Archive for 2021
Etymological family trees
Posted by Angela Brett in News on December 30, 2021
A while ago I found a post about Surprising shared word etymologies, where the author had found words with common origins (according to Etymological Wordnet) which had the most dissimilar meanings (according to GloVe: Global Vectors for Word Representation.) I loved the post, but my main takeaway from it was the The History of English Podcast, linked in the Further reading section. I immediately started listening to that, in reverse order (that’s just the easiest thing to do in the Apple Podcasts app. Back when podcasts were in iTunes, I used to listen to all my podcasts on shuffle, so if you like order, this is an improvement) starting from Episode 148. I’ve since finished it and started listening to something else before I go back for the newer episodes. I was in it for the English, but I also learnt lot more history than I expected to.
The diagrams
Back in October, hearing about how yet another absurd list of words all derived from the same root word (I think in this case it was bloom, flower, phallus, bollocks, belly, flatulence, bloat, fluid, bladder, blow, and blood from episode 62) I decided I couldn’t just listen to these ridiculous linguistic family trees any more; I had to see them. As you might have seen in previous posts, my go-to for creating that kind of diagram is using AppleScript to control OmniGraffle. So I wrote an AppleScript to make tree diagrams showing words that are all derived from the same root word(s) as a given word. Before I bore you with the details, I’ll show you a little example. This is what it gave when I asked for the English word ‘little’.

The root word is in a blue oval, the words in the same language as the one I asked about (in this case, English) are in brown rounded rectangles, and the words in other languages are in black rectangles. I thought about having a different colour and shape for each language, and a legend, but decided to keep things simple for now.
Image descriptions
The script also generates a simple image description, which I’ve used in the caption. I intended it for use as alt text, but some of these diagrams are difficult to read at the size shown, so even people who don’t use screen readers can benefit from the description. You can also click on any diagram for a full-sized pdf version.
It doesn’t describe the entire structure of the tree (I’m trying not to get distracted researching nice ways to do that for arbitrary trees!) but it’s probably better than nothing. It only lists the words in the language you asked about (assuming that is English), since English screen readers likely wouldn’t read the other ones correctly anyway. It might be cool to autogenerate sound files using text-to-speech in voices made for the other languages and attach those to the nodes to enrich the experience when navigating through them in OmniGraffle or some other format it can export, but that’s a project for another day.
On the subject of accessibility, I’m happy that the History of English Podcast provides transcripts, so I can easily find the episodes relevant to some of these diagrams.
Simplifying the diagrams
Sometimes the diagrams get crowded when a lot of words are derived from another word in the same language, or a lot of other languages derived words from the same word. I wrote a second script to group words into a single node if they’re all derived from the same word, don’t have any words derived from them, and are all in the same kind of shape as the word they’re derived from. That last constraint means that if you searched for an English word, English words all derived from the same English word will be grouped together, and non-English words all derived from the same non-English word will be grouped together, but English words derived from a non-English word (or vice versa) are not, because I think they are more interesting and less obvious.
It’s actually quite satisfying to watch this script at work, as it deletes extra nodes and puts the text into a single node, so I made a screen recording of it doing this to the diagram of the English word ‘pianoforte’. I’m almost tempted to add pleasant whooshing sound effects as it sweeps through removing nodes.
The data
Words and their etymologies
The data from Etymological Wordnet comes as a tab-separated-values file. AppleScript is best at telling other applications what to do, not doing complicated things itself, so I left all the tsv parsing up to Numbers, and had my script communicate with Numbers to get the data. The full data has too many rows for Numbers to handle, but I only needed the rows with the type rel:etymology, so I created a file with just those rows using this command:
grep 'rel:etymology' etymwn.tsv > etymology.tsv
then opened the resulting etymology.tsv file in Numbers, and saved it as a numbers file. This means missing out of a few etymological links (some of which are mentioned below), but it’s good enough for most words.
The file simply relates words to the words in the first column to words they are derived from in the third column.
Languages
Each word is listed with a language abbreviation, a colon, then the word. The readme that comes with the Etymological Wordnet data says, ‘Words are given with ISO 639-3 codes (additionally, there are some ISO 639-2 codes prefixed with “p_” to indicate proto-languages).’ However, I found that not all of the protolanguage codes used were in ISO 639-2, so I ended up using ISO 639-5 data for protolanguages and ISO 639-3 data for the other languages, both converted to Numbers files and accessed the same way as the etymology data.
The algorithm
The script starts by finding the ultimate root word(s) of whatever word you entered. It finds the word each word is immediately derived from, then finds the word that was derived from, and so on, until it gets to a word that doesn’t have any further origin. Some words have multiple origins, either because they’re compound words, homographs, or just were influenced by multiple words, so sometimes the script ends up with several ultimate root words. This part of the script ignores origins that have hyphens in them, because they’re likely common prefixes or suffixes, and if you’re looking up ‘coagulate’, you’re unlikely to want every single word derived from a Latin word with a prefix ‘co-‘.
For each of the root words, the script finds all words derived from it, and all words derived from those, and so on, and adds them to the diagram.
The code
In case you want to try making your own trees, I’ve put the AppleScripts and the Numbers sheets used for this in a git repository. It turns out having the version history is not terribly useful without tools to diff AppleScript, which is not plain text. It is possible to save AppleScript as plain text, but I didn’t do that in the beginning, so the existing version history is not so useful. It looks like AS Source Diff could help.
There are a lot of frustrating things about AppleScript when you’re used to using more modern programming languages. Sometimes that’s part of the fun, and sometimes it’s part of the not-fun.
Trees from Surprising Shared Etymologies
I tried making diagrams of some of the interesting related words mentioned in The History of English Podcast, such as the one with flower, bollocks, phallus and blood mentioned earlier, but the data usually didn’t go back that far. So I tried the ones mentioned in the Surprising shared etymologies post, because I knew they were found in the same data. In several cases I found the links didn’t actually hold up, as the words were descended from unrelated homonyms. I’ve done my best to figure out which parts of these trees are correct, but can’t guarantee I got everything right, so take this information with a grain of research.
“piano” & “plainclothed”
This was a bit of a puzzle, because there is actually no origin given in the data for English word ‘piano’, although it is given as the origin of many words in other languages. But their example in the ‘datasets’ section shows English: pianoforte, so I used that instead.
I could have added a row to the spreadsheet linking English ‘pianoforte’ with English ‘piano’, and then the many words in other languages that derive from English ‘piano’ would have shown in the diagram as well. Click on the diagram for a pdf version.

