vowel in the first syllable. I ended up counting any words with non-initial capitals (e.g. JoCo, US) as separate words, but treating title-case words (with only the initial letter capitalised) as the same as all-lowercase, and pronouncing them in title-case so I wouldn’t risk mispronouncing names.
Further work
A really smart version of this would get the pronunciation of each word in context (the same way my rhyming dictionary rhyme.science finds rhymes for the different pronunciations of homographs, e.g. bow), group them by how they were pronounced, and make a word cloud of words grouped entirely by pronunciation rather than spelling, so ‘polish’ and ‘Polish’ would appear separately but there would be no danger of, say ‘rain’ and ‘reign’ both appearing in the audio word cloud and sounding like duplicates. However, which words are actually pronounced the same depend on the accent (e.g. whether ‘cot’ and ‘caught’ sound the same) and text normalisation of the voice — you might have noticed that some of the audio word clouds in the trailer have ‘aye-aye’ while others have ‘two’ for the Roman numeral ‘II’.
Similarly, a really smart visual word cloud would use natural language processing to separate out different meanings of homographs (e.g. bow🎀, bow🏹, bow🚢, and bow🙇🏻♀️) and display them in some way that made it obvious which was which, e.g. by using different symbols, fonts, styles, colours for different parts of speech. It could also recognise names and keep multi-word names together, count words with the same lemma as the same, and cluster words by semantic similarity, thus putting ‘Zoe Keating’ near ‘cello’, and ‘Zoe Gray’ near ‘Brian Gray’ and far away from ‘Blue’. Perhaps I’ll work on that next.

I’ve recently been updated to a new WordPress editor whose ‘preview’ function gives a ‘page not found’ error, so I’m just going to publish this and hope it looks okay. If you’re here early enough to see that it doesn’t, thanks for being so enthusiastic!
How to fit 301032 words into nine minutes
Posted by Angela Brett in News on July 14, 2020
A few months ago I wrote an app to download my YouTube metadata, and I blogged some statistics about it and some haiku I found in my video titles and descriptions. I also created a few word clouds from the titles and descriptions. In that post, I said:
Next perhaps I’ll make word clouds of my YouTube descriptions from various time periods, to show what I was uploading at the time. […] Eventually, some of the content I create from my YouTube metadata will make it into a YouTube video of its own — perhaps finally a real channel trailer.
Me, two and a third months ago
TL;DR: I made a channel trailer of audiovisual word clouds showing each month of uploads:
It seemed like the only way to do justice to the number and variety of videos I’ve uploaded over the past thirteen years. My channel doesn’t exactly have a content strategy. This is best watched on a large screen with stereo sound, but there is no way you will catch everything anyway. Prepare to be overwhelmed.
Now for the ‘too long; don’t feel obliged to read’ part on how I did it. I’ve uploaded videos in 107 distinct months, so creating a word cloud for each month using wordclouds.com seemed tedious and slow. I looked into web APIs for creating word clouds automatically, and added the code to my app to call them, but then I realised I’d have to sign up for an account, including a payment method, and once I ran out of free word clouds I’d be paying a couple of cents each. That could easily add up to $5 or more if I wanted to try different settings! So obviously I would need to spend many hours programming to avoid that expense.
I have a well-deserved reputation for being something of a gadget freak, and am rarely happier than when spending an entire day programming my computer to perform automatically a task that it would otherwise take me a good ten seconds to do by hand. Ten seconds, I tell myself, is ten seconds. Time is valuable and ten seconds’ worth of it is well worth the investment of a day’s happy activity working out a way of saving it.
Douglas Adams in ‘Last chance to see…’
I searched for free word cloud code in Swift, downloaded the first one I found, and then it was a simple matter of changing it to work on macOS instead of iOS, fixing some alignment issues, getting it to create an image instead of arranging text labels, adding some code to count word frequencies and exclude common English words, giving it colour schemes, background images, and the ability to show smaller words inside characters of other words, getting it to work in 1116 different fonts, export a copy of the cloud to disk at various points during the progress, and also create a straightforward text rendering using the same colour scheme as a word cloud for the intro… before I knew it, I had an app that would automatically create a word cloud from the titles and descriptions of each month’s public uploads, shown over the thumbnail of the most-viewed video from that month, in colour schemes chosen randomly from the ones I’d created in the app, and a different font for each month. I’m not going to submit a pull request; the code is essentially unrecognisable now.
In case any of the thumbnails spark your curiosity, or you just think the trailer was too short and you’d rather watch 107 full videos to get an idea of my channel, here is a playlist of all the videos whose thumbnails are shown in this video:
It’s a mixture of super-popular videos and videos which didn’t have much competition in a given month.
Of course, I needed a soundtrack for my trailer. Music wouldn’t do, because that would reduce my channel trailer to a mere song for anyone who couldn’t see it well. So I wrote some code to make an audio version of each word cloud (or however much of it could fit into five seconds without too many overlapping voices) using the many text-to-speech voices in macOS, with the most common words being spoken louder. I’ll write a separate post about that; I started writing it up here and it got too long.
The handwritten thank you notes at the end were mostly from members of the JoCo Cruise postcard trading club, although one came with a pandemic care package from my current employer. I have regaled people there with various ridiculous stories about my life, and shown them my channel. You’re all most welcome; it’s been fun rewatching the concert videos myself while preparing to upload, and it’s always great to know other people enjoy them too.
I put all the images and sounds together into a video using Final Cut Pro 10.4.8. This was all done on my mid-2014 Retina 15-inch MacBook Pro, Sneuf.

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported License.
Please tell me if you do something cool with it.