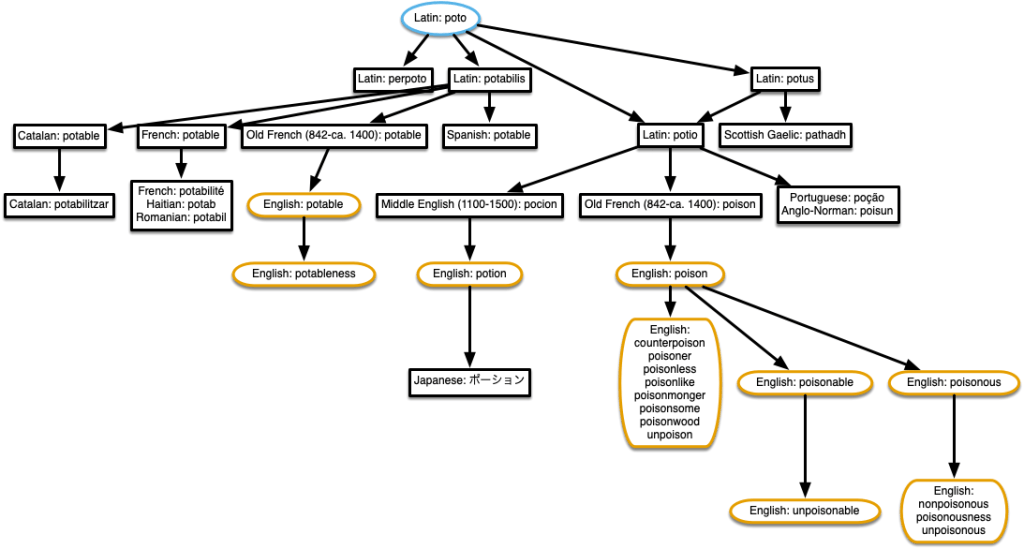
“potable” & “poison”
Also potion! According to the data, Latin potio is derived both from Latin poto, and from Latin potus, which is itself derived from Latin poto. The word is its own niece! I had to make a change to the script to ensure there wouldn’t be double connections in this case.
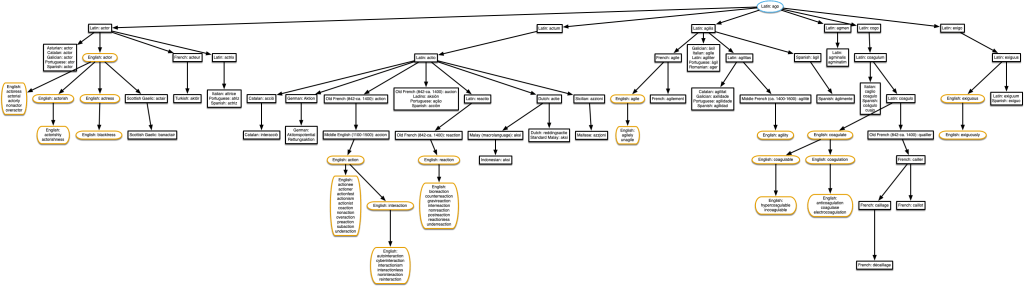
“actor” & “coagulate”
Agile and exiguous, too! It’s starting to get a bit complicated.
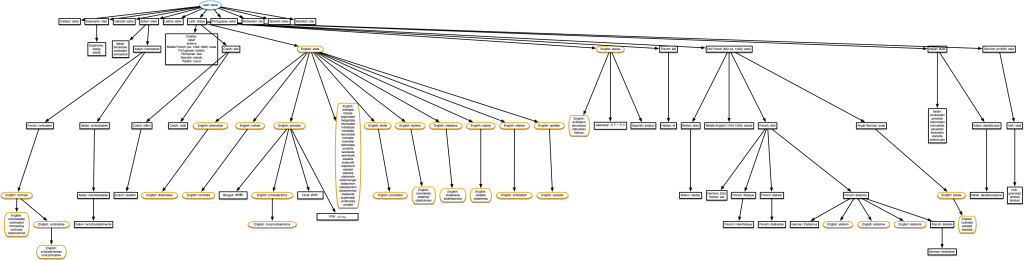
“estate” & “contrast”
This tree also includes ‘prostate’, but only ‘pro-state’ (meaning favouring the government) derives from English ‘state’ as shown here. Prostate the body part is actually related, but only if we go back to the Proto-Indo-European root *sta-, which is not in the Etymological Wordnet data. Since the data doesn’t distinguish between the two meanings of ‘prostate’, this tree erroneously includes prostatectomy and cryoprostatectomy, a procedure I was happier not knowing about.
If you think it’s surprising that ‘estate’ and ‘contrast’ are related, have a look at other words derived from *sta-. Understand, obstetrics, Taurus, Kazakhstan… if Etymological Wordnet had that data, this tree would resemble Pando.
“pay” & “peace”
This one comes up in episode 59 of the podcast — the word ‘pay’ literally meant ‘make peace’. It’s not too hard to imagine how paying someone would pacify them. The diagram is incorrect though. ‘Peace’ is shown as being derived from Middle English pece. This is actually the source of ‘piece’, but not ‘peace’. As far as I can tell, pece (and therefore also ‘piece’) shouldn’t even be in this tree. The word ‘peace’ is derived from Middle English pees, near the middle of the diagram, so it is still related to ‘pay’.

“cancer” & “cancel” & “chancellor”
As explained in episode 99 of The History of English Podcast, chancellor is just the Parisian French version of the Norman French canceler. The word ‘cancel’ didn’t come from ‘canceler’, though — ‘cancel’ and ‘chancellor’ both come from a word meaning lattice, whether the lattice a chancellor stands behind, or that of crossing something out to cancel it. The same word also give rise to ‘incarcerate’, but that link is not in the data.
As far as I can tell, these are not actually related to the English word ‘cancer’, though. There are two unrelated Latin words ‘cancer’, one meaning ‘lattice’, and the other meaning ‘crab’, and thus crab-like cancer tumours.

“fantastic” & “phenotype”
This also shows that ‘craptastic’ is related to ‘phasor’. Sometimes the best things about these are the lists of derivative slang words.

“college” & “legalize”
Also ‘cull’, ‘legend’, and ‘colleague’.
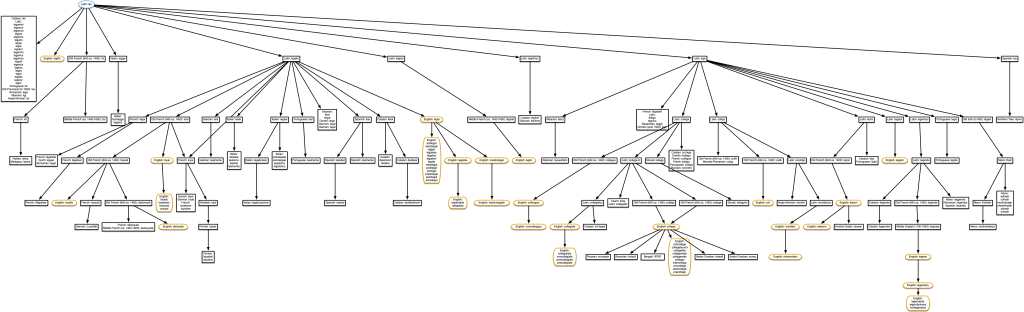
“lien” & “ligament”
‘Cull’ should not be in this diagram, as it’s related to a different homonym of Latin colligo. See the ‘Limitations‘ section below.

“journal” & “journey”
Surprising shared word etymologies says:
While it seems like “journal” and “journey” should be close cousins, their nearest common ancestor is in fact quite old – the Latin “diurnus”, meaning “daily”.
This seems about right from the data, and I’m surprised they didn’t both come from the Old French jor. My dictionary of French etymology doesn’t list the French versions of either word.

This is the tree I get if I start from the word ‘journal’. If I start with ‘journey’, it shows that Latin diurnum is also given as an origin of Old French jor, but this adds a lot of complication to the tree and only one extra English word, ‘abatjour’.
“educate” & “subdue”
I’m not sure how they got these two, to be honest. They may indeed be related, if, as etymonline says, subdue came from the same root as subduce, and subduce and educate came from Proto-Indo-European *deuk- (or *dewk-, as wiktionary spells it). There’s a lot about other words from that root (not including ‘subdue’) in episode 85 of the podcast.
I don’t know how they got this from the Etymological Wordnet data, though. Etymological Wordnet was extracted from an older version of wiktionary, and it doesn’t have very many Proto-Indo-European roots. The post says that ‘subdue’ comes from the latin subduco, meaning ‘lead under’. But even looking at all the data (not just the rows with ‘rel:etymology‘), ‘subdue’ is only linked to other English words. Perhaps they were looking at ‘subduce’ instead.
The post also says they both come from Latin duco. If I look at all the data, I can get to Latin duco from ‘educate’ (via Latin educatio and educo.) But looking more closely at that link on wiktionary (the source of Etymological Wordnet’s data) it seems there are two meanings of Latin educo, one coming from Latin duco and one coming from Latin dux, and it’s the dux origin that seems more relevant to education. However Proto-Indo-European *deuk- is the hypothetical source of dux, so that’s how it relates to subdue.
I’m getting a bit lost following these words around wiktionary and etymonline. I believe they’re related, but I’m not sure if they’re related via Latin duco, and I haven’t a clue how the relationship was found in the Etymological Wordnet data (I should probably read and/or run their ruby code to find out), so I can’t generate even an erroneous family tree of it.
Limitations
Did you notice that the word ‘cull’ shows up in both the tree for ‘college’ and the one for ‘ligament’? Does that mean that ‘ligament’ is also related to ‘college’? Nope. The issue here is that the Latin colligo has two distinct meanings with different origins, one via Latin ligo, and one via Latin lego. ‘cull’ derives from the ‘bring together’ meaning of colligo, which derives from lego, so it’s actually not related to ‘ligament’. Only one origin for colligo is shown on each of these two trees, since neither ‘college’ nor ‘ligament’ are derived from colligo, so the script only got to colligo when coming down from one of the ultimate root words, rather than when going up from the search word. But if we create a tree starting with the word ‘cull’, it gets both origins and the resulting tree makes it look like ‘college’ and ‘ligament’ are related.
Since the data only has plain text for each word, there’s no way for the script to know for sure that colligo isn’t one word with multiple origins (like ‘fireside’ is), but actually two separate words with different origins. And there’s no way for it to know which origin for colligo happens to be the one that ultimately gave rise to ‘cull’.
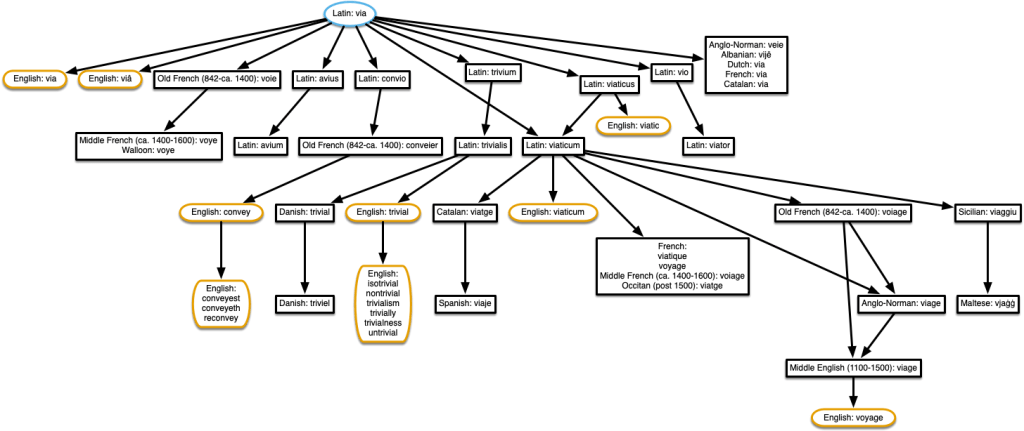
A trivial example
I’ll leave you with a tree I found while looking for a trivial example to show at the beginning. Here’s the tree for ‘trivial’. There are many more related words given in episode 37 of The History of English Podcast.
Disinflections
Posted by Angela Brett in News on May 12, 2021
I enjoy taking words that have irregular inflections, and inflecting other words the same way — for instance, saying *squoke as the past tense of squeak, analogous with speak and spoke, or even *squought, analogous with seek and sought. Sometimes those disinflections, as I’ve decided to call them, look or sound like other words… for instance, analogous with fly, flew, and flown, I could use crew and crown as past tenses of cry, or boo and bone as past tenses of buy. Indeed, analogous with buy and bought, the past tense of fly could be *flought, but then again, perhaps the present tense of bought could be ‘batch’ or ‘beak’, or ‘bite’, analogous with caught and catch, or sought and seek, or fought and fight.
The Disinflectant app
For a while now, I’ve wanted to make an app to find these automatically, and now that I have a bit of free time, I’ve made a prototype, mostly reusing code I wrote to generate the rhyme database for Rhyme Science. I’m calling the app Disinflectant for now. Here’s what it does:
- Read words from a file and group them by lemma.
Words with the same lemma are usually related, though since this part is using text only, if two distinct lemmas are homographs (words with the same spelling but different meanings) such as bow🎀, bow🏹, bow🚢, and bow🙇🏻♀️, then they’re indistinguishable. This part is done using the Natural Language framework (henceforth referred to as ‘the lemmatiser’), so I didn’t write any complicated rules to do this. - Find out the pronunciation of the word, as text representing phonemes.
This is done using the text-to-speech framework, so again, nothing specific to Disinflectant. The pronunciation is given in phoneme symbols defined by the API, not IPA. - Find all the different ways that words with the same lemma can be transformed into another by switching a prefix or suffix for another. For instance:
| Transform type | Transform | by analogy with |
|---|---|---|
| Spelling suffix | y→own | fly→flown |
| Pronunciation suffix | IYk→AOt | seek→sought |
| Spelling prefix | e→o | eldest→oldest |
| Pronunciation prefix | 1AW→w1IY | our→we’re |
Most prefixes in English result in words with different lemmas, so Disinflectant didn’t find many prefix transforms, and the ones it found didn’t really correspond to any actual grammatical inflection. I had it prefer suffixes over prefixes, and only add a prefix transform if there is no suffix found, so that bus→buses would result in the spelling suffix transform ∅→es and not the prefix transform bu→buse.
Each transform can apply to multiple pairs of real words. I included a way to label each transform with something like ‘past tense’, so the app could ask, ‘why isn’t crew the past tense of cry?’ but didn’t end up filling in any of them, so it just calls them all inflections.
- Apply each transform individually to each word, and see whether the transformed version matches another word with a different lemma.
It could just make up words such as ‘squoke’, but then there would be hundreds of millions of possibilities and they wouldn’t be very interesting to sift through, so it’s better to look for real words that match.
That’s it. Really just four steps of collecting and comparing data, with all the linguistic heavy lifting done by existing frameworks.
The limitations
Before I show you some of the results, here are some limitations:
- So far I’ve only given it a word list, and not a text corpus. This means that any words which have different lemmas or different pronunciations depending on context (such as ‘moped’ in ‘she moped around’, with the lemma ‘mope’, vs. ‘she rode around on her moped’, with the lemma ‘moped’.) I have code to work with corpora to add homographs to rhyme.science, but I haven’t tried it in this app yet.
- It’s only working with prefixes and suffixes. So it might think ‘woke’ should be the past tense of ‘weak’ (by analogy with ‘speak’ and ‘spoke’) but won’t generalise that to, say, ‘slope’ as the past tense of ‘sleep’ unless there is another word ending in a p sound to model it on. I could fairly easily have it look for infix transforms as well, but haven’t done so yet.
- It doesn’t distinguish between lemmas which are spelled the same, as mentioned above.
The results
For my first full test run, I gave it the SCOWL 40 list, with 60523 words, and (after about a day and a half of processing on my mid-2014 MacBook Pro — it’s not particularly optimised yet) it found 157687 disinflections. The transform that applied to the most pairs of actually-related words was adding a ‘z’ sound to the end of a word, as for a plural or possessive noun or second-person present-tense verb ending in a voiced sound. This applies to 7471 pairs of examples. The SCOWL list I used includes possessives of a lot of words, so that probably inflates the count for this particular transform. It might be interesting to limit it to transforms with many real examples, or perhaps even more interesting to limit it to transforms with only one example.
I just had it log what it found, and when a transform applied to multiple pairs of words, pick a random pair to show for the ‘by analogy with’ part in parentheses. Here are some types of disinflections it found, roughly in order from least interesting to most interesting:
Words that actually are related, just not so much that they have the same lemma:
Some words are clearly derived from each other and maybe should have the same lemma; others just have related meanings and etymology.
- Why isn’t shoppers (S1AApIXrz) with lemma shopper the inflection of shops (S1AAps) with lemma shop? (by analogy with lighter’s → light’s)
- Why isn’t constraint (kIXnstr1EYnt) with constraint same the inflection of constrain (kIXnstr1EYn) with lemma constrain? (by analogy with shopped → shop)
- Why isn’t diagnose (d1AYIXgn1OWs) with lemma diagnose the inflection of diagnosis (d1AYIXgn1OWsIXs) with lemma diagnosis? (by analogy with he → his)
- Why isn’t sieves (s1IHvz) with lemma sieve the inflection of sift (s1IHft) with lemma sift? (by analogy with knives → knifed)
- Why isn’t snort (sn1AOrt) with lemma snort the inflection of snored (sn1AOrd) with lemma snore? (by analogy with leapt → leaped)
Words that definitely should have had the same lemma, for the same reason the words in the analogy do:
These represent bugs in the lemmatiser.
- Why isn’t patrolwoman’s (pIXtr1OWlwUHmIXnz) with lemma patrolwoman’s the inflection of patrolwomen (pIXtr1OWlwIHmIXn) with lemma patrolwomen? (by analogy with patrolman’s → patrolmen)
- Why isn’t blacker (bl1AEkIXr) with lemma black the inflection of blacken (bl1AEkIXn) with lemma blacken? (by analogy with whiter → whiten)
Transforms formed from words which have the same lemma, but probably shouldn’t:
These also probably represent bugs in the lemmatiser.
- Why isn’t car (k1AAr) with lemma car the inflection of air (1EHr) with lemma air? (by analogy with can’t → ain’t)
Both ‘can’t’ and ‘ain’t’ are given the lemma ‘not’. I don’t think this is correct, but it’s possible I’m using the API incorrectly or I don’t understand lemmatisation.
Words that are related, but the lemmatiser was considering an unrelated homograph of one of the words, and the actual related word was not picked up because of the first limitation above:
- Why isn’t skier’s (sk1IYIXrz) with lemma skier the inflection of skied (sk1IYd) with lemma sky? (by analogy with downer’s → downed)
In this case, the text-to-speech read ‘skied’ as the past tense of ‘ski’, but the lemmatiser read it as the past participle of ‘sky’, as in, ‘blue-skied’, which I think is a slightly obscure choice, and might be considered a bug in the lemmatiser. - Why isn’t ground (gr1AWnd) with lemma ground the inflection of grinding (gr1AYndIHN) with lemma grind? (by analogy with rewound → rewinding)
Here the lemmatiser is presumedly reading it as the noun or verb ‘ground’ rather than the past and past participle of ‘grind’.
Pronunciation transforms finding homophones of actual related words:
- Why isn’t sheikhs (S1EYks) with lemma sheikh the inflection of shaking (S1EYkIHN) with lemma shake? (by analogy with outstrips → outstripping)
‘Sheikhs’ sounds just like ‘shakes’, which is indeed the present tense or plural of ‘shake’. - Why isn’t soled (s1OWld) with lemma sole the inflection of selling (s1EHlIHN) with lemma sell? (by analogy with sold → selling)
‘Soled’ sounds just like ‘sold’, which is indeed the past tense of ‘sell’.
Pronunciation transforms based on an incorrect pronunciation:
These represent bugs in the text-to-speech. Try them yourself on a Mac by setting the system voice to an older American English one such as Victoria, selecting the word, and choosing Speech→Start Speaking from the Edit menu or the contextual menu.
- Why isn’t nape’s (n1AEpIYz) with lemma nape the inflection of nappy (n1AEpIY) with lemma nappy? (by analogy with suffocation’s → suffocation)
The text-to-speech pronounces ‘nape’ correctly, but pronounces ‘napes’ like ‘naps’ and ‘nape’s’ like ‘nappies’. - Why isn’t mice (m1AYs) with lemma mouse the inflection of me (m1IY) with lemma I? (by analogy with modernity’s → modernity)
The text-to-speech pronounces ‘modernity’ correctly, but pronounces ‘modernity’s’ like ‘modernitice’.
- Why isn’t queue’s (ky1UWz) with lemma queue the inflection of cubing (ky1UWbIHN) with lemma cubing? (by analogy with lambs → lambing)
The text-to-speech pronounces the ‘b’ in ‘lambing’. I’m not sure if there is an accent where this is the correct pronunciation, but it isn’t in the dictionaries I’ve checked.
Small transforms that can be applied to many other words:
Sometimes it will find that a word with the same lemma can have one letter or phonemes changed or added, and then there are a huge number of words that the transform can apply to. I wonder if you could almost change any final letter or phoneme to any other.
- Why isn’t mine (m1AYn) with lemma I the inflection of mind (m1AYnd) with lemma mind? (by analogy with shoe → shod)
- Why isn’t ham (h1AEm) with lemma ham the inflection of hay (h1EY) with lemma hay? (by analogy with them → they)
This one could also be extended to hair (from them → their) to get a full set of weird pronouns. - Why isn’t hearth (h1AArT) with lemma hearth the inflection of heart (h1AArt) with lemma heart? (by analogy with sheikh → sheik)
- Why isn’t captor (k1AEptIXr) with lemma captor the inflection of captain (k1AEptIXn) with lemma same? (by analogy with whiter → whiten)
- Why isn’t colt (k1OWlt) with lemma colt the inflection of coal (k1OWl) with lemma coal? (by analogy with shopped → shop)
Spelling prefixes and suffixes that don’t quite correspond to how the inflections are formed:
Sometimes changes such as doubling the final consonant are made when an -ing or -ed is added. Since Disinflectant only sees this as a suffix being added, it thinks that specific consonant can also be added to words that end in other consonants.
- Why isn’t braking (br1EYkIHN) with lemma brake the inflection of bra (br1AA) with lemma bra? (by analogy with picnicking → picnic)
- Why isn’t garbs (g1AArbz) with lemma garbs the inflection of garbling (g1AArblIHN) with lemma garble? (by analogy with corrals → corralling)
- Why isn’t badgering (b1AEJIXrIHN) with lemma badger the inflection of badge (b1AEJ) with lemma badge? (by analogy with transferring → transfer)
- Why isn’t bobsled (b1AAbslEHd) with lemma bobsled the inflection of bobs (b1AAbz) with lemma bob? (by analogy with patrolled → patrol)
Disinflection I might have come up with myself:
- Why isn’t hay (h1EY) with lemma hay the inflection of highs (h1AYz) with lemma high? (by analogy with lay → lies)
- Why isn’t bowled (b1OWld) with lemma bowl the inflection of belling (b1EHlIHN) with lemma bell? (by analogy with sold → selling)
- Why isn’t bodies (b1AAdIYz) with lemma body the inflection of bodice (b1AAdIXs) with lemma bodice? (by analogy with emphases → emphasis)
- Why isn’t lease (l1IYs) with lemma lease the inflection of loosed (l1UWst) with lemma loose? (by analogy with geese → goosed)
- Why isn’t wield (w1IYld) with lemma wield the inflection of welt (w1EHlt) with lemma welt? (by analogy with kneeled → knelt)
- Why isn’t gauze (g1AOz) with lemma gauze the inflection of goo (g1UW) with lemma goo? (by analogy with draws → drew)
- Why isn’t cheese (C1IYz) with lemma cheese the inflection of chosen (C1OWzIXn) with lemma choose? (by analogy with freeze → frozen)
Transforms based on abbreviations:
- Why isn’t chuckle (C1UXkIXl) with lemma chuckle the inflection of chuck’s (C1UXks) with lemma chuck? (by analogy with mile → mi’s)
- Why isn’t cooperative’s (kOW1AApIXrrIXtIHvz) with lemma cooperative the inflection of cooper (k1UWpIXr) with lemma cooper? (by analogy with negative’s → neg)
- Why isn’t someday (s1UXmdEY) with lemma someday the inflection of some (s1UXm) with lemma some? (by analogy with Friday → Fri)
Other really weird stuff I’d never think of:
- Why isn’t comedy (k1AAmIXdIY) with lemma comedy the inflection of comedown (k1UXmdAWn) with lemma comedown? (by analogy with fly → flown)
- Why isn’t aisle (1AYl) with lemma aisle the inflection of meal (m1IYl) with lemma meal? (by analogy with I → me)
- Why isn’t hand (h1AEnd) with lemma hand the inflection of hens (h1EHnz) with lemma hen? (by analogy with manned → men’s)
- Why isn’t out (1AWt) with lemma same the inflection of wheat (w1IYt) with lemma same? (by analogy with our → we’re)
If people are interested, once I’ve fixed it up a bit I could either release the app, or import a bigger word list and some corpora, and then publish the whole output as a CSV file. Meanwhile, I’ll probably just tweet or blog about the disinflections I find interesting.
Every iOS developer take-home coding challenge
Posted by Angela Brett in News on May 7, 2021
I can load and parse your JSON.
I can download icons async.
I can show it in a TableView
just to show you that I’m able to.
I’ll go old school if you like it;
I can code it in UIKit.
I can code Objective-C,
if that’s what you expect of me.
You can catch { me } if you try;
I can code it SwiftUI.
I can code it with Combine:
receive(on: .main) and then assign.
I can read it with a Codable,
Local resource or downloadable.
I can code a search bar filter
or reload; I have the skill to!
I can code it every way
to go from model into view
But I have loads to do today
Can we just code things in an interview?
∎
I’ve been looking for a new job lately, and I’ve found that about 80% of the take-home coding challenges I’ve been given amount to ‘Write an iOS app that reads the JSON from this URL or file, and displays it in a list, including the icons from the URLs in the JSON. There should be [some additional controls on the list and/or a detail screen shown when a list item is selected]. You may use [specific language and/or UI framework] but not [some other technology, and/or any external libraries].’
It’s time-consuming, and gets a bit boring after a while, especially when the requirements are just different enough that you can’t reuse much code from the previous challenges, but not different enough that you can learn something new. One company even had me do the whole thing twice, because they’d neglected to mention which UI technology they preferred the first time. Luckily, by then I had existing code for almost every combination, so I didn’t have to waste too much time on it.
This poem is meant to have a ‘Green Eggs and Ham‘ vibe, though I couldn’t come up with a good ‘Sam-I-Am’ part. The best I can do is:
I do not like this soul destroyer;
I do not like it, Sawyer-the-Employer!
or:
I do not like this coding prob’,
I do not like it, Bob-the-Job!
I did have a few take-home coding tests that were more interesting. One company had me implement a data structure I was not familiar with, so I got to learn about that. Another asked me to make specific changes (and any others that seemed necessary) in an existing codebase — a task much closer to what I’d likely be doing in an actual job.
Having also been on the hiring end of a JSON-to-TableView experience (it was not my choice of challenge, but I had no objection to it as I didn’t know how common it was at the time), I know how difficult it is to come up with ideas for such challenges, and I’m not sure what the solution is. I most enjoyed talking through problems in an interview, in pseudocode so there’s no pressure to remember the exact syntax without an IDE or documentation to help. This takes a clearly-defined amount of time, gives the interviewer a better idea of how I think, and gives me an idea of what it would be like to work with them. There’s also more immediate feedback, so I don’t waste time working on a detail they don’t care about, or just trying to convince myself that it’s good enough to submit. I realise that some people might find this more stressful than the take-home test, so ideally the companies would give the choice.
I am now at the point of my job search where I don’t think I’ll need to write any more JSON-to-TableView apps🤞🏻which is just as well, as I wouldn’t be inspired to do a great job of one.
My Poetry Show on JoCo Cruise 2021
Posted by Angela Brett in Performances on April 26, 2021
I’ve been going on the JoCo Cruise since the ‘shadow cruise‘ was just an iPhone handbell choir. As it developed into something people could book spaces and times for, and have on a schedule that packed 26 days of events into a week, I participated in a few friends‘ shadow events, but hesitated to run my own in case it conflicted with something else I really wanted to do, or had me nervous or practising instead of enjoying other events.
This year, the cruise went virtual, and my excuses went out the window. I registered to do a poetry show, promising that I would ‘recite some poems that rhyme, some that don’t, and maybe even sing a few things. Topics may include science, love, poop, and life.’ I came to realise I could not only read my poems from my screen to avoid any nervousness about remembering them, but I could also share my screen. There are projectors on the cruise, but they are in short supply, so I wouldn’t request one for just one or two poems in a shadow event. On the virtual cruise, I could share whatever I wanted, including things from the internet, which wouldn’t be reliably available on a ship. And I could use props that I wouldn’t bother to bring on a cruise. So I did! I made slides for poems that worked best with visual aids, I showed off my rhyming dictionary, and I closed with a cover song that requires a video. And of course, I recorded everything. Here’s my show!
I also performed a few poems at the open mic — hastily-adapted versions of a poem I wrote for the Vienna open mic Open Phil, and the one I opened my show with about the differences between the real cruise and the virtual one. Joey Marianer and Phil Conrad (who also hosts Open Phil) hosted the open mic, so the open mic videos are on Joey’s channel.
It sure was weird watching Joey upload videos, when usually I’m spending most of my free time from March to May processing videos from the cruise. On the subject of cruise videos, the videos of the official events will allegedly only be up until May 1, so watch them while you can!
My Fancy Pants on JoCo Cruise 2021
Posted by Angela Brett in News on April 16, 2021
I had some plans for my entry into the JoCo Cruise 2021 Fancy Pants Parade, but they involved being on an actual cruise ship. When it went virtual, I assumed there would be no parade. When the call for video submissions came on 16 March, with the deadline on 31 March, I was unprepared. I’m not shopping in-person, and I didn’t think I’d be able to order materials and make anything in time.
But as much as the virtual cruise makes it impossible to do some things we would do on the real cruise, it also makes it possible to do things we couldn’t do on the real cruise. In one in-person Fancy Pants Parade, there was a person in a motion capture suit holding a sign saying ‘we’ll fix it in post’, and also a person in a green screen suit (who was controlling the tentacles of their partner’s pants.) In a virtual Fancy Pants Parade, we really can fix it in post. So I decided to try using my pants as a green screen — for what, I wasn’t sure.
At first I thought I’d try with some black jeans and hope I could tune the green screen effect for them, but then I realised I actually had blue-green jeans (purchased purely because I was excited to find jeans that were the right length for me.) I paraded ridiculously across the room in them, and Final Cut Pro immediately recognised them as the colour to apply the green screen effect to.
I settled on showing footage from previous Fancy Pants Parades on my pants. At first I thought I’d use my own pants, to not steal anyone else’s glory, but I didn’t have footage of all my own pants. I went with the winning pants from each parade, making this sort of a restrospective — a celebration of the whole tradition of Fancy Pants Parades. As the live version of Mr. Fancy Pants often says, chances are you’re best in everybody’s pants.
After submitting my entry, I duplicated the footage, enabling different settings in each copy, to make this short step-by-step. I’ve never used a green screen effect before, so this was me learning as I went along.
I submitted my video on 21 March. On 30 March, the JoCo Cruise Home Office sent out an email saying they’d only received one submission so far, and Jonathan was “nigh-inconsolable” about it. So I encouraged some friends to submit some — as I mentioned in my last post, winning by default is not as much fun as winning by crushing the hopes and dreams of your friends. So here’s how the Fancy Pants Parade went. Watch it before reading the rest of the post if you don’t want the result spoiled:
There was a lively exploration of the problem space of pants. What is fancy? Does it modify ‘pants’, or ‘parade’? What are the most important components of being ‘best in terms of pants’: physical pants-crafting, presentation, or spirit? And is that fancy pants spirit, or we’ve-been-home-for-a-year spirit? Still, it seemed that at least the chat comments were mostly in my favour, until, in a shocking twist, they found Gina’s video, which had been accidentally left out of the parade. And hers, too, used some movie magic! More debate: Culture and history? Conception, or construction? All pants, no dance? If you are silent, the pants will speak. I put my pants on one leg at a time, but in four dimensions, somehow.
It came down to a vote, and… I won! But all the particiPANTS were winners.
This is my second win… as you might guess from this year’s video, I also won in 2014. I am not the first person to win twice — the 2016 winner had also won previously, I think in 2013.
Wake Up Gasping — an album!
Posted by Angela Brett in News, Performances, Publishing, Things To Listen To on April 8, 2021
Last year my friend Phil from SkyStudio Wien called me up out of the blue to ask if I wanted to record some poetry, so I did! I went in for another session later in the year, and that time I was more prepared — I gathered up everything I could find that I thought was good and made some kind of sense without too much explanation. We ended up with 39 poems recorded, so in order to bring the total up to 42, I added Why I Perform At Open Mics (previously released on Bandcamp as a single) and a few songs recorded in studios with Joey Marianer. It comes in at just under an hour — some of the tracks are very short #NanoRhymo poems. It’s called Wake Up Gasping.
A lot of these poems have been previously published on this blog in some form, but some haven’t. I included some poems I wrote before I started this blog (the oldest, Shooting Star, being from around 1996) and some I’d written more recently but which I’d only performed with sound effects (Negative Return, sometimes followed by Down while the noise was still trailing off) or just always thought would work better spoken than read (A Couple of Problems.)
The title comes from a line in A Skirmish [With My Least-Favourite Body Part] which I always thought would be a great name for a hard-hitting collection of powerful, emotional poetry. I do not think that’s what this is, but at least with 42 tracks, it looks like I was holding my breath for a while and finally let everything out.
The cover art is by Joseph Camann of The Camannwordsmith Patreon. I started out without much idea of what I wanted on the cover, which was great because his art is mostly abstract, but after looking through some of his existing art for ideas I thought of having the lost astronaut from Down floating through a colourful space-y background. Joseph has a lot going on: music, stories, paintings, poems (sometimes read to puppies), reaction videos, even wearable art, in case you’d like something like this album cover but on a dress.
Some of my tracks have unusual characters in the titles, and I’m happy to report that Bandcamp did not have problems with any of them.
In other news, about 48 hours from now, I’m doing a 50-minute poetry show over Zoom as part of the ‘Shadow Cruise’ of the virtual JoCo Cruise 2021. It will include some poems from the album, but also (thanks to screensharing) some which require or are enhanced by visual aids or additional explanations. I will also be singing a few songs, and reading one poem especially written for the event. Feel free to join — there’s no signup, ticket, or even pants required! As with most JoCo Cruise events I’ve been to over the years, I will post a recording of it on my YouTube channel later if you can’t make it.
Check out the rest of the cruise schedule, and the cruise Discord, too… this year’s cruise is obviously quite different from the usual one in many ways, but still hopefully similar in enough ways that you’ll get a feel for how much it influences my life. One important way it’s different is that it’s completely free and you don’t even have to get out of bed for it, let alone go to an airport and cruise port.
You should also see me participating for the eleventh year in a row in the Fancy Pants Parade. For a while, I was the only person to have submitted a video, but I encouraged some friends to (including some clients of Chromatic Verse Wearable Art, by the same person who designed my album cover) so that I wouldn’t just win by default. Now I can win by crushing the hopes and dreams of my friends! Later, I will post a short making-of video about the pants I appear in.
Getting Sick in the World of Health — Down the Rabbit Hole
Posted by Angela Brett in video on March 30, 2021
This weekend my friend Rob Lambert asked me to lend my vocal stylings to an animation he was making about his experience of suddenly getting sick. While my vocals are not nearly as stylish as his, I did indeed record my part — some scripted by Rob, some my own reactions to what he had to say. I think it turned out great; check it out!
I think this video is a good reminder of the second point in my Accessibility is for Everyone article. Learn to notice, appreciate, and contribute to the rabbit hole climbing harnesses around you before you need them.
If you want to see more from Rob, check out his LinkedIn or subscribe to his YouTube channel, which also has some cool CERN stuff. On the subject of LinkedIn, here’s mine! I’m currently looking for full-time or freelance work, and I’d love to work on something related to accessibility, or any of the other things I’ve enthused about or experimented with on this blog.
Collaborations: All on My Own (among others)
Posted by Angela Brett in News on March 17, 2021
This year’s MathsJam Annual Gathering was virtual, and rather than singing maths-related parody songs together at the MathsJam Jam, we were encouraged to send videos of ourselves singing them. Sam Hartburn, who has written many lyrics for MathsJam Jam songs, offered to write custom song lyrics for one of the participants. I don’t recall whether this was for the best submission or one chosen at random, but in any case, Joey Marianer got the prize for a cover of Jonathan Coulton’s Mandelbrot Set.
Joey considered giving the prize away, since I already sometimes write lyrics that Joey sings, but instead decided to commission a variation on They Might Not Be Giants, a poem I wrote about science education which Joey set to music. The new version is about someone who has many offers of help to solve a puzzle, but finds satisfaction in solving it on their own.
A while later, TikTok was awash with collaborations on the Wellerman sea shanty, and Daniel Litt wrote a parody of it about elliptic curves. 〈 Berger | Dillon 〉 did a duet with it, and Joey then sang harmony. My only contribution to this one was editing Joey’s video into the others’, since we don’t have TikTok to do it for us. Neither of us knows much about what it’s about, but I bet many of the Wellerman singers don’t know much about the Weller brothers or tonguing either.
We won’t be putting to sea this year, of course, but the 2021 JoCo Cruise is free and virtual, and I am finally going to run a poetry show as a shadow event. Come join us!
I’m excited to discover a more recent viral TikTok is singing a sped-up version of Mike Phirman’s Chicken Monkey Duck! I’m not cool enough to be on TikTok, so I made sure to learn that song before it was cool, just so I wouldn’t surpass my coolness quota. Here’s a playlist of me singing Chicken Monkey Duck, some diagrams I made of the song, and an rtf of it using colours from my personal grapheme–colour synaesthesia, created using an app I wrote a while ago. And for completeness, here’s the Spanish version of it, Pollo Mono Pato, which I think is a bit harder to learn due to all the words having the same number of syllables.
On the subject of Mike Phirman, he’s just released a new album called Activity Books, and it’s great. I’m consistently impressed by how many of his songs do things that songs have rarely or never done before. For instance, Color by Number can probably detect grapheme–colour synaesthesia in young children, by causing them to throw tantrums about the incorrect colour associations. ‘Word Search / Vacuum’ makes me wish there were an alphabet song of the entire International Phonetic Alphabet.
In unrelated news, a while ago I requested a cover of K’s Choice’s song ‘America’ on the CamannWordsmith patreon. That Patreon post has now been made public. The track is also available on the brand new CamannWordsmith Bandcamp page, along with a whole lot of other covers that you can download for free. To bring this back around to relatedness again… CamannWordsmith and I are collaborating on something; watch this space to find out what!
Accessibility is for Everyone
Posted by Angela Brett in Culture, News on February 26, 2021
Accessibility is for everyone. I say that whenever an abled person finds a way that an accessibility feature benefits them. But that’s not all that it means. There are really three different meanings to that phrase:
- Accessibility exists to make things accessible to everyone.
- At some point, everyone has some kind of impairment which accessibility can help them with.
- Changes that make things more accessible can be useful, convenient, or just plain fun, even for people who are 100% unimpaired.
Is this article for everyone?
This is a bare-bones outline of ways accessibility is for everyone, with a few lists of examples from my personal experience, and not much prose. This topic is fractal, though, and like a Koch Snowflake, even its outline could extend to infinite length. I’ve linked to more in-depth references where I knew of them, but tried not to go too far into detail on how to make things accessible. There are much better references for that — let me know of the ones you like in the comments.
I am not everyone
Although I do face mobility challenges in the physical world, as a software developer, I know the most about accessibility as it applies to computers. Within that, I have most experience with text-to-speech, so a lot of the examples relate to that. I welcome comments on aspects I missed. I am not an expert on accessibility, but I’d like to be.
The accessibility challenges that affect me the most are:
- A lack of fluency in the language of the country I live in
- Being short (This sounds harmless, but I once burnt my finger slightly because my microwave is mounted above my line of sight.)
- Cerebral palsy spastic diplegia
That last thing does not actually affect how I use computers very much, but it is the reason I’ve had experience with modern computers from a young age.
Accessibility makes things accessible to everyone
Accessibility is for everyone — it allows everyone to use or take part in something, not just people with a certain range of abilities. This is the real goal of accessibility, and this alone is enough to justify improving accessibility. The later points in this article might help to convince people to allocate resources to accessibility, but always keep this goal in mind.
Ideally, everyone should be able to use a product without asking for special accommodations. If not, there should be a plan to accommodate those who ask, when possible. At the very least, nobody should be made to feel like they’re being too demanding just for asking for the same level of access other people get by default. Accessibility is not a feature — lack of accessibility is a bug.
Don’t make people ask
If some people have to ask questions when others don’t, the product is already less accessible to them — even if you can provide everything they ask for. This applies in a few scenarios:
- Asking for help to use the product (e.g. help getting into a building, or using a app)
- Asking for help accessing the accessibility accommodations. For example, asking for the key for an elevator, or needing someone else to configure the accessibility settings in software. Apple does a great job of this by asking about accessibility needs, with the relevant options turned on, during installation of macOS.
- Asking about the accommodations available to find out if something is accessible to them before wasting time, spoons, or money on it. Make this information publicly available, e.g. on the website of your venue or event, or in your app’s description. Here’s a guide on writing good accessibility information.
Asking takes time and effort, and it can be difficult and embarrassing, whether because someone has to ask many times a day, or because they don’t usually need help and don’t like acknowledging when they do.
In software, ‘making people ask’ is making them set up accessibility in your app when they’ve already configured the accessibility accommodations they need in the operating system. Use the system settings, rather than having your own settings for font size, dark mode, and so on. If the user has to find your extra settings before they can even use your app, there’s a good chance they won’t. Use system components as much as possible, and they’ll respect accessibility options you don’t even know about.
If they ask, have an answer
Perhaps you don’t have the resources to provide certain accommodations to everyone automatically, or it doesn’t make sense to. In that case:
- make it clear what is available.
- make asking for it as easy as possible (e.g. a checkbox or text field on a booking form, rather than instructions to call somebody)
- make an effort to provide whatever it is to those who ask for it.
Assume the person really does need what they’re asking for — they know their situation better than you do.
If the answer is ‘no, sorry’, be compassionate about it
If you can’t make something accessible to a given group of people, don’t feel bad; we all have our limitations. But don’t make those people feel bad either — they have their limitations too, and they’re the ones missing out on something because of it. Remember that they’re only asking for the same thing everyone else gets automatically — they didn’t choose to need help just to annoy you.
If you simply didn’t think about their particular situation, talk with them about steps you could take. Don’t assume you know what they can or can’t do, or what will help them.
Everyone can be impaired
Accessibility is for everyone. But just like how even though all lives matter it is unfortunately still necessary to remind some people that black lives do, to achieve accessibility for everyone, we need to focus on the people who don’t get it by default. So who are they?
Apple’s human interface guidelines for accessibility say this better than I could:
Approximately one in seven people worldwide have a disability or impairment that affects the way they interact with the world and their devices. People can experience impairments at any age, for any duration, and at varying levels of severity. Situational impairments — temporary conditions such as driving a car, hiking on a bright day, or studying in a quiet library — can affect the way almost everyone interacts with their devices at various times.
Almost everyone.
This section will mostly focus on accessibility of devices such as computers, tablets, and phones. It’s what I know best, and malfunctioning hardware can be another source of impairment. Even if you don’t consider yourself disabled, if you haven’t looked through the accessibility settings of your devices yet, do so — you’re sure to find something that will be useful to you in some situations. I’ll list some ways accessibility can help with hardware issues and other situational impairments below.
Apple defines four main kinds of impairment:
Vision
There’s a big gap between someone with 20/20 full-colour vision in a well-lit room looking at an appropriately-sized, undamaged screen, and someone with no vision whatsoever. There’s even a big gap between someone who is legally blind and someone with no vision whatsoever. Whenever we are not at the most abled end of that spectrum, visual accessibility tools can help.
Here are some situations where I’ve used Vision accessibility settings to overcome purely situational impairments:
- When sharing a screen over a videoconference or to a projector, use screen zoom, and large cursor or font sizes. On macOS when using a projector, you can also use Hover Text, however this does not show up when screensharing over a videoconference. This makes things visible to the audience regardless of the size of their videoconference window or how far they are from the projector screen.
- When an internet connection is slow, or you don’t want to load potential tracking images in emails, image descriptions (alt text) let you know what you’re missing.
- When a monitor doesn’t work until the necessary software is installed and configured, use a screenreader to get through the setup. I’ve done this on a Mac, after looking up how to use VoiceOver on another device.
Hearing
There’s a big gap between someone with perfect hearing and auditory processing using good speakers at a reasonable volume in an otherwise-quiet room, and someone who hears nothing at all. There’s even a big gap between someone who is Deaf and someone who hears nothing at all. Whenever we are not at the most abled end of that spectrum, hearing accessibility tools can help.
Here are some situations where I’ve used Hearing accessibility settings when the environment or hardware was the only barrier:
- When one speaker is faulty, change the panning settings to only play in the working speaker, and turn on ‘Play stereo audio as mono’.
- When a room is noisy or you don’t want to disturb others with sound, use closed captions.
Physical and Motor
There’s a big gap between someone with a full range of controlled, pain-free movement using a perfectly-functioning device, in an environment tailored to their body size, and someone who can only voluntarily twitch a single cheek muscle (sorry, but we can’t all be Stephen Hawking.) Whenever we are not at the most abled end of that spectrum, motor accessibility tools can help.
Here are some situations where you can use Physical and Motor accessibility to overcome purely situational impairments:
- When a physical button on an iPhone doesn’t work reliably, use Back Tap, Custom Gestures, or the AssistiveTouch button to take over its function.
- When you’re carrying something bulky, use an elevator. I’ve shared elevators with people who have strollers, small dogs, bicycles, suitcases, large purchases, and disabilities. I’ve also been yelled at by someone who didn’t think I should use an elevator, because unlike him, I had no suitcase. Don’t be that person.
Literacy and Learning
This one is also called Cognitive. There’s a big gap between an alert, literate, neurotypical adult of average intelligence with knowledge of the relevant environment and language, and… perhaps you’ve thought of a disliked public figure you’d claim is on the other end of this spectrum. There’s even a big gap between that person and the other end of this spectrum, and people in that gap don’t deserve to be compared to whomever you dislike. Whenever we are not at the most abled end of that spectrum, cognitive accessibility considerations can help.
Here are some situations where I’ve used accessibility when the environment was the only barrier to literacy:
- When watching or listening to content in a language you know but are not fluent in, use closed captions or transcripts to help you work out what the words are, and find out the spelling to look them up.
- When reading in a language you know but are not fluent in, use text-to-speech in that language to find out how the words are pronounced.
- When consuming content in a language you don’t know, use subtitles or translations.
Accessibility features benefit abled people
Sometimes it’s hard to say what was created for the sake of accessibility and what wasn’t. Sometimes products for the general public bring in the funding needed to improve assistive technologies. Here are some widely-used things which have an accessibility aspect:
- The Segway was based on self-balancing technology originally developed for wheelchairs. Segways and the like are still used by some people as mobility devices, even if they are not always recognised as such.
- Voice assistants such as Siri rely on speech recognition and speech synthesis technology that has applications in all four domains of accessibility mentioned above.
- Light or Dark mode may be a style choice for one person and an essential visual accessibility tool for another.
Other technology is more strongly associated with accessibility. Even when your body, your devices, or your environment don’t present any relevant impairment, there are still ways that these things can be useful, convenient, or just plain fun.
Useful
Some accessibility accommodations let abled people do things they couldn’t do otherwise.
- Transcripts, closed captions, and image descriptions are easily searchable.
- I’ve used text-to-speech APIs to generate the initial rhyme database for my rhyming dictionary, rhyme.science
- I’ve used text-to-speech to find out how words are pronounced in different languages and accents.
- Menstruators can use handbasins in accessible restroom stalls to rinse out menstrual cups in privacy. (This is not an argument for using accessible stalls when you don’t need them — it’s an argument for more handbasins installed in stalls!)
Convenient
Some accessibility tech lets abled people do things they would be able to do without it, but in a more convenient way.
- People who don’t like switching between keyboard and mouse can enable full keyboard access on macOS to tab through all controls. They can also use keyboard shortcuts.
- People who don’t want to watch an entire video to find out a piece of information can quickly skim a transcript.
- I’ve used speak announcements on my Mac for decades. If my Mac announces something while I’m on the other side of the room, I know whether I need to get up and do something about it.
- Meeting attendees could edit automatic transcripts from videoconferencing software (e.g. Live Transcription in Zoom) to make meeting minutes.
- I’ve used text-to-speech on macOS and iOS to speak the names of emojis when I wasn’t sure what they were.
- Pre-chopped produce and other prepared foods save time even for people who have the dexterity and executive function to prepare them themselves.
Fun
Some accessibility tech lets us do things that are not exactly useful, but a lot of fun.
- Hosts of the Lingthusiasm podcast, Lauren Gawne and Gretchen McCulloch, along with Janelle Shane, fed transcripts of their podcasts into an artificial intelligence to generate a quirky script for a new episode, and then recorded that script.
- I’ve used text-to-speech to sing songs I wrote that I was too shy to sing myself.
- I’ve used text-to-speech APIs to detect haiku in any text.
- Automated captions of video conferencing software and videos make amusing mistakes that can make any virtual party more fun. Once you finish laughing, make sure anyone who needed the captions knows what was really said.
- I may have used the ’say’ command on a server through an ssh connection to surprise and confuse co-workers in another room. 😏
- I find stairs much more accessible if they have a handrail. You might find it much more fun to slide down the balustrade. 😁
Advocating accessibility is for everyone
I hope you’ve learnt something about how or why to improve accessibility, or found out ways accessibility can improve your own life. I’d like to learn something too, so put your own ideas or resources in the comments!
NiceWriter: Artificially sweeten your text
Posted by Angela Brett in NastyWriter on February 10, 2021

A few years ago I noticed a linguistic habit of Twitter user Donald Trump, and decided to emulate it by writing an app that automatically adds insults before nouns — NastyWriter. But he’s not on Twitter any more, and Valentine’s Day is coming up, so it’s time to make things nicer instead.
My new iOS app, NiceWriter, automatically adds positive adjectives, highlighted in pink, before the nouns in any text entered. Most features are the same as in NastyWriter:
- You can use the contextual menu or the toolbar to change or remove any adjectives that don’t fit the context.
- You can share the sweetened text as an image similar to the one in this post.
- You can set up the ‘Give Me a Compliment’ Siri Shortcut to ask for a random compliment at any time, or create a shortcut to add compliments to text you’ve entered previously. You can even use the Niceify shortcut in the Shortcuts app to add compliments to text that comes from another Siri action.
- If you copy and paste text between NiceWriter and NastyWriter, the app you paste into will replace the automatically-generated adjectives with its own, and remember which nouns you removed the adjectives from.
The app is free to download, and will show ads unless you buy an in-app purchase to remove them. I’ve made NiceWriter available to run on M1 Macs as well, though I don’t have one to test it on, so I can’t guarantee it will work well.
I’ll post occasional Niceified text on the NastyWriter Tumblr, and the @NiceWriterApp Twitter.
NastyWriter 2.1
In the process of creating NiceWriter, I made a few improvements to NastyWriter — notably adding input and output parameters to its Siri Shortcut so you can set up a workflow to nastify the results of other Siri Shortcuts, and then pass them on to other actions. I also added four new insults, and fixed a few bugs. All of these changes are in NastyWriter 2.1.
That’s all you really need to know, but for more details on how I chose the adjectives for NiceWriter and what I plan to do next, read on.
Read the rest of this entry »-
You are currently browsing the archives for the year 2021

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported License.
Please tell me if you do something cool with it.

